深色模式
调优案例
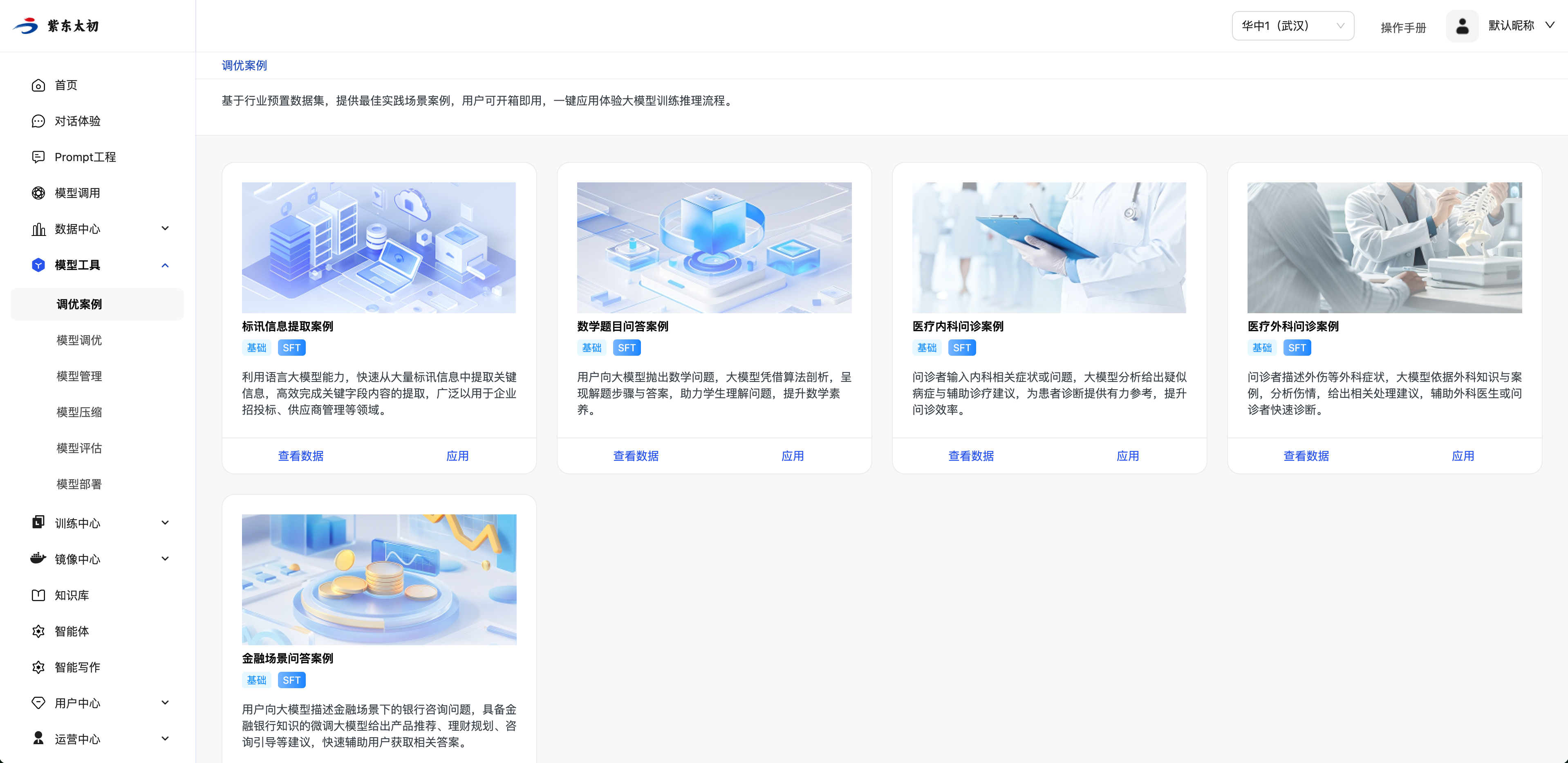
基于不同的行业场景展示大模型训练推理实践案例,提供大模型训练推理全链路的快速体验。系统预置行业数据集和训练配置,用户开箱即用。
案例应用
点击案例卡片“应用”按钮,进入调优任务的创建页面,任务配置已预先设定,用户可一键创建调优任务,亦可根据需要调整相应配置。
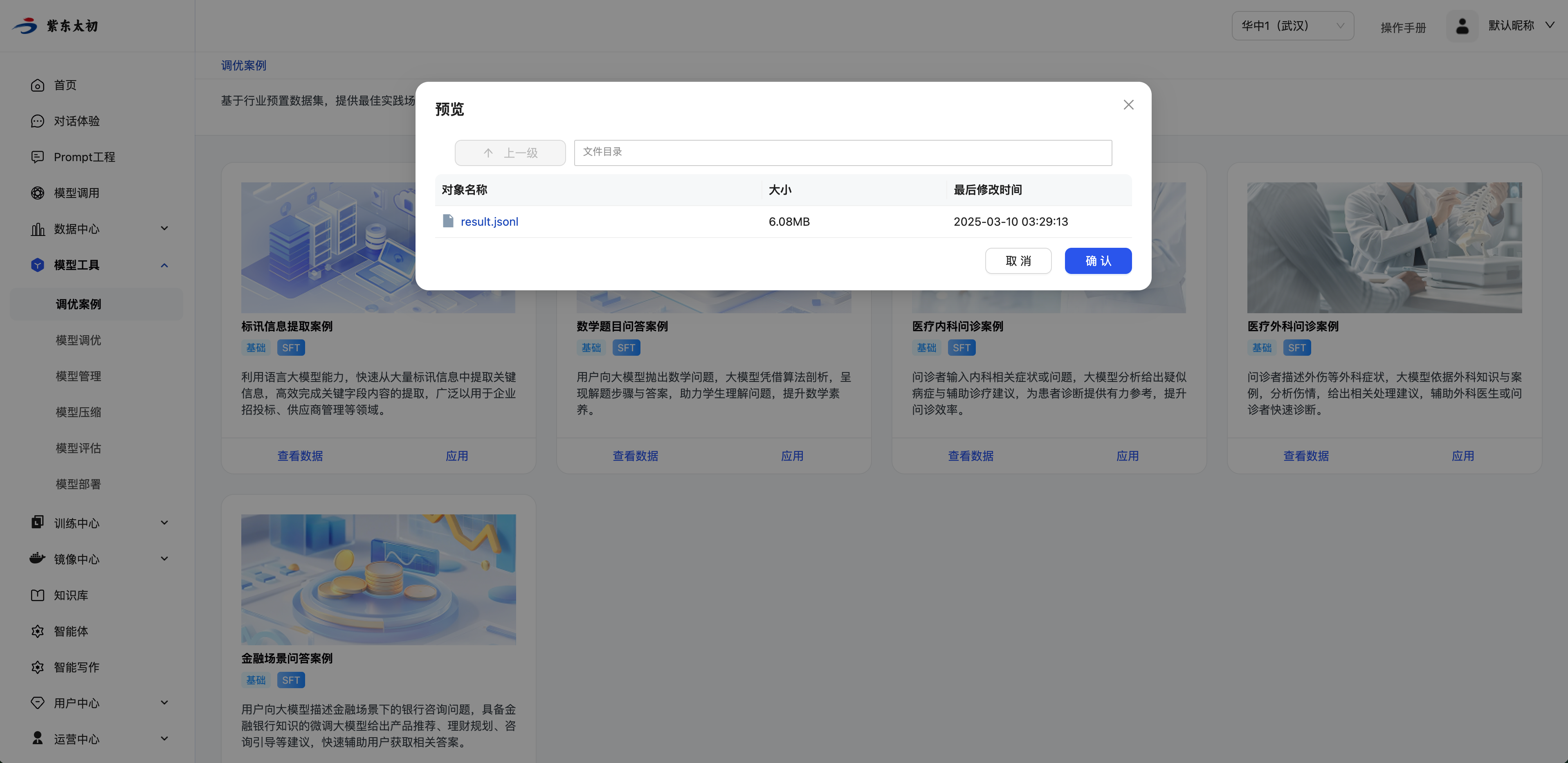
查看调优案例数据
点击案例卡片“查看数据”按钮,弹出数据预览弹窗。点击数据名称可将调优数据集下载到本地查看。
模型调优
增量预训练
增量预训练是一种预训练的模型训练方法。在本平台中,我们需要先对泛文本段落数据进行预训练,得到一个强大的通用语言模型。然后,在此预训练模型的基础上进行微调,调整部分参数后,得到一个更强大的场景模型。

创建任务
在增量预训练任务管理页面,选择“新建任务”按钮,然后,可根据训练任务基本信息、训练任务的参数配置、训练所需数据配置、训练任务资源配置即可创建增量预训练任务。
基本信息
填写好作业名称,选择训练需要的基础模型和模型版本。
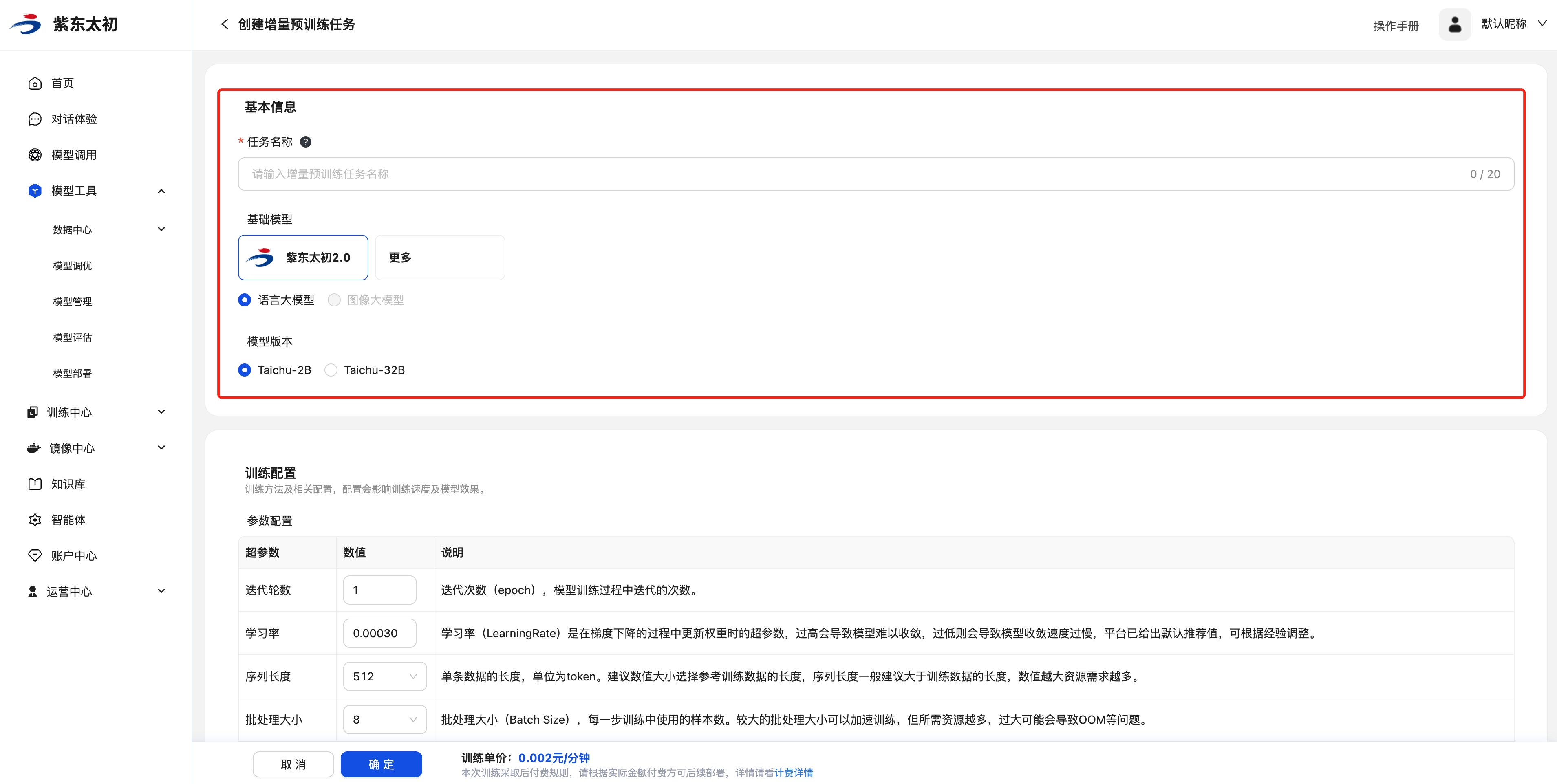
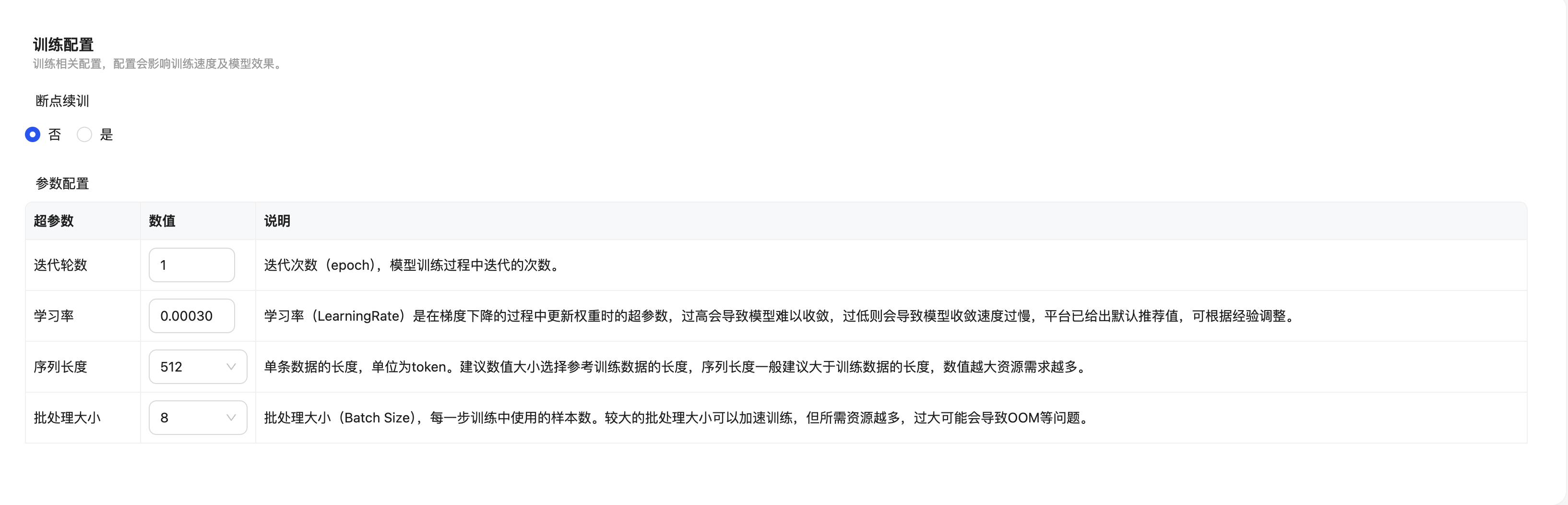
训练配置
训练配置是配置模型增量预训练的参数,主要包括迭代轮数、学习率、序列长度、批处理大小,系统会根据不同的模型设置不同的默认值,可按需调整。
| 超参数 | 参数说明 |
| 迭代轮数 | 迭代次数(epoch),模型训练过程中迭代的次数。 |
| 学习率 | 学习率(LearningRate)是在梯度下降的过程中更新权重时的超参数,过高会导致模型难以收敛,过低则会导致模型收敛速度过慢,平台已给出默认推荐值,可根据经验调整。 |
| 序列长度 | 单条数据的长度,单位为token。建议数值大小选择参考训练数据的长度,序列长度一般建议大于训练数据的长度,数值越大资源需求越多。 |
| 批处理大小 | 批处理大小(Batch Size),每一步训练中使用的样本数。较大的批处理大小可以加速训练,但所需资源越多,过大可能会导致OOM等问题。 |
断点续训支持在主动或被动终止任务的情况下,从断点前保存的模型/权重继续训练。选项默认为否,使用断点续训会增加模型训练时长和存储空间占用。
| 任务终止情况 | 说明 |
| 主动终止 | 手动停止任务。 |
| 被动终止 | 因为训练过程中通信、机器故障等异常导致的任务中断。 |
数据配置
增量预训练任务选择训练数据以及混合训练数据配比操作,增量预训练任务需要匹配文本段落的数据集,即数据集标签为用于预训练的数据。
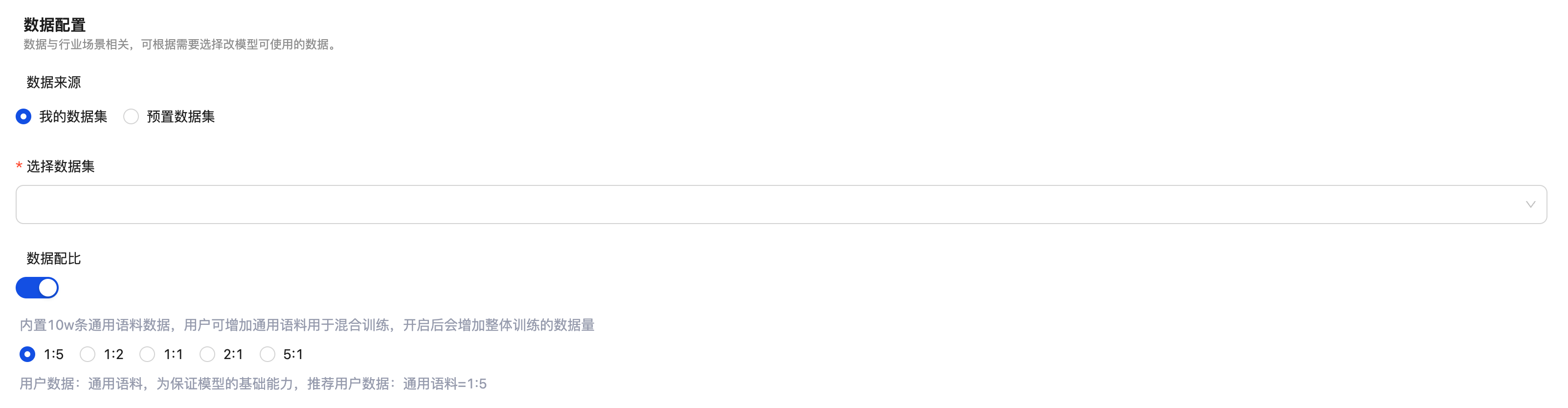
数据集来源可以为平台中已发布的数据集版本或预置的数据集,如果平台中没有您准备好的增量预训练数据,您需要先创建数据集,并导入满足要求的增量预训练数据。
数据配比为系统中预置的通用语料数据,开启数据配比后选择需要的配置比例,系统会自动加入预置的通用语料数据与您选择的数据一起混合训练。
资源配置
资源配置中您需要选择训练所需的资源类型、资源规格,可根据系统推荐值创建增量训练任务或按需调整。

训练时长预估
在完成训练、数据、资源配置后,系统自动计算增量预训练任务的时长区间

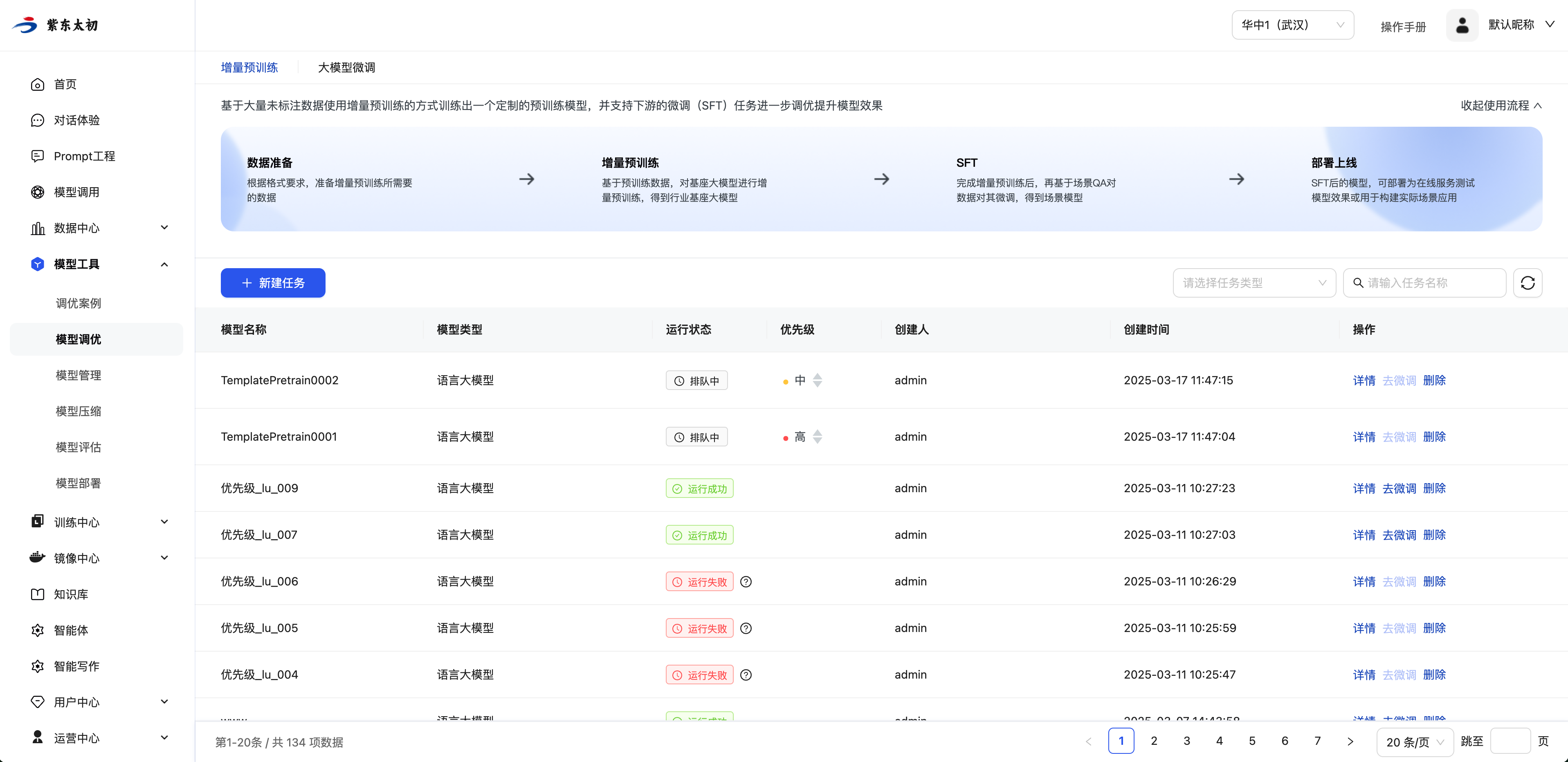
查看与管理增量预训练任务
在增量预训练任务管理页面,可以点击操作栏查看任务详情、新建微调任务和删除增量预训练任务,删除任务需要二次确认。
调整排队中任务优先级
排队中任务的优先级有“高”、“中”、“低”三个等级。在资源紧张的情况下,优先级较高的任务会优先被分配资源。用户可根据需要调整排队中任务的优先级。点击优先级栏的上箭头,任务优先级上调一级;点击下箭头则下调一级。
详情
点击增量预训练任务列表操作栏中“详情”按钮,即可进入增量预训练任务的详情页,查看其详情内容。在任务详情页会展示创建任务时填写的基础信息、训练配置、数据配置、资源配置以及训练任务产生的日志、服务事件、评估报告和资源监控。
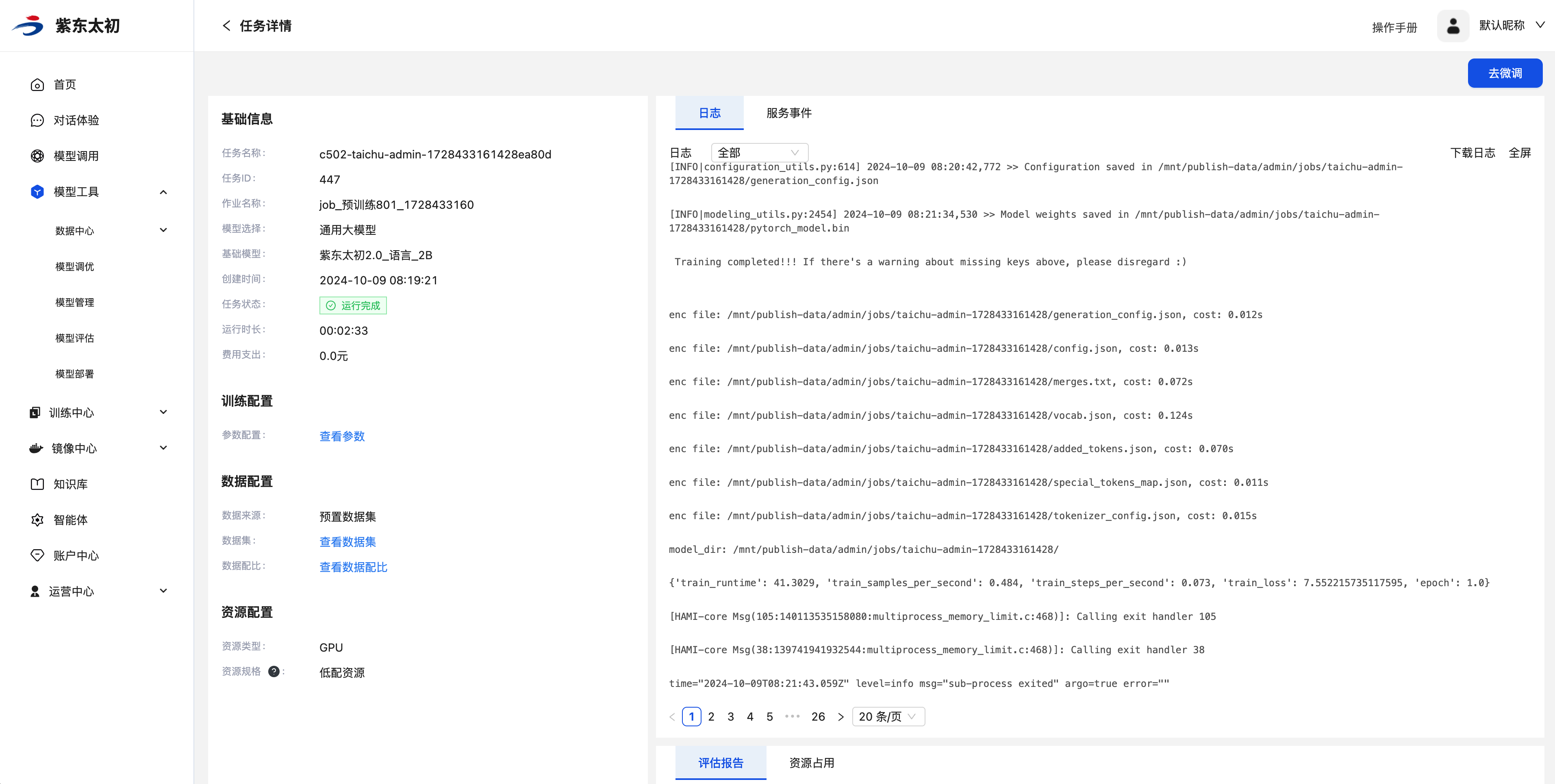
基础信息中会增加展示当前任务的ID、作业名称、运行时长、费用等信息。训练配置的参数信息,数据配置的数据集、数据配比均支持点击查看具体内容,日志为当前任务训练过程中产生的日志内容,支持下载或全屏展示。
服务事件会记录当前增量预训练任务从创建任务、开始调度、开始训练、训练结束全过程的事件信息。

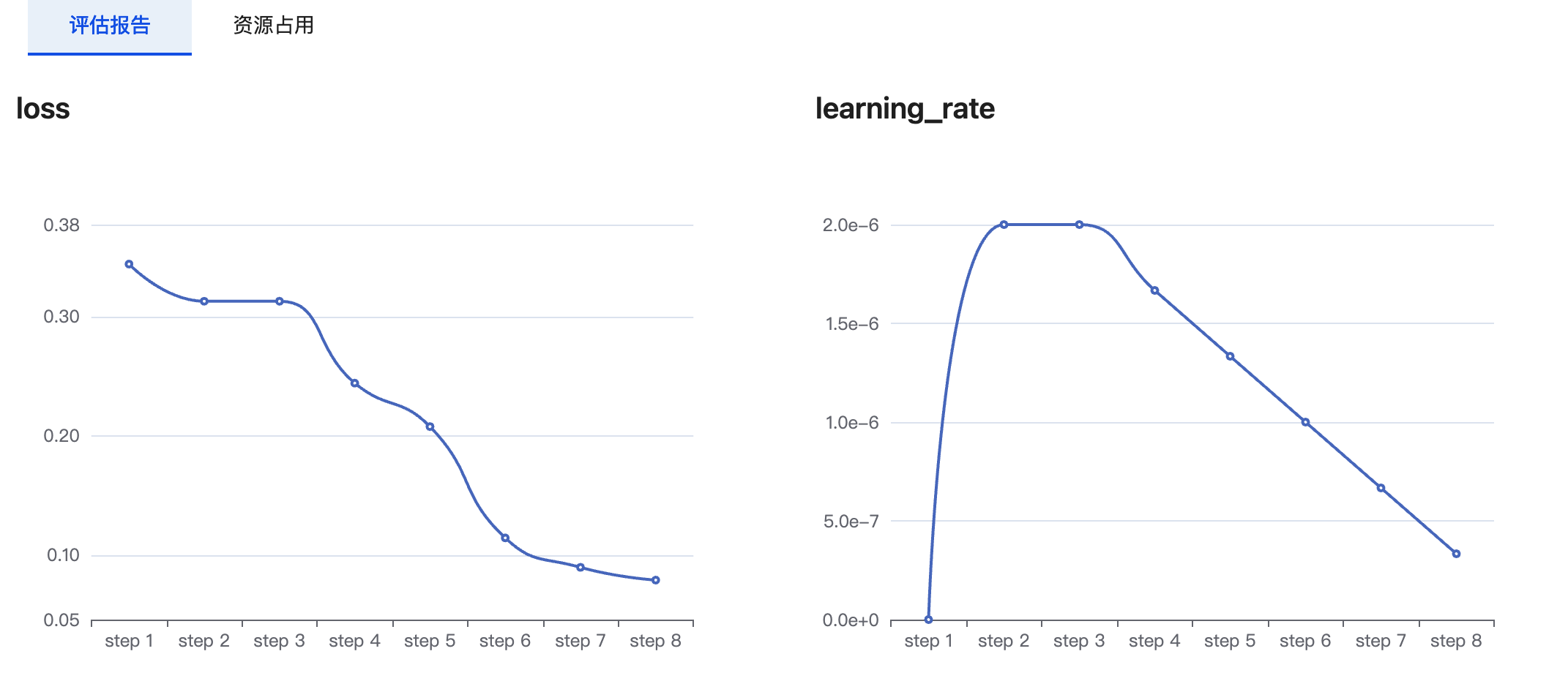
评估报告会展示训练过程中的loss值、learning_rate参数的实时变化。
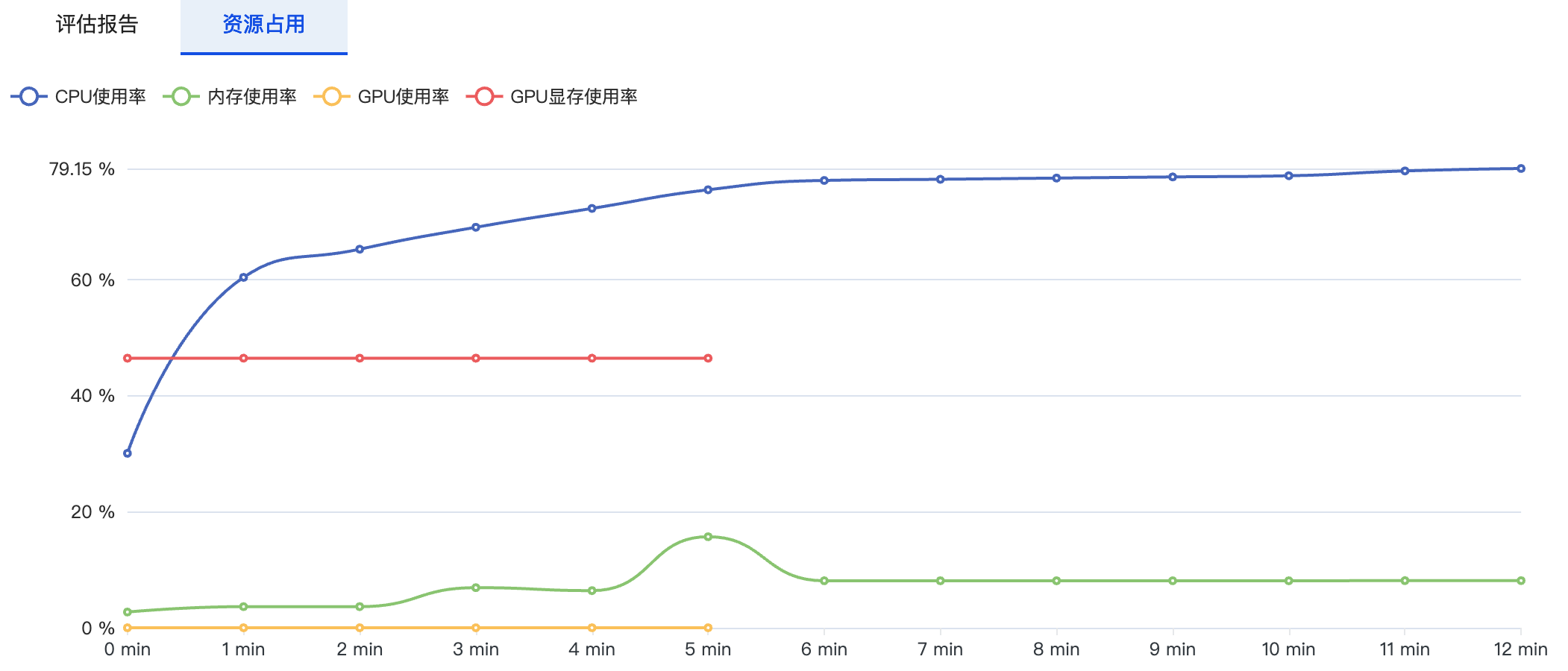
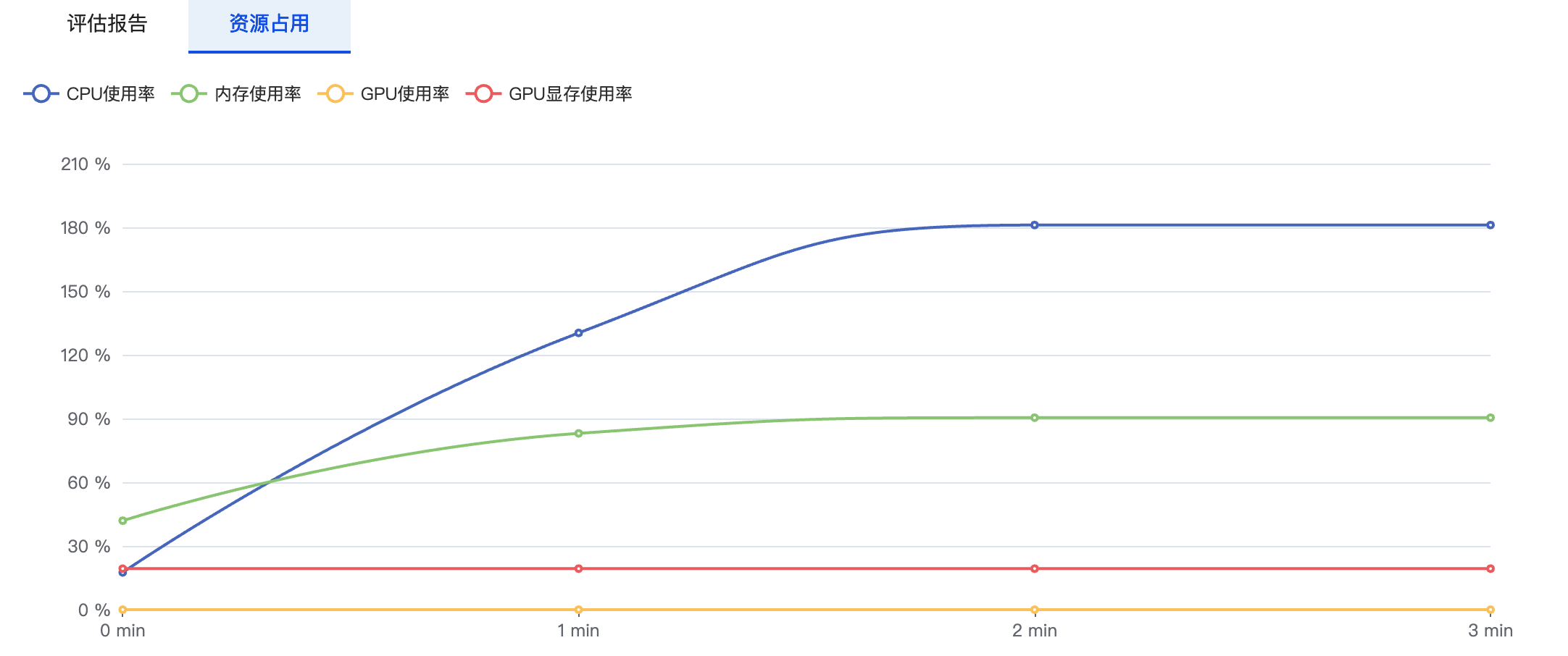
资源占用则会记录当前任务训练过程中CPU、内存、GPU等资源的使用情况。
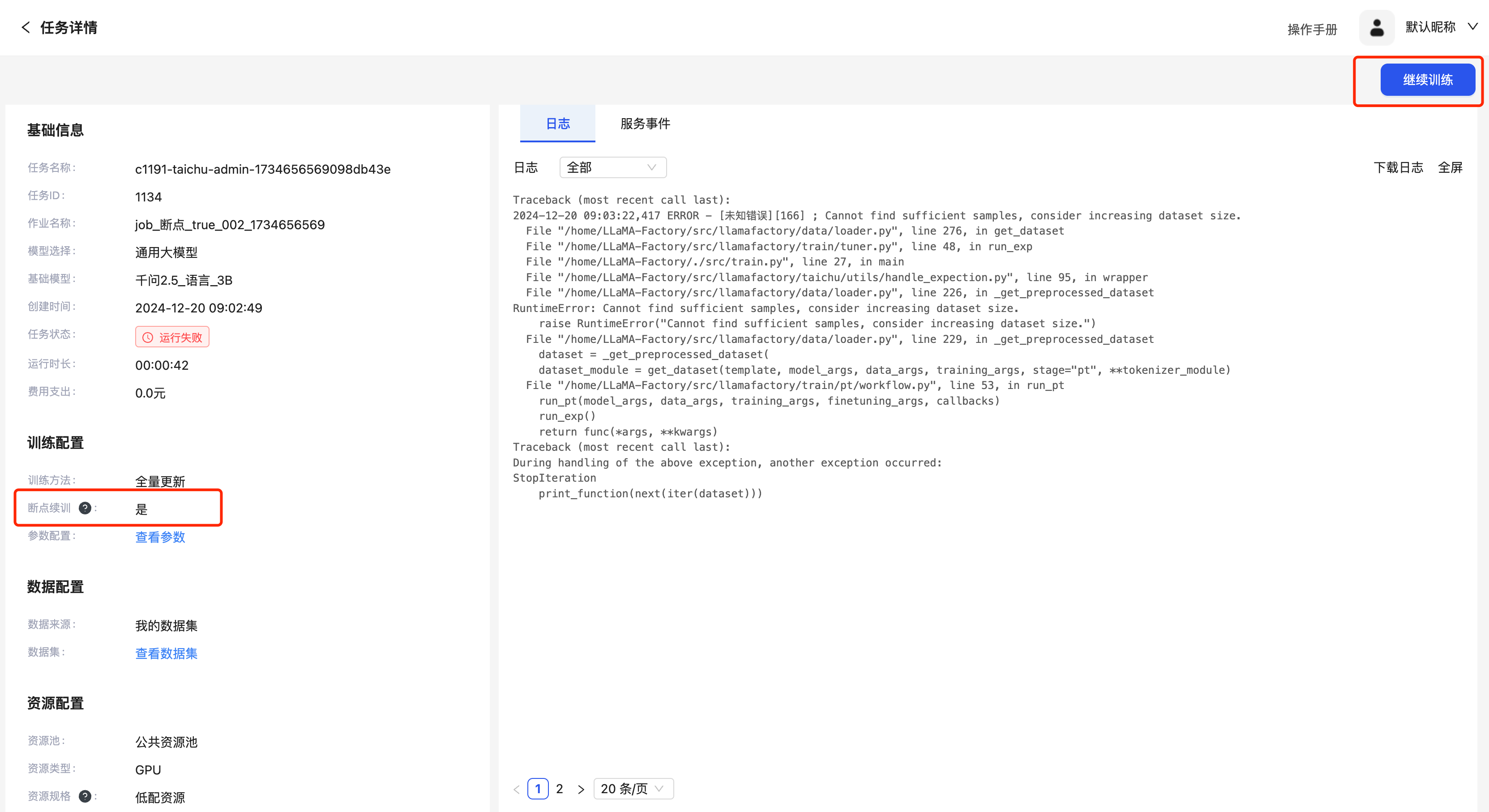
断点续训
如果任务选择了“断点续训”,已中止的任务可以在任务详情页重新拉起训练
去微调与删除
点击增量预训练任务列表操作栏中“去微调”操作,即可跳转至创建微调任务的页面,并将当前增量预训练任务得到的模型作为基础模型选项,您可以基于当前基础模型创建微调任务。
点击增量预训练任务列表操作栏中“删除”操作,弹框二次确认即可删除当前增量预训练任务以及任务生成的模型文件。
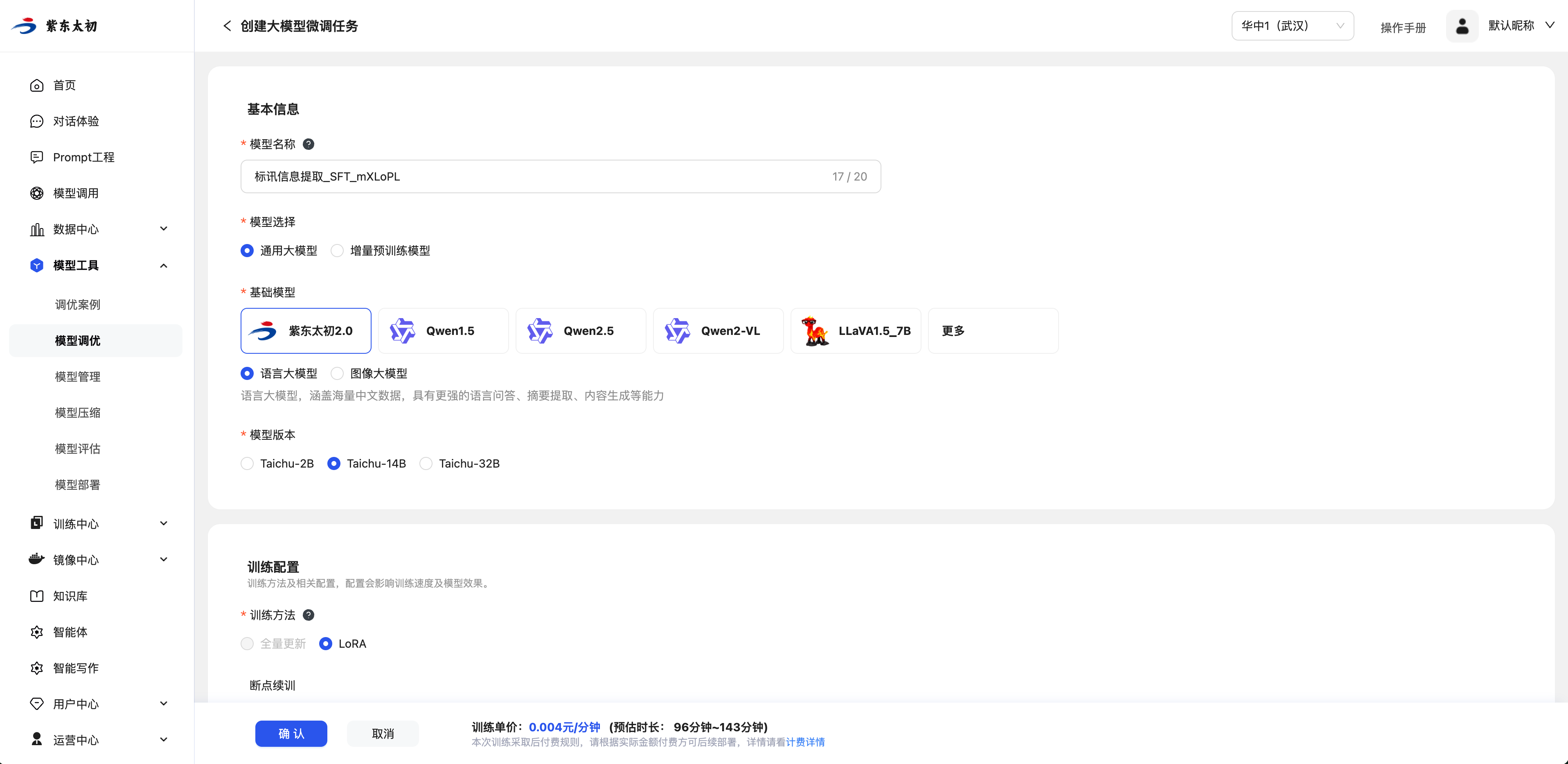
大模型微调
大模型微调是Fine-Tuning的训练模式,您可以选择您需要的基础模型、准备好的微调数据集创建微调任务,从而创建场景所需的模型,并根据需要选择是否部署该模型。

创建任务
在大模型微调任务管理页面,选择“新建任务”按钮,然后,可根据训练任务基本信息、训练任务的参数配置、训练所需数据配置、训练任务资源配置即可创建大模型微调任务。
基本信息
填写好作业名称,选择通用大模型或增量预训练的模型来源,再选择训练需要的基础模型和模型版本。
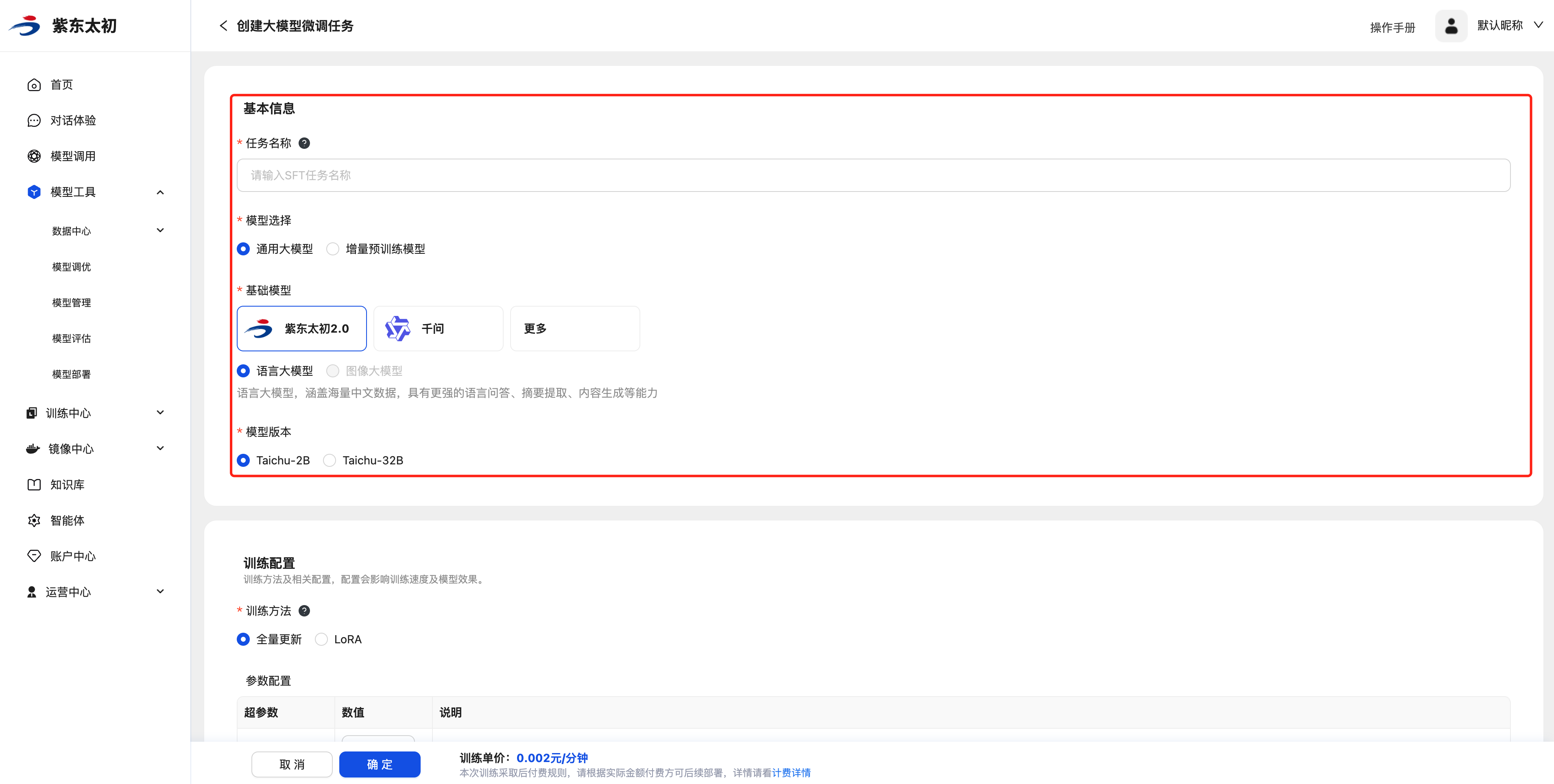
训练配置
训练配置是配置大模型微调的参数,包括训练方法和微调参数。
训练方法区分全量更新与LoRA微调。
| 训练方法 | 说明 |
| 全量更新 | 全量更新在训练过程中对大模型的全部参数进行更新,可以充分利用训练数据,有潜力在新任务上达到更好的性能。 |
| LoRA | LoRA在训练过程中只更新低秩部分的参数,需要的计算资源更少,训练过程更快,可以减少过拟合的风险。 |
断点续训支持在主动或被动终止任务的情况下,从断点前保存的模型/权重继续训练。选项默认为否,使用断点续训会增加模型训练时长和存储空间占用。
| 任务终止情况 | 说明 |
| 主动终止 | 手动停止任务。 |
| 被动终止 | 因为训练过程中通信、机器故障等异常导致的任务中断。 |
参数配置主要包括迭代轮数、学习率、序列长度、批处理大小,系统会根据不同的模型设置不同的默认值,可按需调整。
| 超参数 | 参数说明 |
| 迭代轮数 | 迭代次数(epoch),模型训练过程中迭代的次数。 |
| 学习率 | 学习率(LearningRate)是在梯度下降的过程中更新权重时的超参数,过高会导致模型难以收敛,过低则会导致模型收敛速度过慢,平台已给出默认推荐值,可根据经验调整。 |
| 序列长度 | 单条数据的长度,单位为token。建议数值大小选择参考训练数据的长度,序列长度一般建议大于训练数据的长度,数值越大资源需求越多。 |
| 批处理大小 | 批处理大小(Batch Size),每一步训练中使用的样本数。较大的批处理大小可以加速训练,但所需资源越多,过大可能会导致OOM等问题。 |
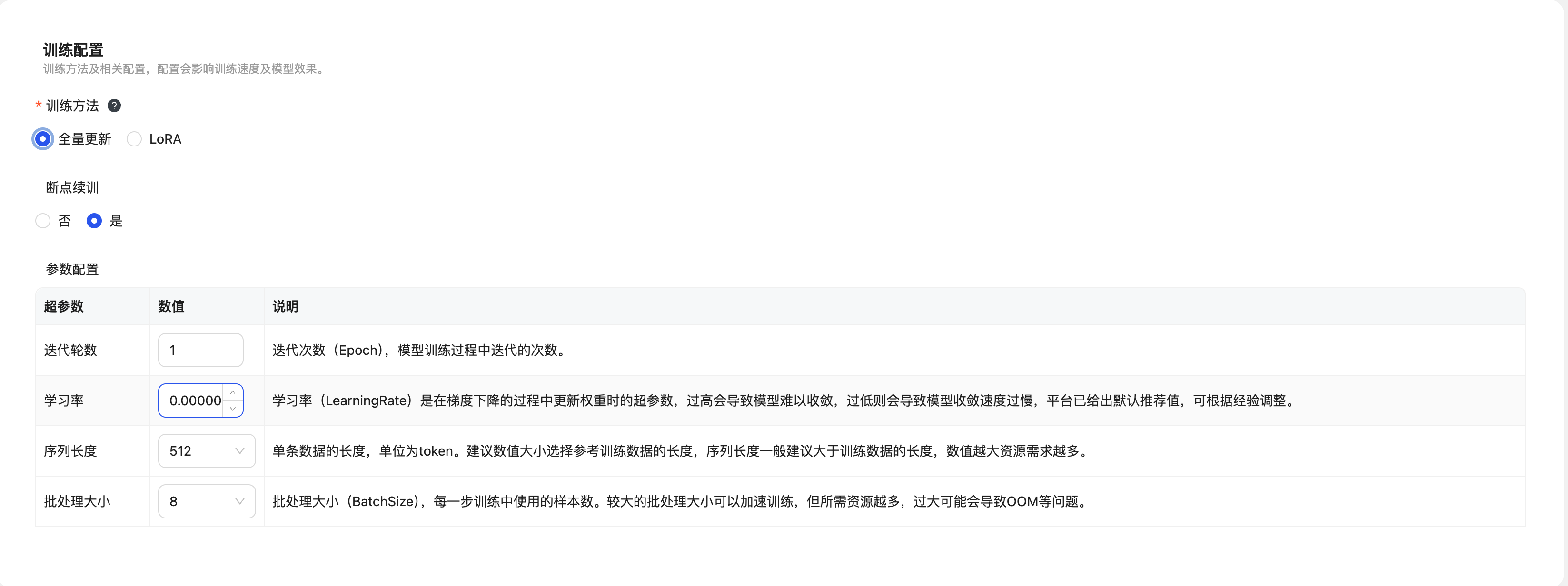
数据配置
大模型微调任务选择训练数据以及混合训练数据配比操作,大模型微调任务需要匹配文本问答的数据集,即数据集标签为用于微调的数据。
数据集来源可以为平台中已发布的数据集版本或预置的数据集,如果平台中没有您准备好的微调数据,您需要先创建数据集,并导入满足要求的微调数据。
数据配比为系统中预置的通用语料数据,开启数据配比后选择需要的配置比例,系统会自动加入预置的通用语料数据与您选择的数据一起混合训练。
资源配置
资源配置中您需要选择训练所需的资源类型、资源规格,可根据系统推荐值创建增量训练任务或按需调整。
训练时长预估
在完成训练、数据、资源配置后,系统自动计算微调任务的时长区间

查看与管理微调任务
在大模型微调任务管理页面,可以点击操作栏查看任务详情和删除大模型微调任务,删除任务需要二次确认。
调整排队中任务优先级
排队中任务的优先级有“高”、“中”、“低”三个等级。在资源紧张的情况下,优先级较高的任务会优先被分配资源。用户可根据需要调整排队中任务的优先级。点击优先级栏的上箭头,任务优先级上调一级;点击下箭头则下调一级。
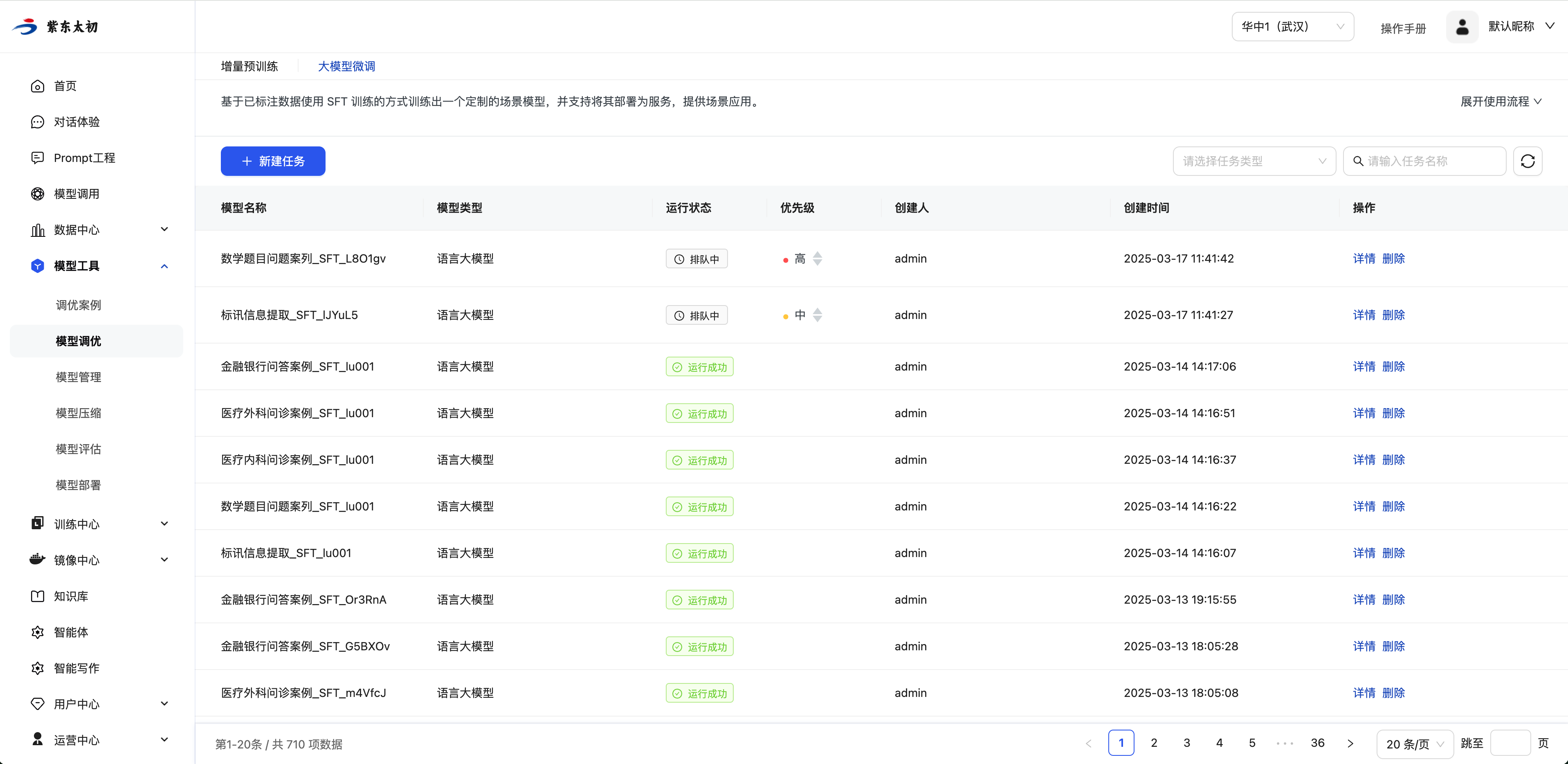
任务详情
点击大模型微调任务列表操作栏中“详情”按钮,即可进入大模型微调任务的详情页,查看其详情内容。在任务详情页会展示创建任务时填写的基础信息、训练配置、数据配置、资源配置以及训练任务的日志、服务事件、评估报告和资源监控。
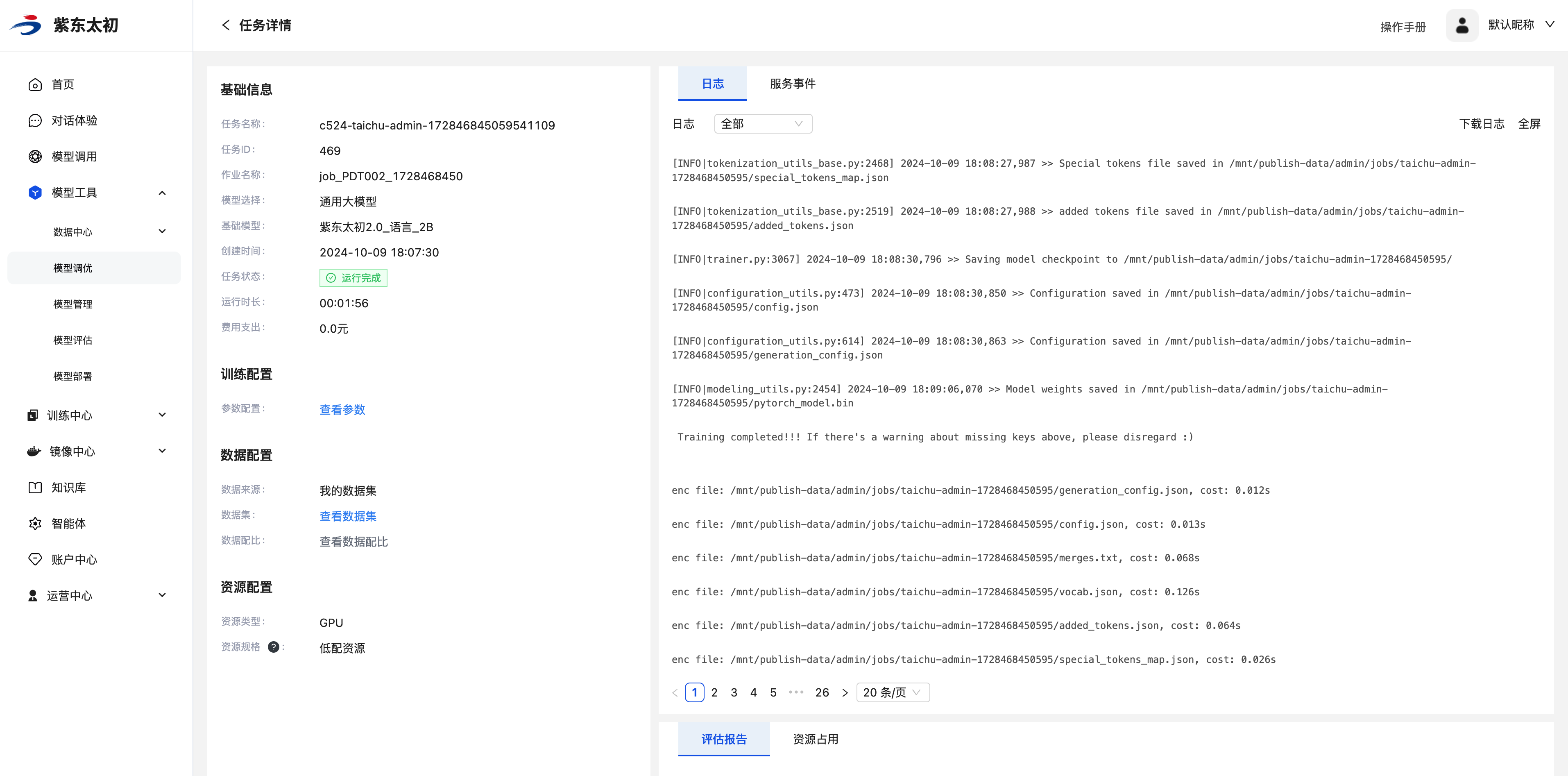
基础信息中会增加展示当前任务的ID、作业名称、运行时长、费用等信息。训练配置的参数信息,数据配置的数据集、数据配比均支持点击查看具体内容,日志为当前任务训练过程中产生的日志内容,支持下载或全屏展示。
服务事件会记录当前大模型微调任务从创建任务、开始调度、开始训练、训练结束全过程的事件信息。

点击“评估报告”标签查看任务评估报告详情。在评估报告详情页会展示任务评估指标以及训练过程中的loss值、learning_rate参数的实时变化。
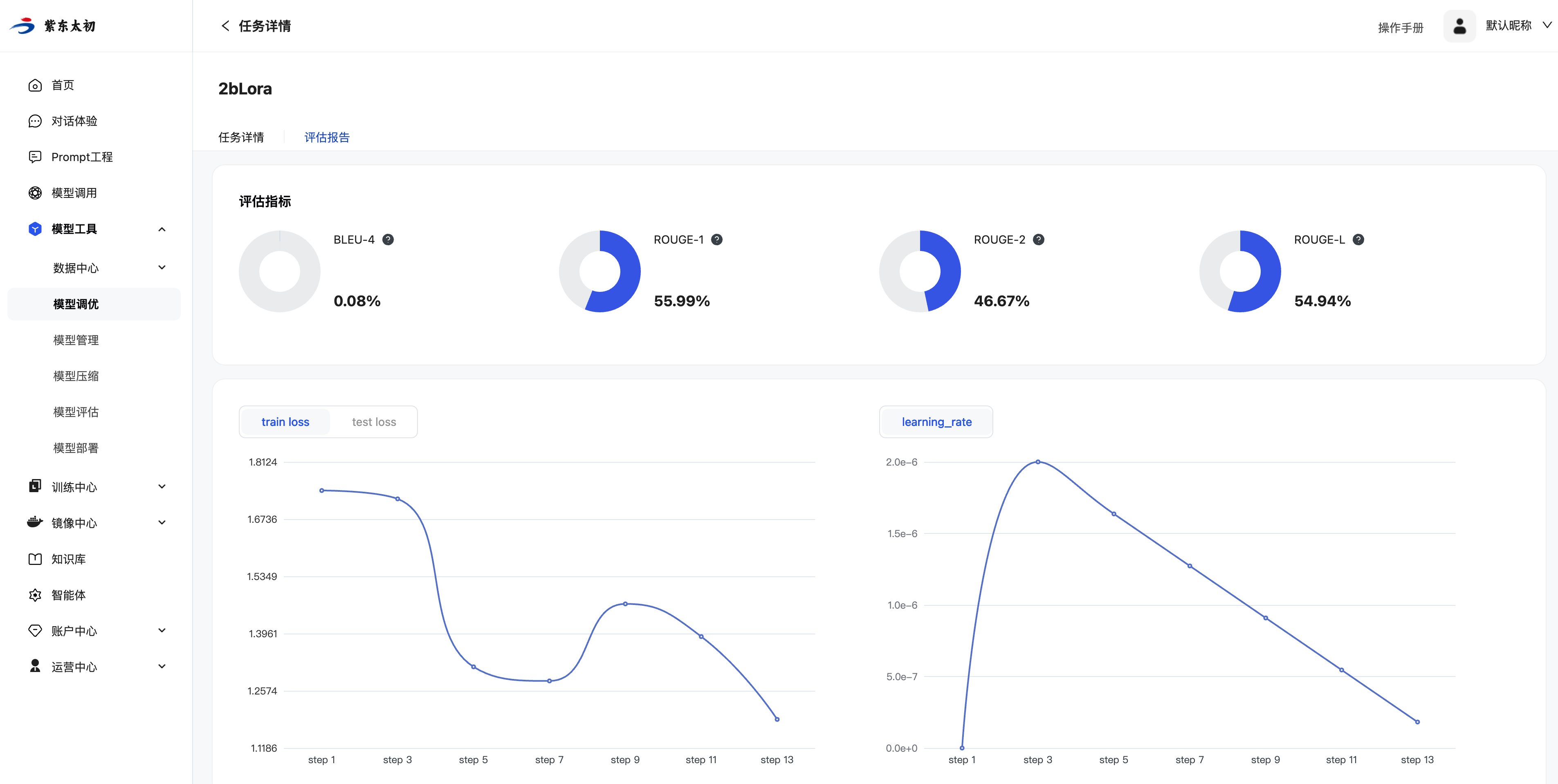
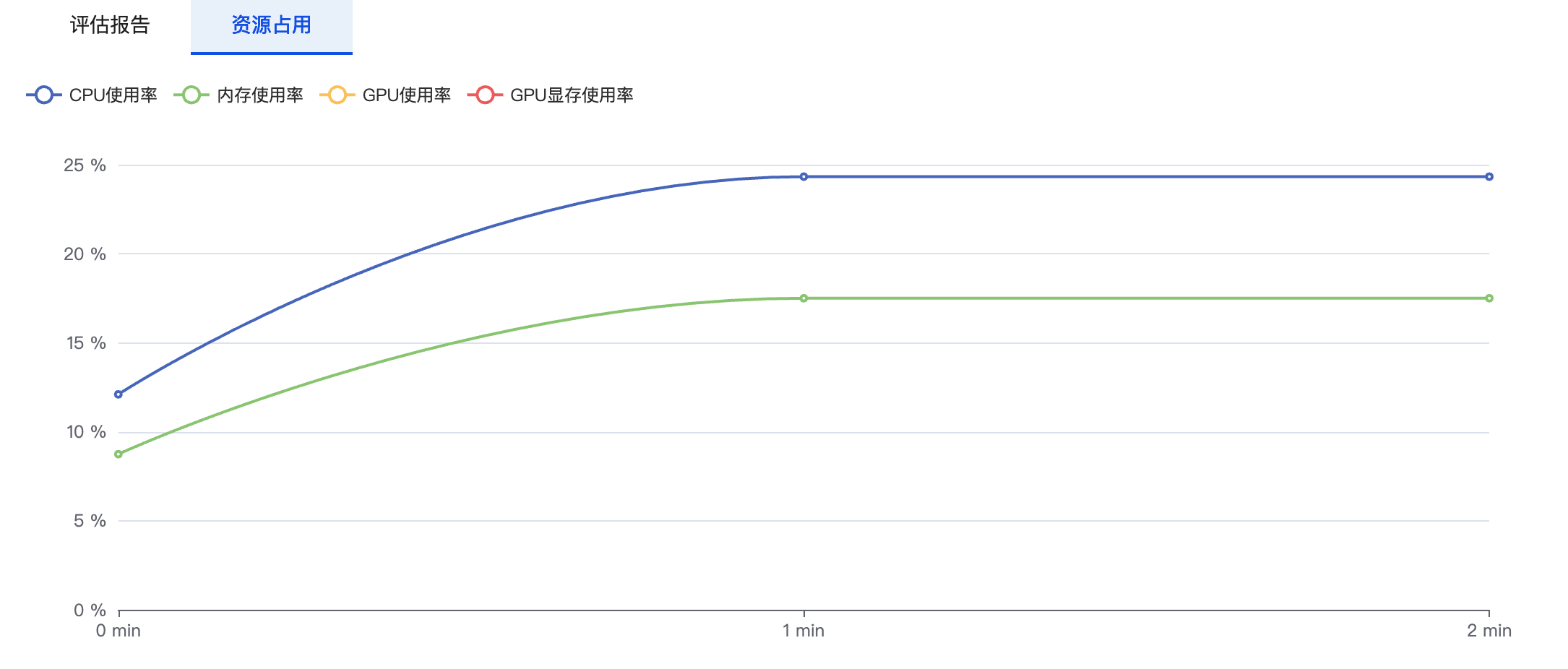
资源占用则会记录当前任务训练过程中CPU、内存、GPU等资源的使用情况。
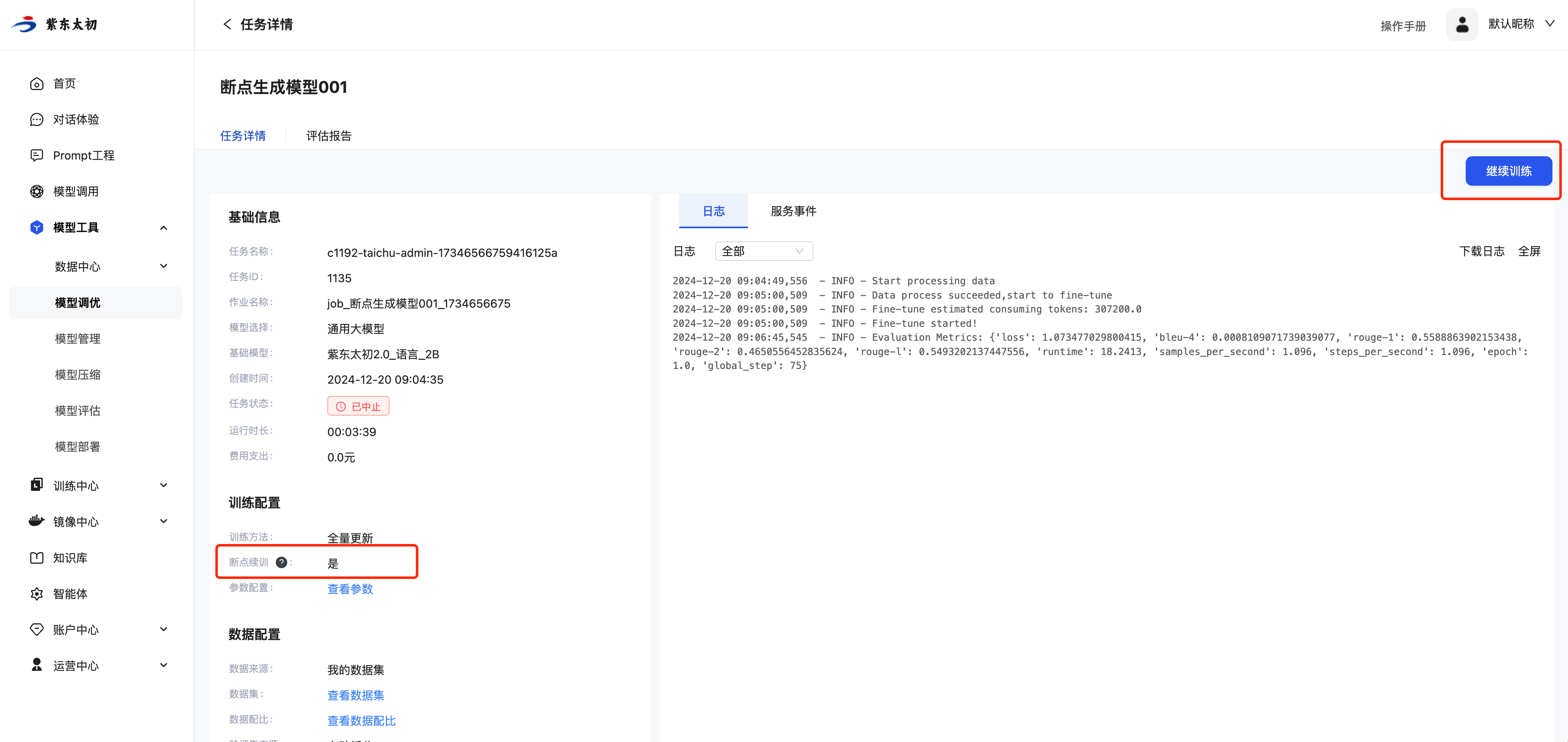
断点续训
如果任务选择了“断点续训”,已中止的任务可以在任务详情页重新拉起训练
删除
点击大模型微调任务列表操作栏中“删除”操作,弹框二次确认即可删除当前大模型微调任务。
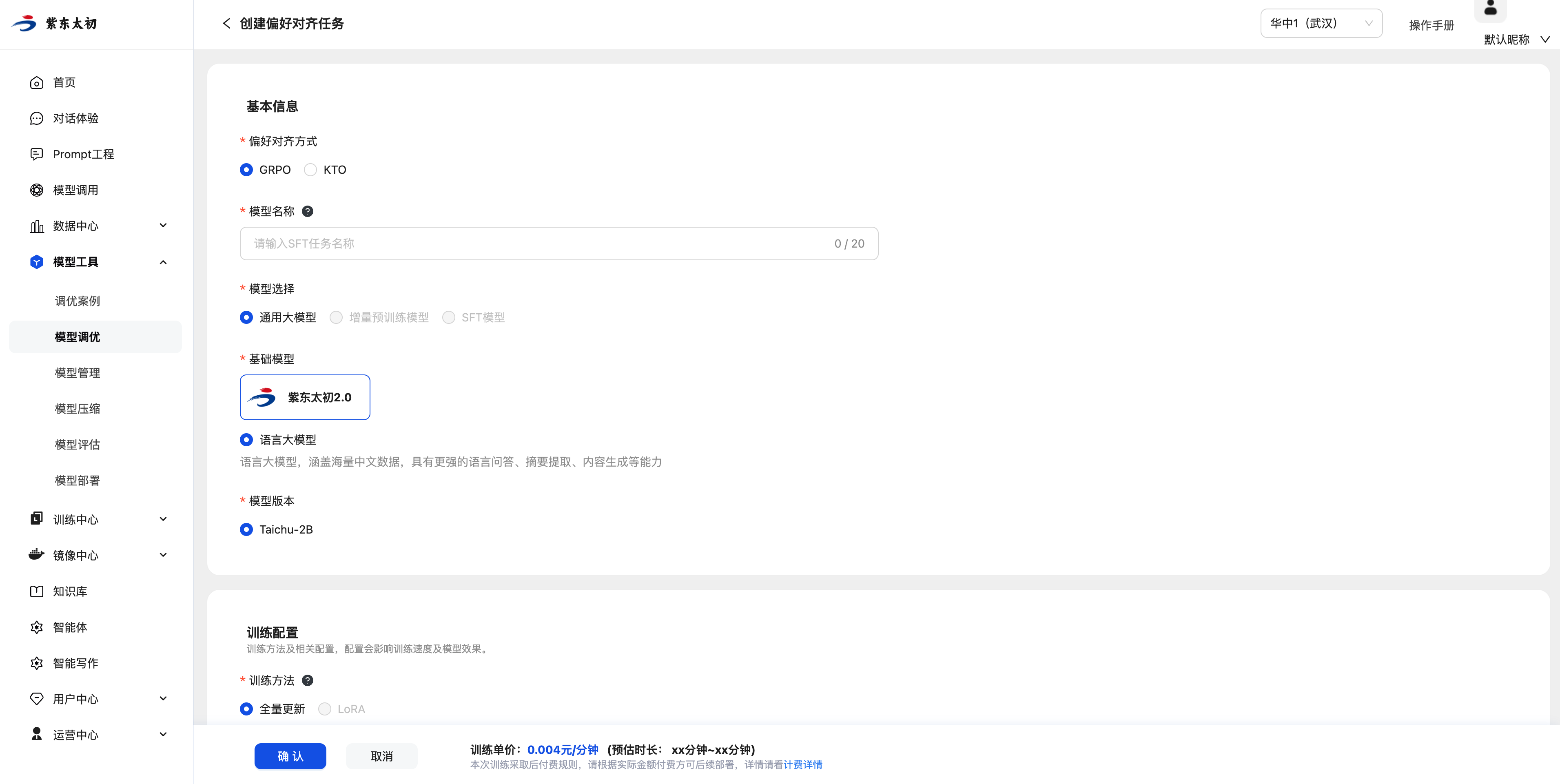
偏好对齐
偏好对齐是根据人类反馈的偏好数据调优大模型的方式。您可以选择您需要的基础模型、准备好的偏好数据集创建偏好对齐任务,从而创建更符合人类偏好的大模型。
创建任务
在大模型偏好对齐任务管理页面,选择“新建任务”按钮,然后,可根据训练任务基本信息、训练任务的参数配置、训练所需数据配置、训练任务资源配置即可创建大模型偏好对齐任务。平台支持GRPO和KTO两种偏好对齐方式。
基本信息
选择偏好对齐方式,填写作业名称,选择通用大模型、增量预训练模型或者微调后的模型作为基础模型。
训练配置
训练配置是配置大模型微调的参数,包括训练方法和微调参数。
训练方法区分全量更新与LoRA微调。
| 训练方法 | 说明 |
| 全量更新 | 全量更新在训练过程中对大模型的全部参数进行更新,可以充分利用训练数据,有潜力在新任务上达到更好的性能。 |
断点续训支持在主动或被动终止任务的情况下,从断点前保存的模型/权重继续训练。选项默认为否,使用断点续训会增加模型训练时长和存储空间占用。
| 任务终止情况 | 说明 |
| 主动终止 | 手动停止任务。 |
| 被动终止 | 因为训练过程中通信、机器故障等异常导致的任务中断。 |
参数配置主要包括迭代轮数、学习率、序列长度、批处理大小,系统会根据不同的模型设置不同的默认值,可按需调整。
| 超参数 | 参数说明 |
| 迭代轮数 | 迭代次数(epoch),模型训练过程中迭代的次数。 |
| 学习率 | 学习率(LearningRate)是在梯度下降的过程中更新权重时的超参数,过高会导致模型难以收敛,过低则会导致模型收敛速度过慢,平台已给出默认推荐值,可根据经验调整。 |
| 序列长度 | 单条数据的长度,单位为token。建议数值大小选择参考训练数据的长度,序列长度一般建议大于训练数据的长度,数值越大资源需求越多。 |
| 批处理大小 | 批处理大小(Batch Size),每一步训练中使用的样本数。较大的批处理大小可以加速训练,但所需资源越多,过大可能会导致OOM等问题。 |
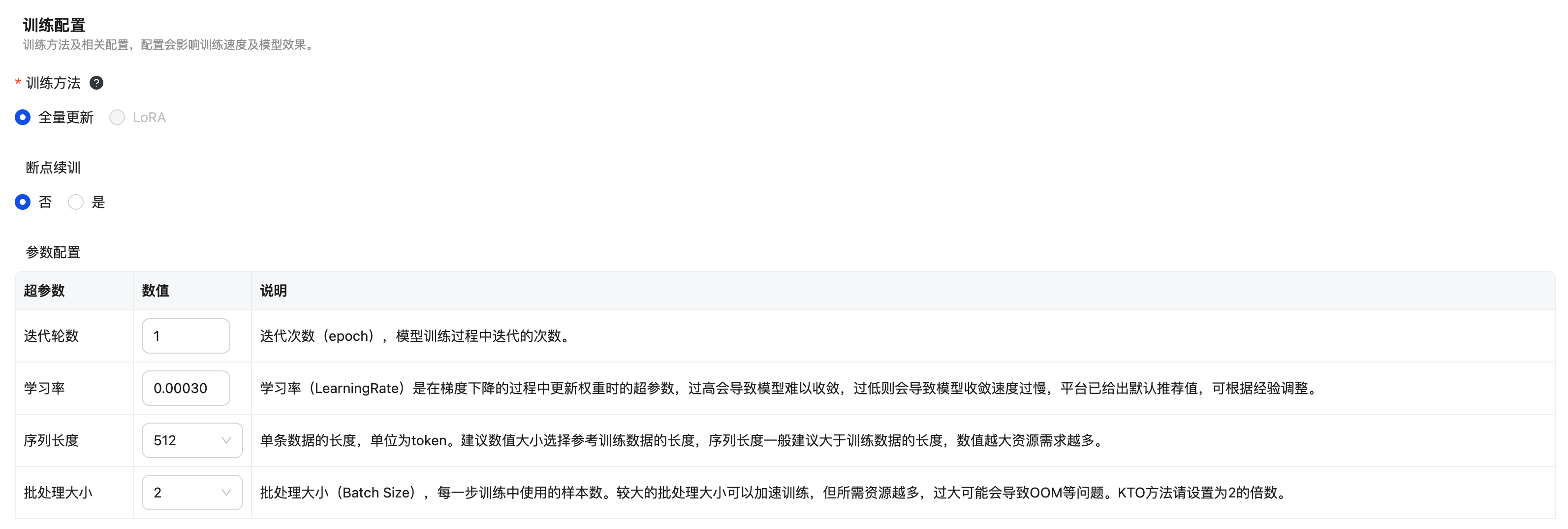
数据配置
偏好对齐任务需要匹配文本问答的数据集。GRPO和KTO训练需要的数据样例不同,用户可在数据集选择下拉框查看数据样例。
数据集来源可以为平台中已发布的数据集版本或预置的数据集,如果平台中没有合适的偏好对齐数据,需要先创建数据集,并导入满足要求的偏好对齐数据。
数据配比为系统中预置的通用语料数据,开启数据配比后选择需要的配置比例,系统会自动加入预置的通用语料数据与您选择的数据一起混合训练。
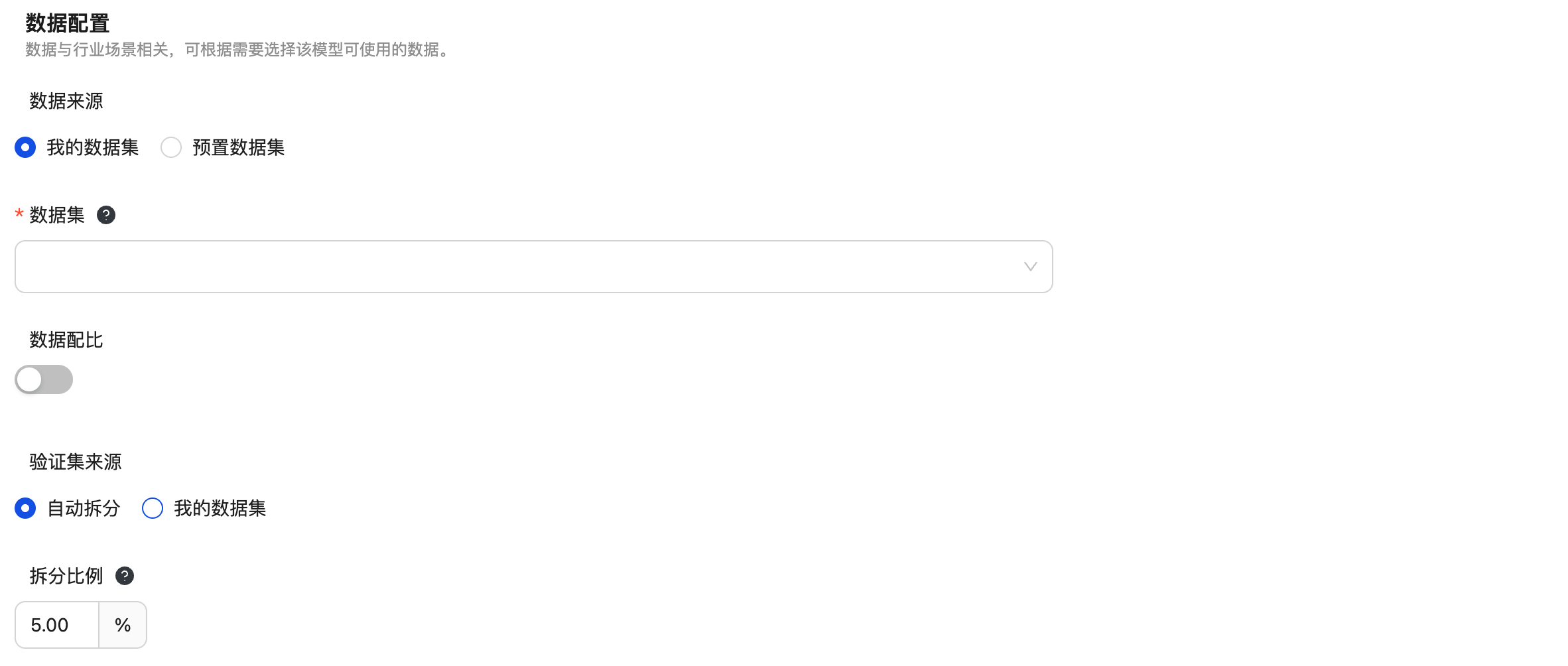
资源配置
资源配置中选择训练所需的资源类型、资源规格。可选择系统提供的公共资源池,或者用户已购买的专属资源池。
训练时长预估
在完成训练、数据、资源配置后,系统自动计算偏好任务的时长区间
查看与管理偏好对齐任务
在偏好对齐任务管理页面,可以点击操作栏查看任务详情和删除偏好对齐任务,删除任务需要二次确认。
调整排队中任务优先级
排队中任务的优先级有“高”、“中”、“低”三个等级。在资源紧张的情况下,优先级较高的任务会优先被分配资源。用户可根据需要调整排队中任务的优先级。点击优先级栏的上箭头,任务优先级上调一级;点击下箭头则下调一级。
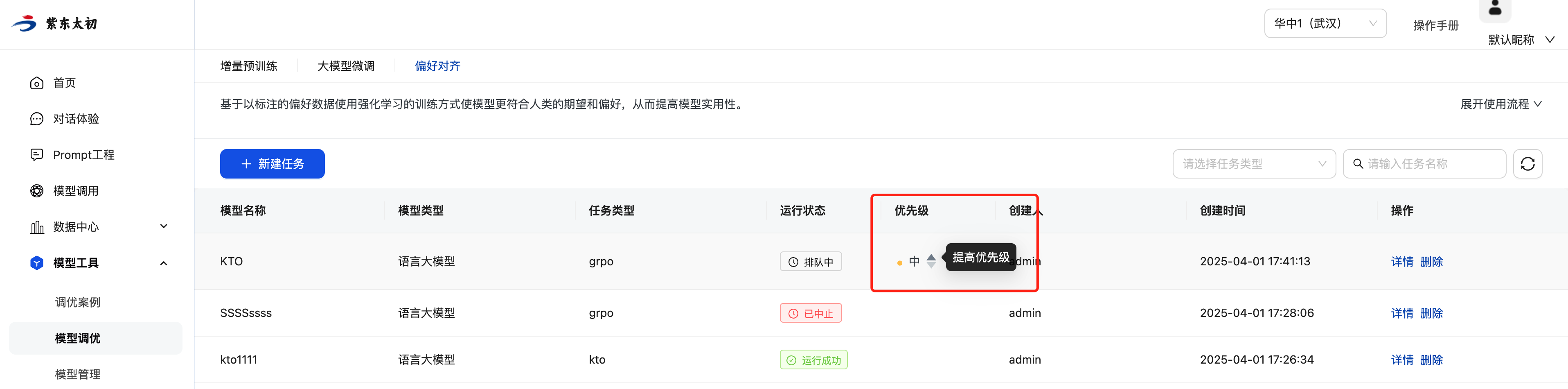 任务详情
任务详情
点击偏好对齐任务列表操作栏中“详情”按钮,即可进入偏好对齐任务的详情页,查看其详情内容。在任务详情页会展示创建任务时填写的基础信息、训练配置、数据配置、资源配置以及训练任务的日志、服务事件、评估报告和资源监控。
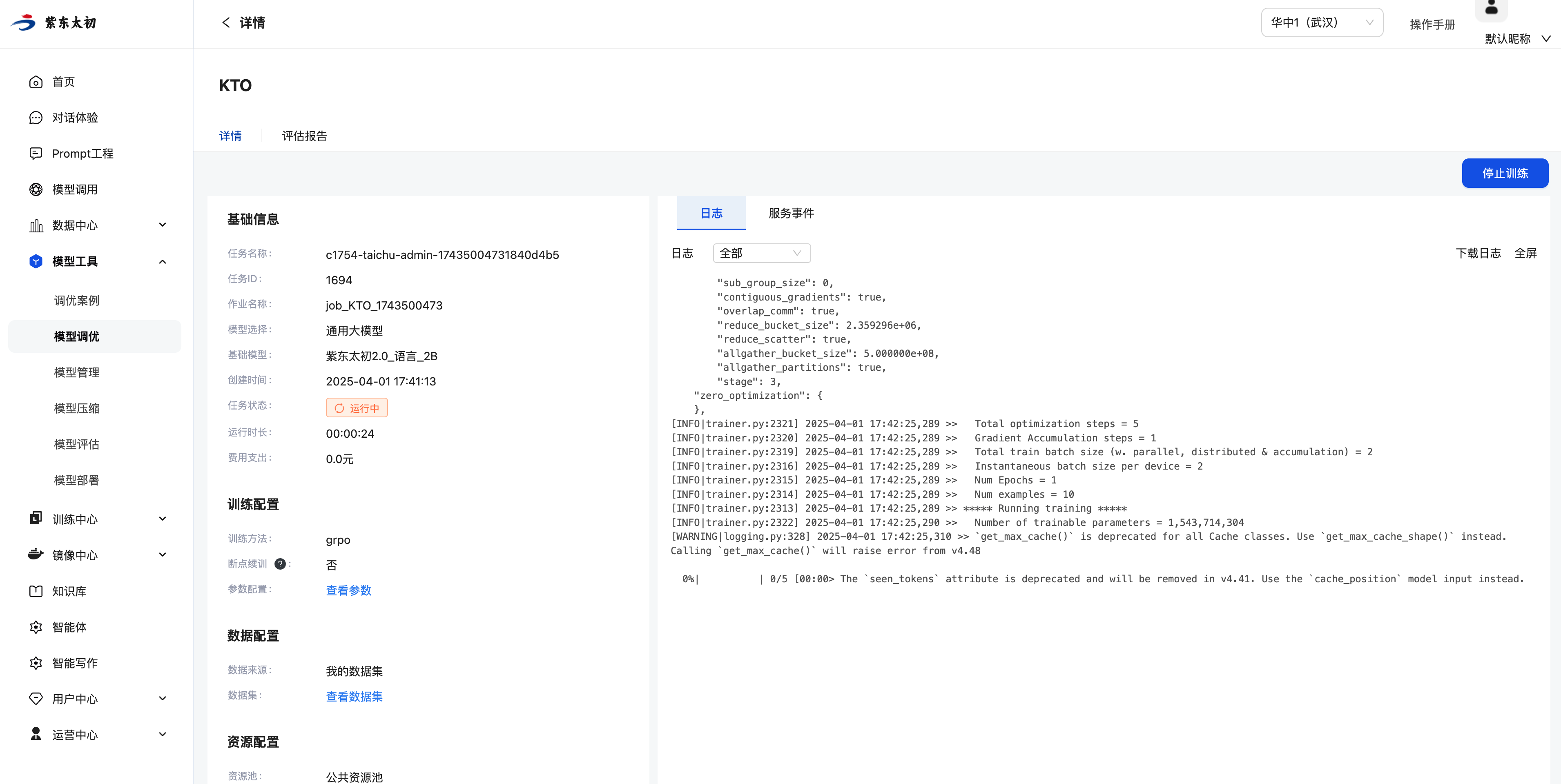 基础信息中会增加展示当前任务的ID、作业名称、运行时长、费用等信息。训练配置的参数信息,数据配置的数据集、数据配比均支持点击查看具体内容,日志为当前任务训练过程中产生的日志内容,支持下载或全屏展示。
基础信息中会增加展示当前任务的ID、作业名称、运行时长、费用等信息。训练配置的参数信息,数据配置的数据集、数据配比均支持点击查看具体内容,日志为当前任务训练过程中产生的日志内容,支持下载或全屏展示。
服务事件会记录当前偏好对齐任务从创建任务、开始调度、开始训练、训练结束全过程的事件信息。
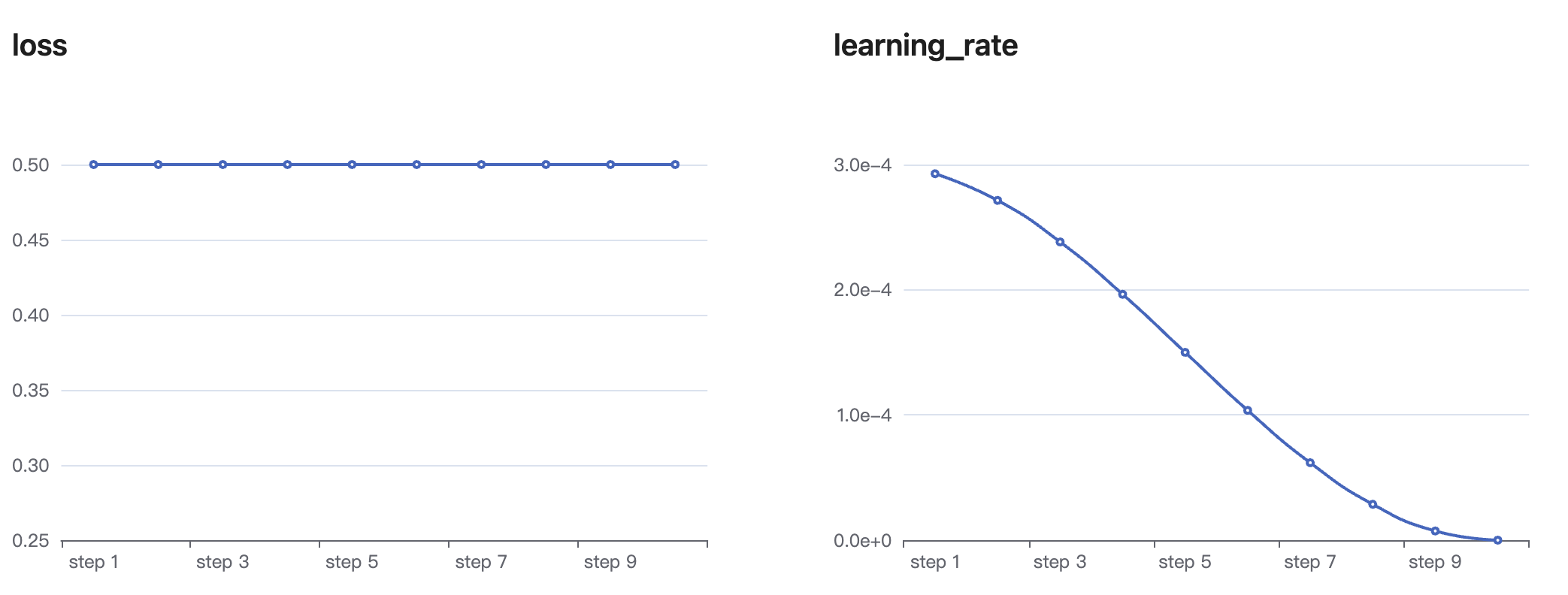
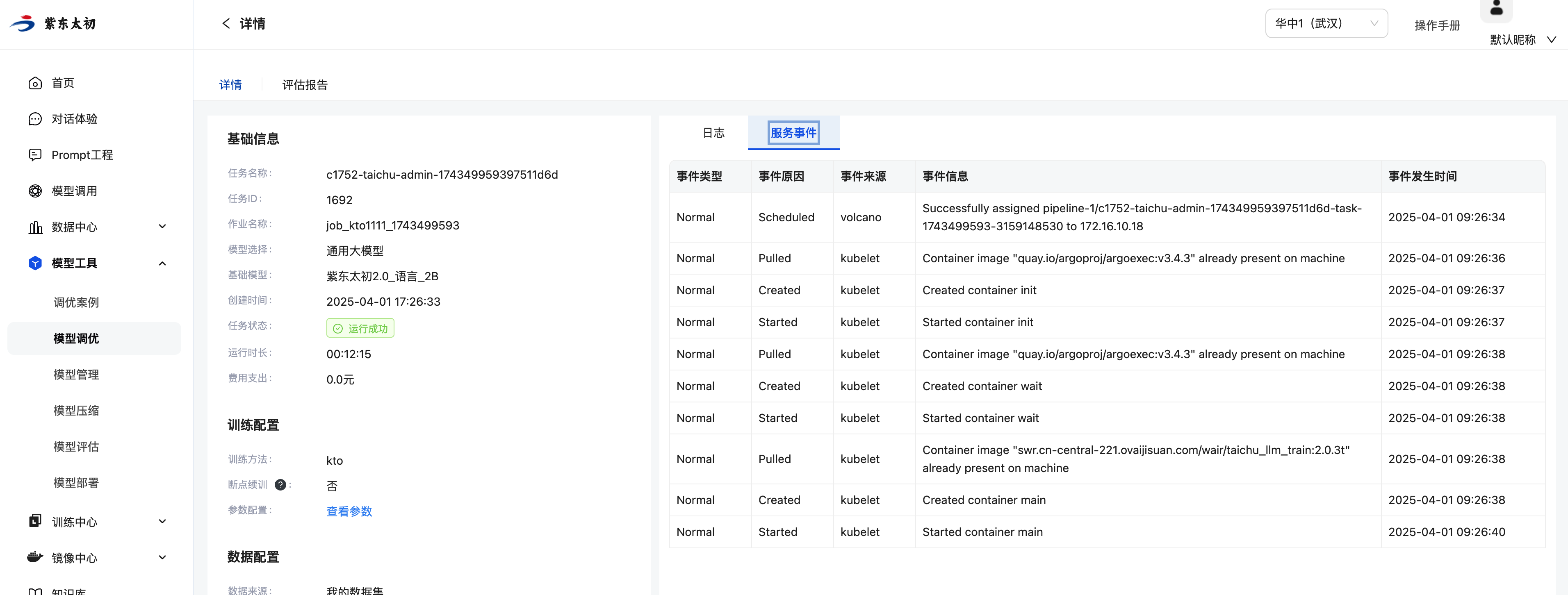 评估报告会展示训练过程中的loss值、learning_rate参数的实时变化。
评估报告会展示训练过程中的loss值、learning_rate参数的实时变化。
资源占用则会记录当前任务训练过程中CPU、内存、GPU等资源的使用情况。