深色模式
技术特性
AutoML、AutoDL
数据驱动
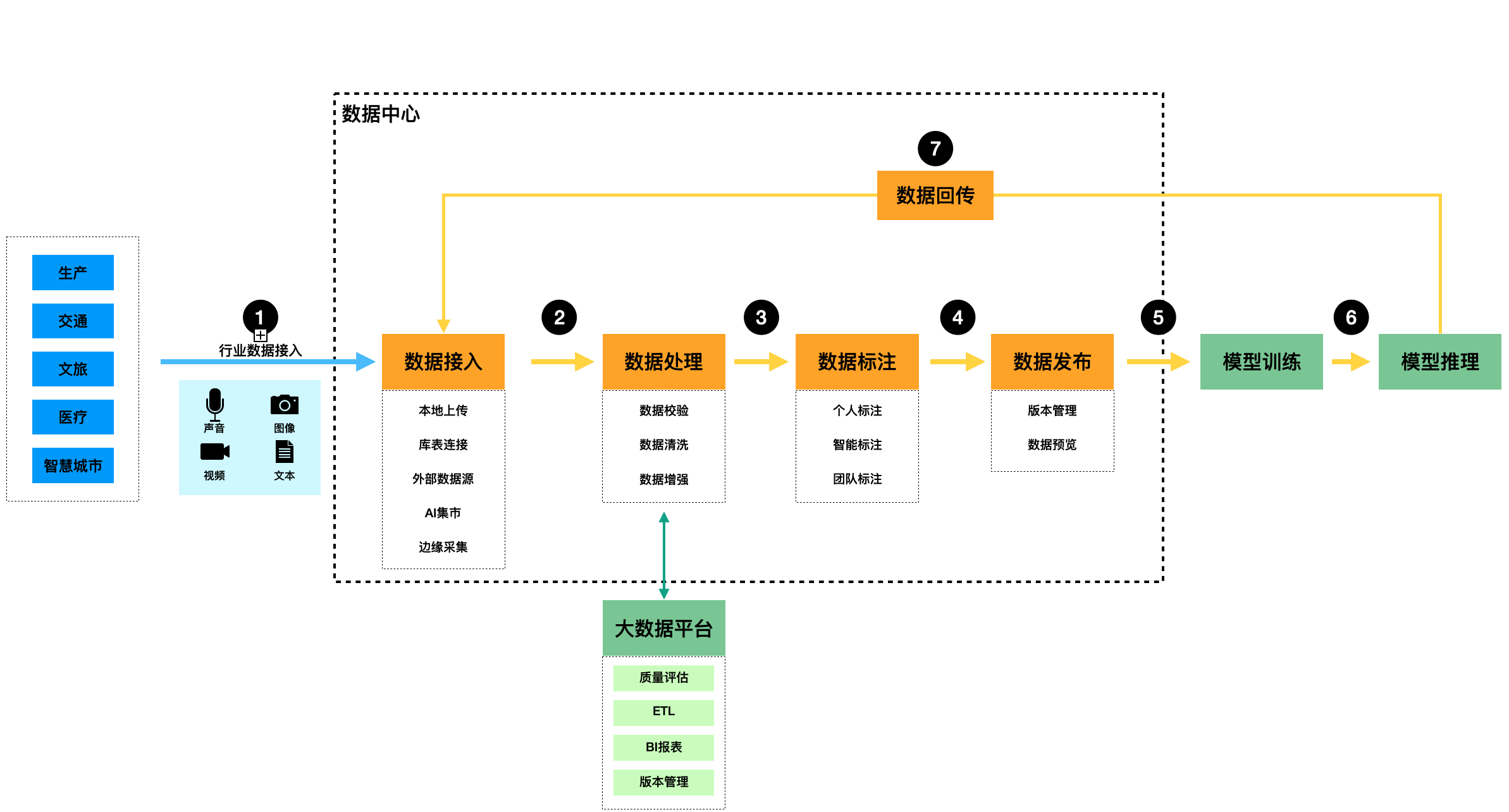
数据闭环
内存数据中间件
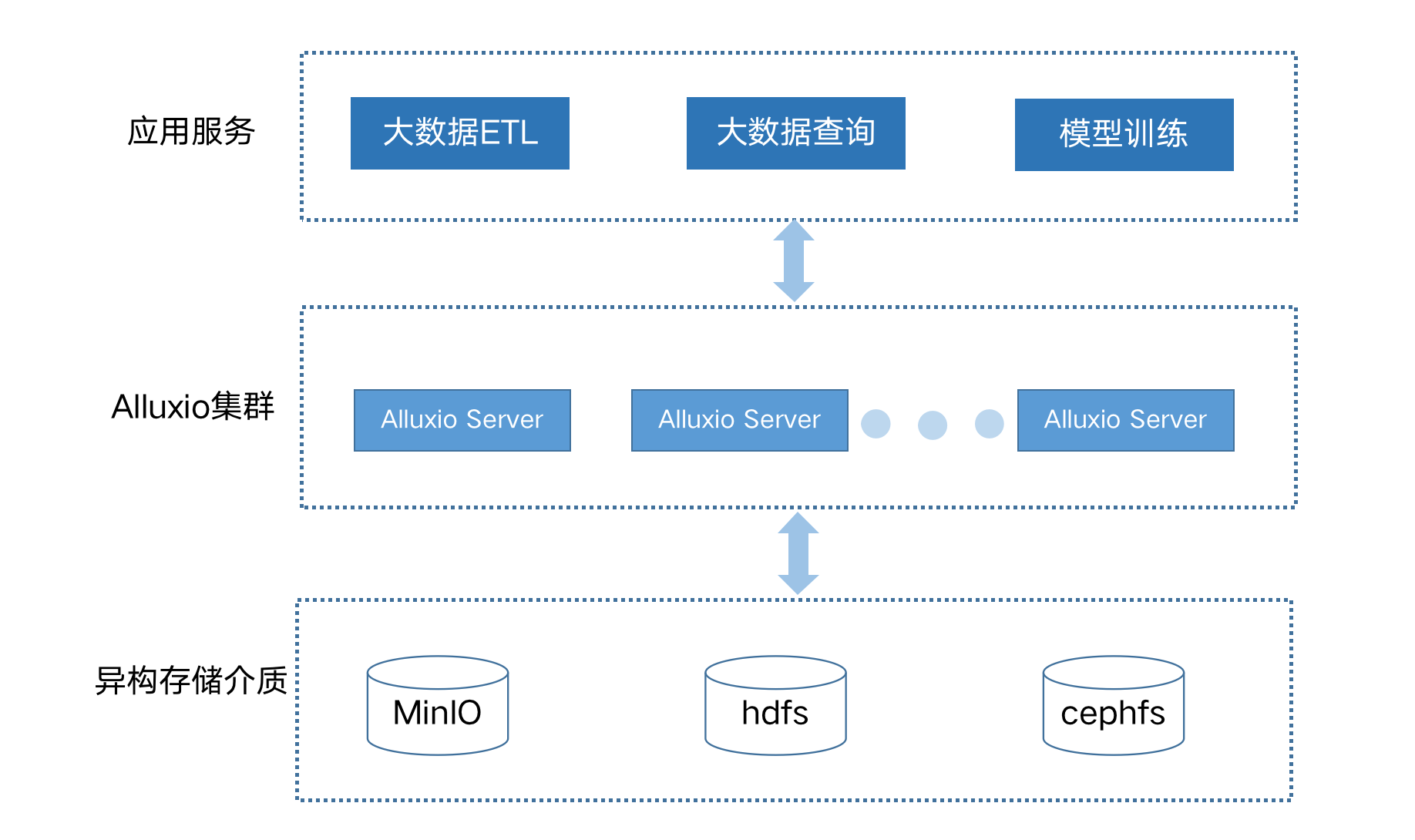
基于“容器化弹性基础架构+云平台 GPU/NPU 实例”进行分布式深度学习模型训练成为了业界生成 AI 模型的主要趋势。计算存储分离是云原生应用的基本架构,而对象存储经常用来存储和管理海量训练数据,尤其在图、文、视频等非结构化数据上更为出色。深度学习训练和推理任务对数据读写效率是模型开发效率的关键因素。平台使用Alluxio提供分布式缓存加速数据应用 。Alluxio通过在存储系统和计算框架之间增加一层数据抽象层,提供统一的挂载命名空间、层次化缓存和多种数据访问接口,可以支持大规模数据在各种复杂环境(私有云集群、混合云、公有云)中的数据高效访问。
分布式计算引擎
人工智能(AI)框架是AI平台的核心枢纽,下接GPU/NPU等底层AI计算芯片,提供异构计算框架屏蔽底层处理器差异和高效得到的算子库、图优化、编译器优化等加速训推过程;上承各种训练建模工具和推理部署应用,打通开发、训练、推理部署的全流程能力,使得各类算法高效研发迭代和大规模应用部署成为可能。
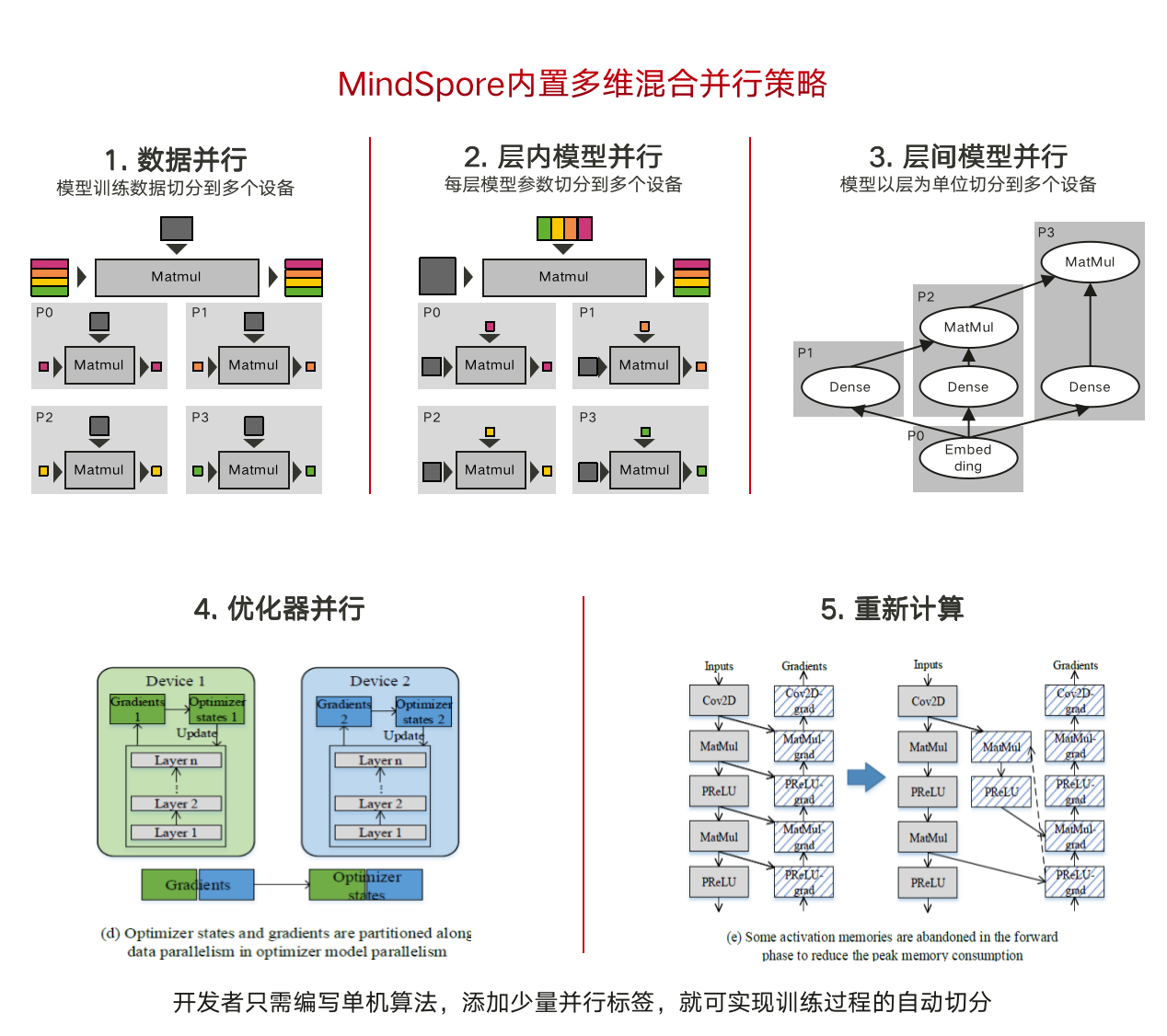
平台致力打造全栈国产化软硬件生态,深度集成领先的深度学习框架MindSpore。MindSpore是面向“端-边-云”全场景设计的AI框架,旨在弥合AI算法研究与生产部署之间的鸿沟。武智院和华为昇思团队紧密合作,提供基于MindSpore生态的深度学习端到端解决方案,研发团队及时追踪和解决用户使用MindSpore的问题。MindSpore设计上分为模型层、表达层、编译优化层和运行时Runtime四层架构,提供面向对象和面向函数的编程范式,动静统一的编程体验,实现覆盖端边云全场景的训推功能,支持CPU、GPU、NPU等多种芯片,并且在不同芯片上提供统一的编程使用接口以及可生成在多种硬件上加载执行的离线模型。
MindSpore支持多种分布式并行策略,供用户灵活组装使用,通过并行抽象,隐藏通讯操作,简化用户并行编程的复杂度。同时MindSpore面向分布式训练,还提供了pipeline并行、优化器并行、重计算等多种并行策略供用户使用。
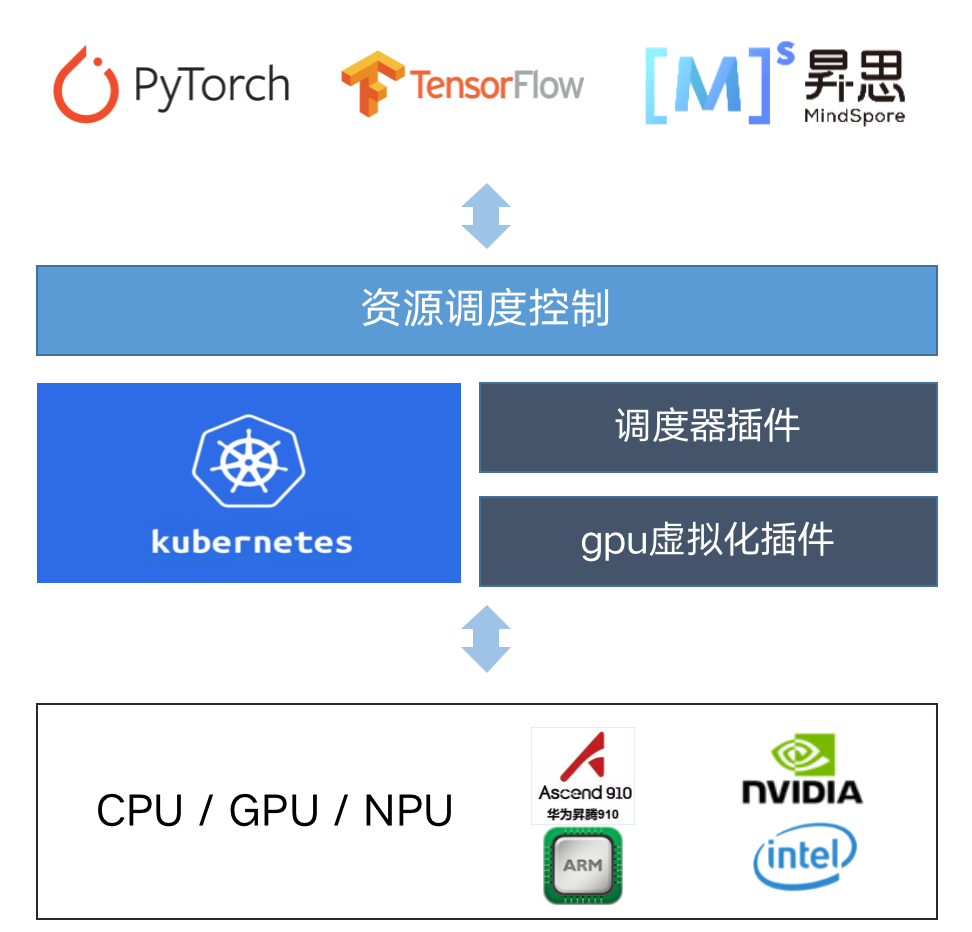
异构资源池化管理
平台支持单集群管理异构算力资源。数据处理、模型训练和服务推理任务作为容器由容器调度引擎Kubernetes统一调度管理。容器的虚拟化特性有天然的资源隔离跨平台等优势。平台通过虚拟化技术对CPU、GPU、华为Ascend NPU等不同算力节点统一管理和监控,支持动态扩缩容。用户在平台创建训练或推理任务时可选择算力类型,平台调度框架将任务调度到对应的算力节点上。
平台提供了多种资源规格选项,将任务需求的GPU/NPU卡数、显存大小、CPU核心数、内存大小等资源封装成不同规格。用户请求资源后,平台会根据当前资源剩余情况,选择资源满足的节点调度任务。私有部署版本中管理员还可以对不同用户、用户组设置资源额度,实现组织内资源的合理分配。
对于某些型号的GPU,平台还支持安装GPU虚拟化插件,多个任务共享一张GPU卡,还可以设置不同的调度策略最大化利用硬件资源,避免资源碎片化问题,具体支持的GPU型号可以和交付工程师咨询。
紫东太初全场景感知预训练模型
传统AI应用中,不同场景对应不同小模型,模型参数量小,泛化能力差。面对新场景需要从零起步,经过不断的调优迭代甚至推倒重来,成本高耗费巨大,阻碍了许多终端用户AI落地应用。大模型的出现和发展是AI产业快速发展的必然选择。大模型吸收海量知识,适配多业务场景。从原先的一个场景一个模型进化到一个模型适配多个场景,模型参数大,泛化能力强,解决AI应用碎片化问题。基于海量数据训练的大模型有强大的拟合能力,精度优势明显。用户提供少量行业数据基于预训练大模型进行微调成为了新的AI开发范式。
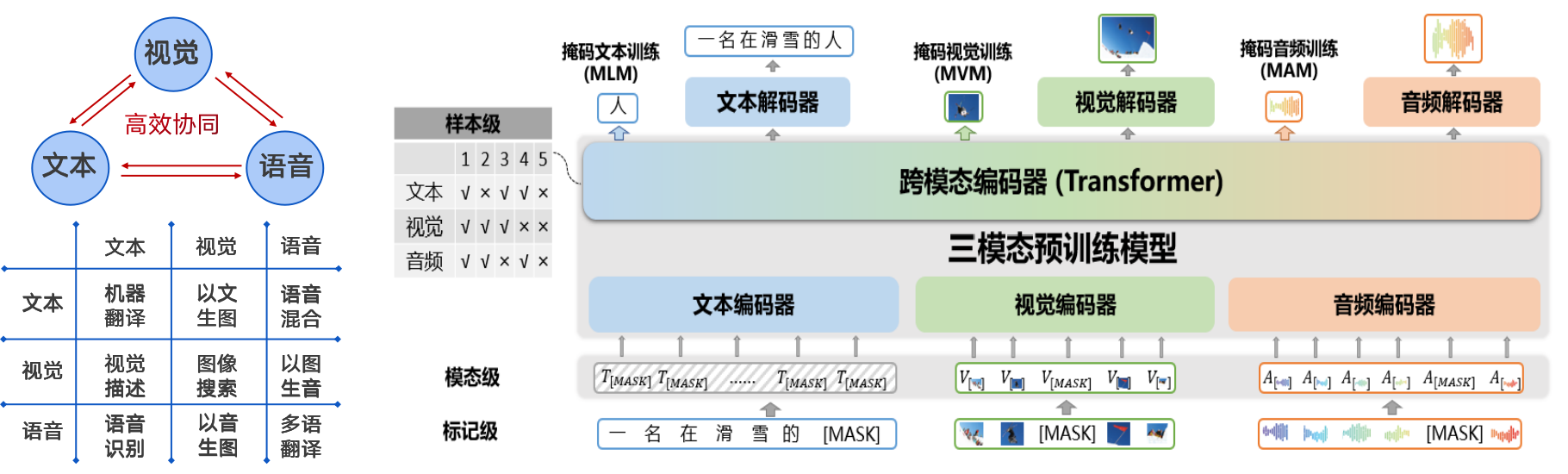
大模型服务平台以紫东太初——全球首个千亿参数多模态预训练大模型作为模型底座,多模态高效协同性能全球领先。多模态智能利用文本、图片、音频和视频等不同模态数据进行跨模态的统一表征和学习,是更接近人类的学习方式,突破当前AI技术局限,具备部分类脑特性,从“一专一能”迈向“多专多能”,在小样本学习、自然语言问答、跨模态生成等方面快速进步。紫东太初大模型基于模态理解和模态生成统一建模,在跨模态检索、多模态分类、语音识别、文本生成、图像生成、音频合成等30+多领域的理解与生成任务有出色表现。
针对大模型和主流深度学习模型的训练提供加速服务
- 大模型的训练场景中,支持主流大模型(ERNIE, GPT, VIT等)参数下的混合并行加速。
- 在主流深度学习模型的训练场景中,支持在大规模数据量下的数据并行加速需求。
产品特色
- 方便快捷: 大模型就能够灵活支撑图-文-音全场景AI应用,具有在无监督情况下多任务联合学习、并快速迁移到不同领域数据的能力
- 灵活高效: 平台支持公有云、私有云部署,支持多元异构的数据的接入与开发建模,且模型可支持云、边、端的快速轻量化部署和推理加速。
- 全场景服务: 为用户提供数据接入、模型训练、模型推理的全流程开发支持,解决AI开发过程与资产管理碎片化的问题,保障AI应用落地到真实的业务场景。
- AI资产集市: 集市中预置中国科学院自动化研究所和武智院的专家团队提供的优质数据集、算法、模型等AI资产,用户亦可参与AI集市生态建设,将个人AI资产分享至集市中,加速AI资产的开发、共享和落地,共同打造开放、繁荣的AI生态。
产品优势
- 低门槛开发: 开箱即用,支持大模型下游、自动化、可视化等多模板任务建模,低参数优化,快速完成行业模型的搭建。
- 高效率开发: 内置武智院、中科院紫东太初等大模型指导下游多领域、多行业小样本一键微调建模,且平台内置大量行业模型,可大幅缩减建模时间、资源等成本。
- 全栈国产化: 兼容华为昇腾NPU、Nvidia GPU、Arm64架构的硬件资源,MindSpore、Pytorch等计算框架,可实现全栈国产化,可控、可信。
- 支持公有云/私有化部署: 公有云开箱即用,无需依赖本地算力及环境,私有化部署功能灵活可配,且支持场景定制化开发。
