深色模式
模型体验
模型体验提供的是模型即服务的能力,为泛AI开发者提供灵活、易用、低成本的模型服务,加速AI模型资产的开发与落地。平台中提供多模态、计算机视觉(CV)、自然语言处理(NLP)、语音、虚拟人等多场景的优质模型,开发者可在平台上免费体验模型提供的能力。
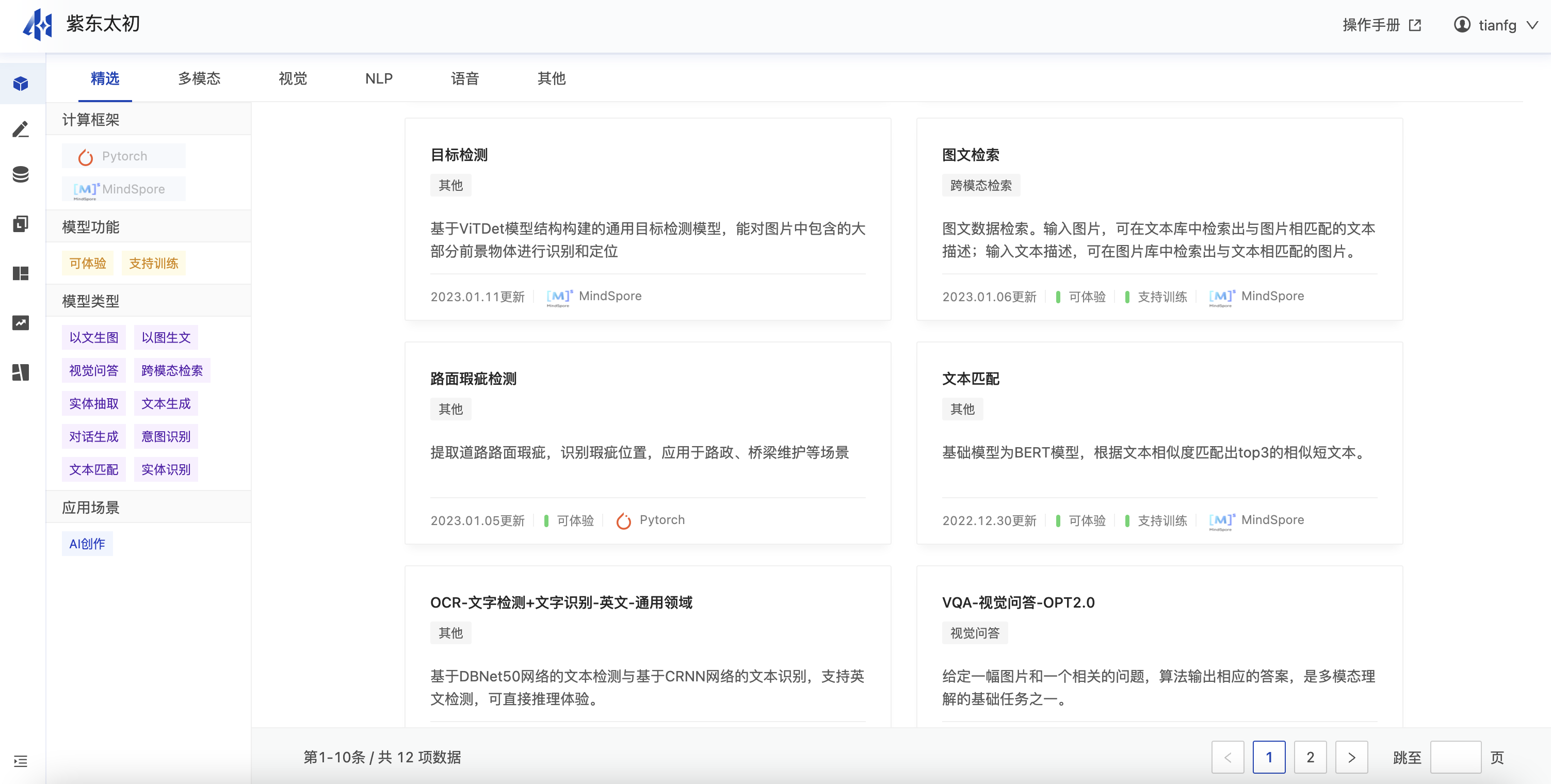
精选、多模态、视觉、NLP、语音等类别下还区分子类别:计算框架、模型功能、模型类型、应用场景等。
- 计算框架:用于机器学习训练货推理等底层计算框架,支持Pytorch、MindSpore、TensorFlow等不同框架。
- 模型功能:在模型体验中心的模型支持体验、支持训练等功能,支持体验则可点击卡片进入体验页,支持训练则可用于模型训练的任务作为预训练模型。
- 模型类型:与模型应用场景(多模态、视觉、NLP、语音等)相关联。例如,多模态中以图生文、以文生图、视觉问答、跨模态检索等;视觉中图片分类、目标检测、语义分割等;NLP中实体抽取、实体关系抽取、文本生成、意图识别等;语音中语音识别、语音分类等。
- 应用场景:模型在实际应用中可能涉及的场景,例如以文生图模型、文本生成模型均可应用于AI创作相关场景中。
模型卡片
模型卡片是模型体验页中展示模型基本信息的卡片,模型卡片中包括模型名称,模型标签,模型简介,更新时间,可体验、支持训练与否,计算框架等内容。点击模型卡片即可进入模型详情页,详情页中可在线体验模型、查看模型详细介绍。

体验模型
模型卡片中标识有“可体验”的模型均支持在线体验,及可通过示例数据或用户添加预测数据在线发起预测体验,预测成功后会实时输出预测结果。
多模态跨模态检索
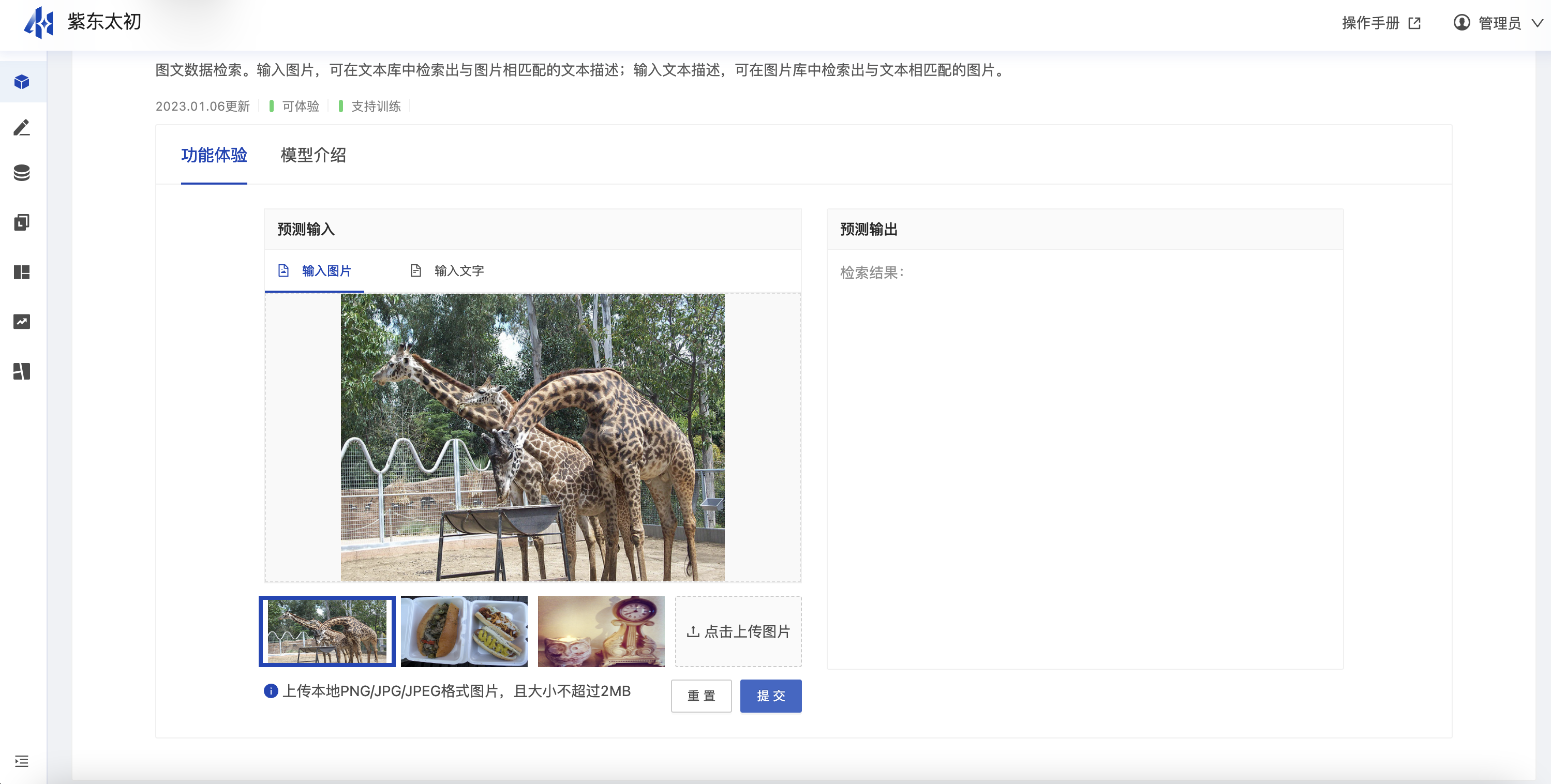
跨模态检索模型,可以实现图文检索的功能。输入一张图片,返回文本库中与该图片最接近的若干文本;输入一段文本,返回图片库中与该文本最接近的若干图片。该模型是基于紫东太初多模态大模型,使用flickr30K-CN数据集,对跨模态检索任务进行微调输出的模型。
输入为图片时则预测输出为检索到的文本。
输入为文本时则预测输出为检索到的图片。
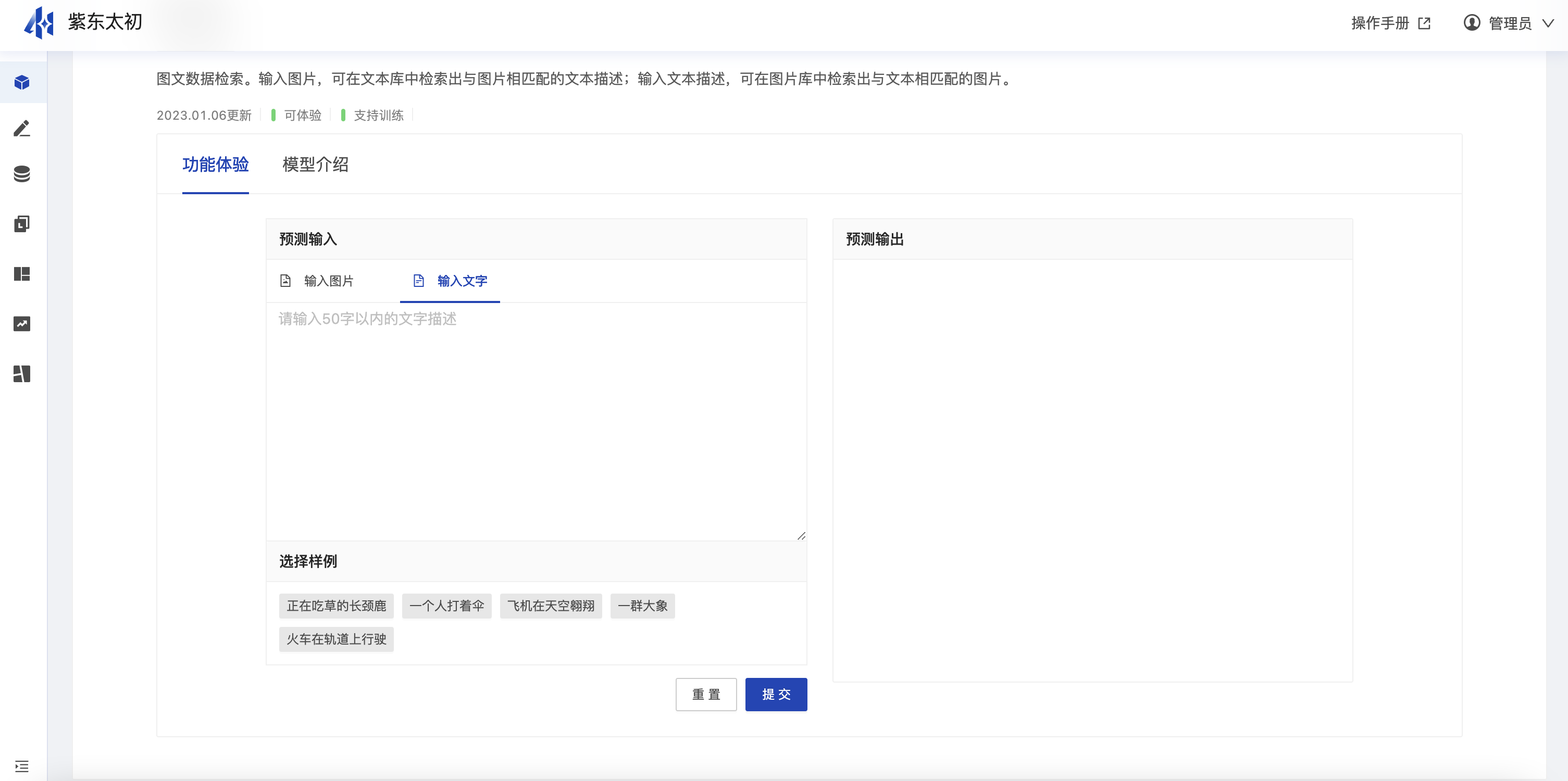
支持用户自定义添加图片或者文本内容作为输入,例如输入“火车穿过充满树木的农村乡村”、“许多空巴士停在停车场”等文本内容检索得到的结果。

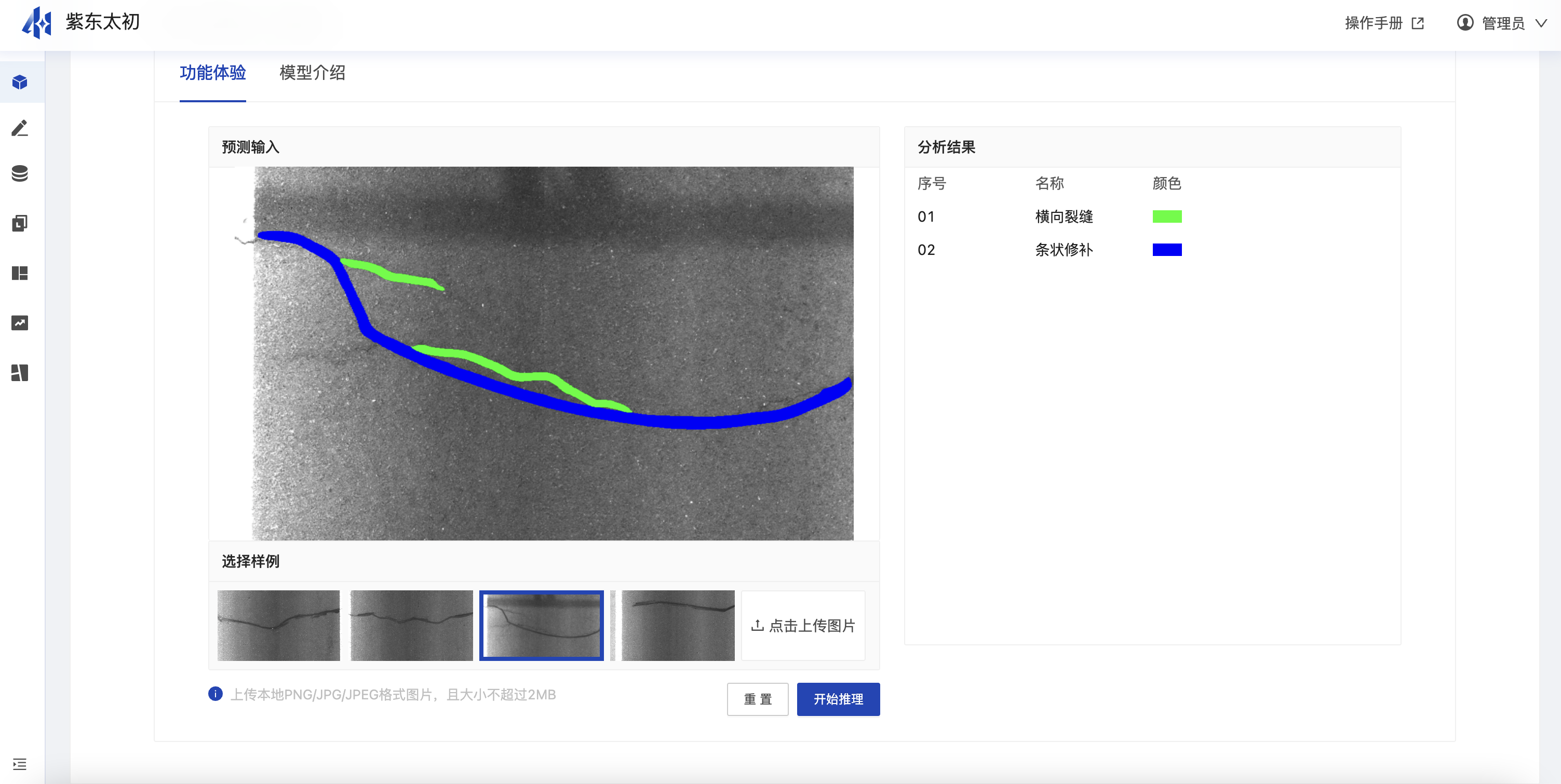
视觉路面瑕疵检测
路面瑕疵检测模型主要用来检测路面的破损情况,支持对常见的纵向裂缝、横向裂缝、条状修补、块状修补、坑槽、龟裂、松散等多种路面缺陷的检测和识别。选取示例图片数据后点击“开始推理”即发起预测的指令,完成预测后输出结果,并用不同颜色标识缺陷类型。
自动学习
市场中对AI的需求较为迫切,且AI面临人才成本高、开发难度大等不同问题,AI需要在各行各业实际场景中落地,必须要降低AI模型开发难度和门槛。当前仅少数算法工程师和研究员掌握AI的开发和调优能力,并且大多数算法工程师缺少算法模型真正产品化、工程化的能力。而对于大多数业务开发者来说,更是不具备AI算法的开发和参数调优能力。这导致大多数企业都不具备AI开发能力。
自动学习是根据用户数据或系统示例数据进行全自动建模的功能,通过算法实现模型训练的参数自动化选择和模型自动调优的自动学习功能,让零AI基础的业务开发者可快速完成模型的训练和部署。依据开发者提供的标注数据及选择的场景,无需任何代码开发,自动生成满足用户精度要求的模型。
自动学习介绍
用户可根据多模态、CV、NLP、语音等分类创建自动学习任务。例如:多模态分类中可创建以图生文、跨模态检索、视觉问答、图文问答等类型任务;CV分类中可以创建图片分类、目标检测、语义分割等类型任务;NLP类型中可创建文本分类、实体关系抽取、文本问答等类型任务;语音类型中可创建语音分类的任务。
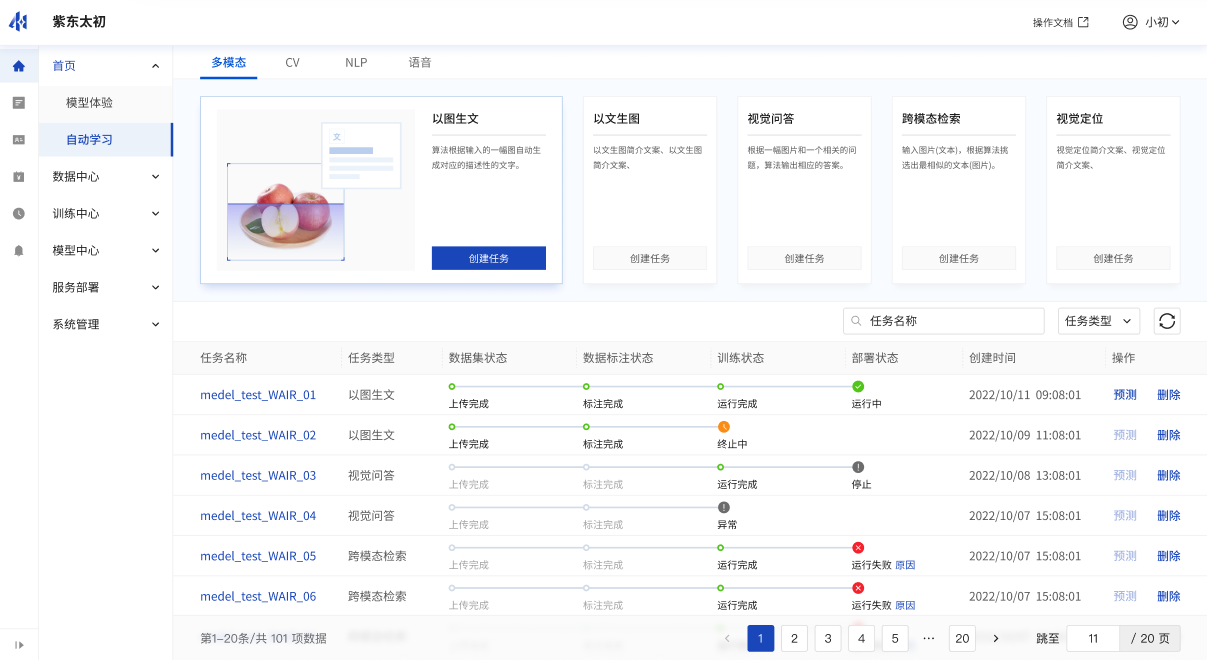
自动学习任务类型
- 多模态:目前大模型服务平台中多模态自动学习能力支持3种不同的场景。
- 以图生文:根据输入的一幅图像自动生成对应的描述性的文字。
- 悟空画画(个性化文生图):融入自定义图片中的主体信息,根据文本描述生成具有自定义图片中主体信息的个性化图片。
- 图文问答:算法基于图片内容以及输入的问题,自动生成对应的文本应答,支持多轮问答。
- 视觉:目前大模型服务平台中视觉自动学习能力支持4种不同的场景。
- 图片分类:识别一张图片属于某类物体/场景,适用于图片的单一类型识别。
- 目标检测_矩形框:检测图像中目标对象的位置,并输出对象在图像中的坐标位置以及标签。
- 目标检测_多边形:对图像中前景物体进行检测和定位,适用于复杂形状物体检测的场景。
- 富文档信息抽取:提取富文档(包含文本、表格等信息的文档图片)中的实体以及实体关系数据,获取用户所需要的信息。
- NLP:目前大模型服务平台中NLP(自然语言处理)自动学习能力支持2种不同的场景。
- 文本分类:根据文本分类标签对文本内容进行自动分类,每短文本内容均可属于某一种标签类别。
- 实体关系抽取:从文本中抽取实体和关系,并赋予类别和标签,适用于知识抽取、关系抽取等场景。
- 文本问答:算法基于输入的问题,自动生成对应的文本应答,支持多轮问答。
- 语音:目前大模型服务平台中语音自动学习能力支持1种场景。
- 情感分类:语音情感识别,识别输入60s以内(≤60秒)语音内容的情感偏向性(negative、neutral、positive)。
创建自动学习任务
选择需要建模的应用方向(多模态、CV、NLP、语音),再根据需要建模的类型选择对应的卡片,点击卡片中“创建任务”,进入创建任务页面。
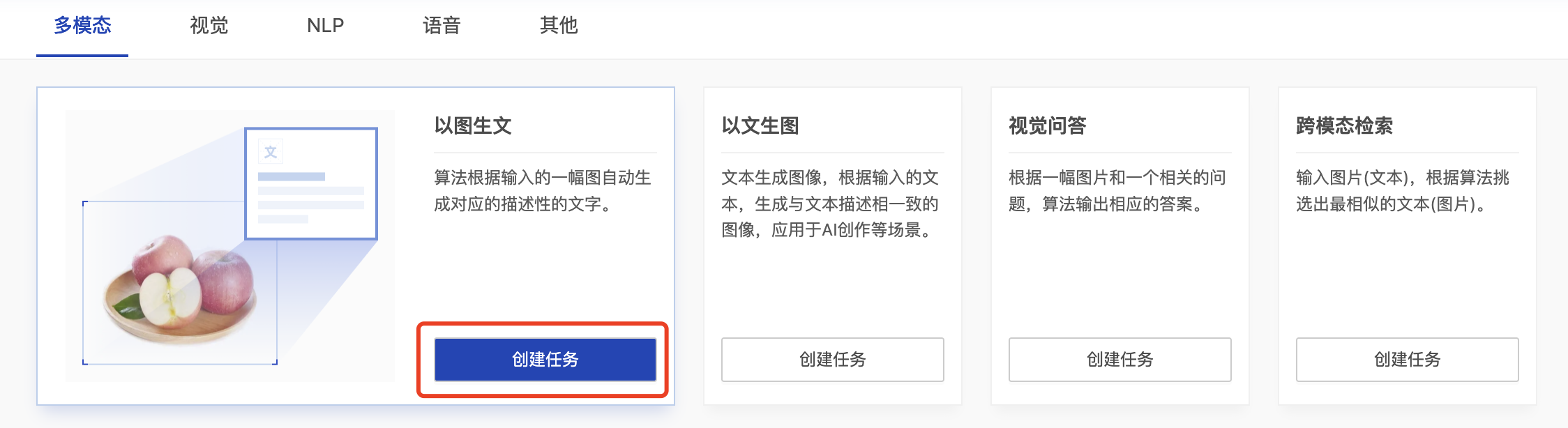
创建任务页面需要填写任务名称、数据集来源、标注状态、训练数据等信息。数据集可来源于本地数据、示例数据集或线上数据集;标注状态支持已标注数据、未标注数据,若为未标注数据,需对数据进行标注后才可进行后续的模型训练操作;若为本地数据支持上传zip包等不同格式的数据。
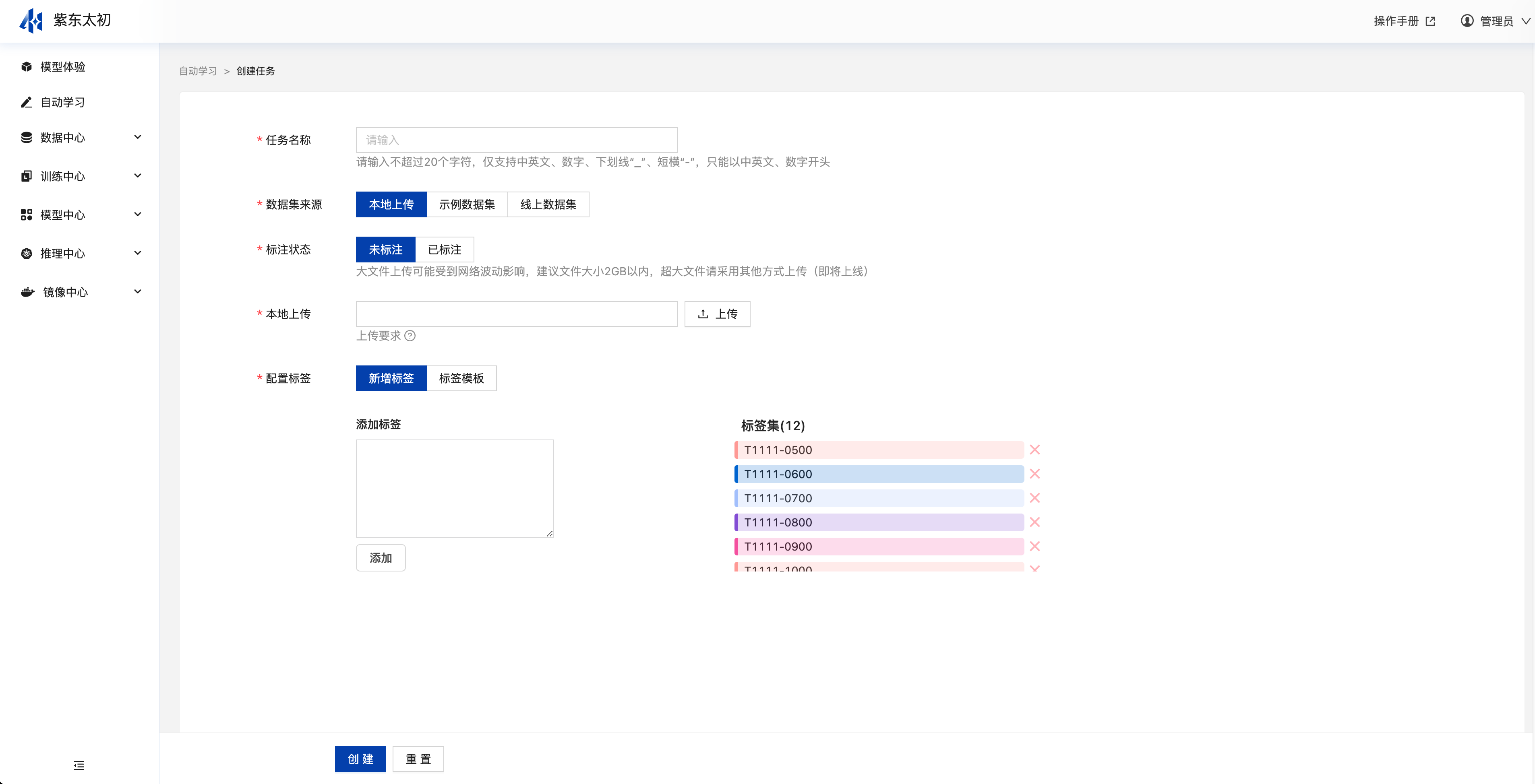
创建自动学习任务参数说明:
| 参数名 | 参数说明 |
|---|---|
| 任务名称 | 自动学习任务名称:
|
| 数据集来源 | 数据集来源可选择“本地上传”、“示例数据集”、“线上数据集”。
|
| 标注状态 | 标注状态区分为“已标注”、“未标注”,选择“已标注”则后续无需标注流程,若选择“未标注”则后续需要对数据进行标注的操作。 |
| 数据 | 根据数据集来源“本地上传”、“示例数据集”、“线上数据集”区分不同操作。
|
| 配置标签 | 若在标注状态中选择未标注,则需要配置标签,配置标签可通过新增标签添加标签,或基于标签模版创建标签。
|
任务中数据标注
自动学习中数据标注是针对当前创建自动学习任务等数据进行标注操作,若当前任务中数据已标注,则无需再次标注,可直接应用于后续的训练,对于未标注的数据才需要进行标注。自动学习任务中点击任务名称即可进入任务不同流程等进度,点击“下一步“即可进入标注操作。
数据标注任务未标记为“已标注”前均支持进入标注页面,对数据进行标注。
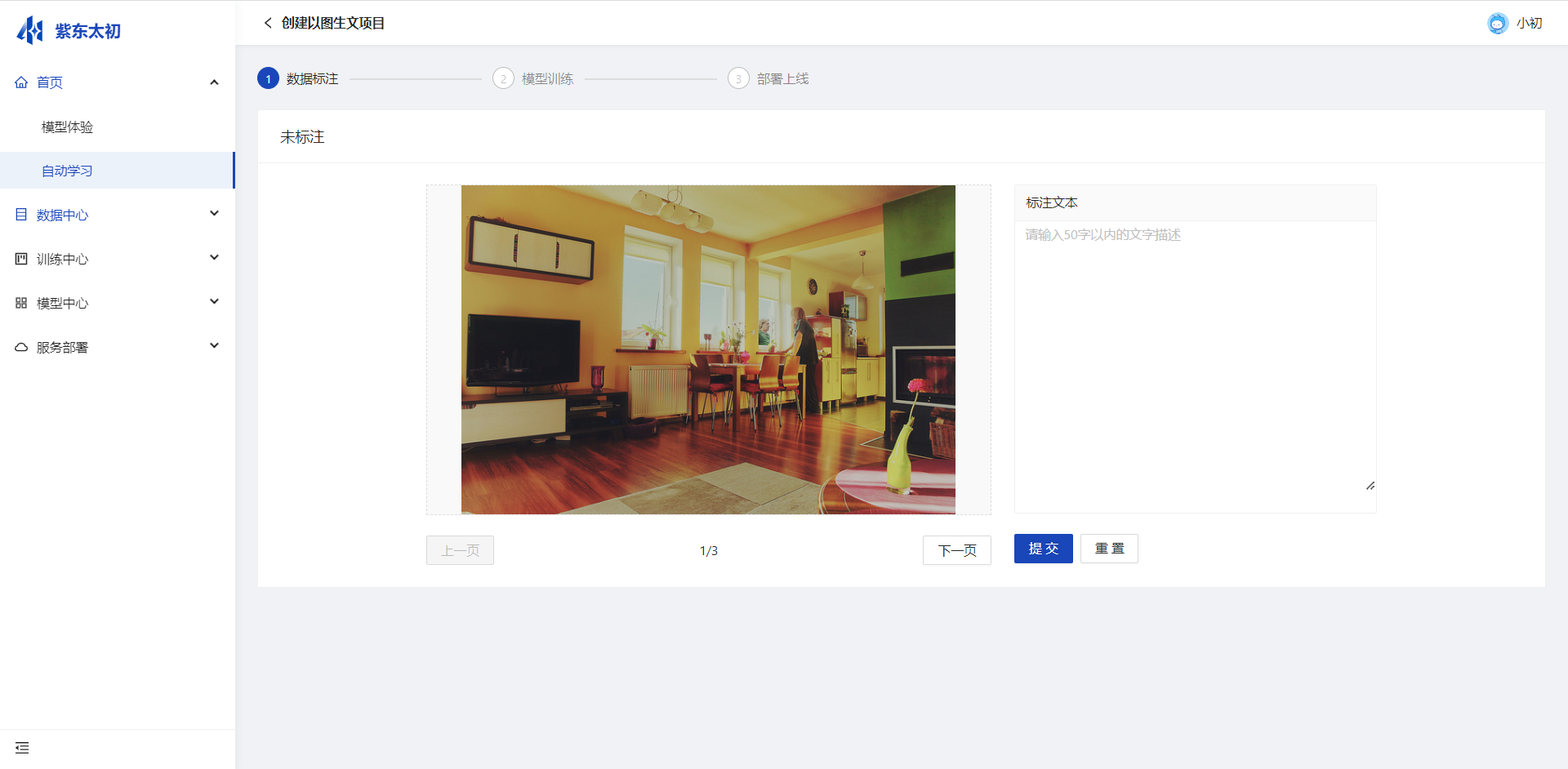
自动学习任务详情
数据集标注完成后可发起模型训练操作,点击“开始训练”自动选择相应资源池和资源规格创建训练任务,并实时打印任务日志,展示资源占用信息,用户可选的资源信息根据平台实际运行环境中硬件资源展示。
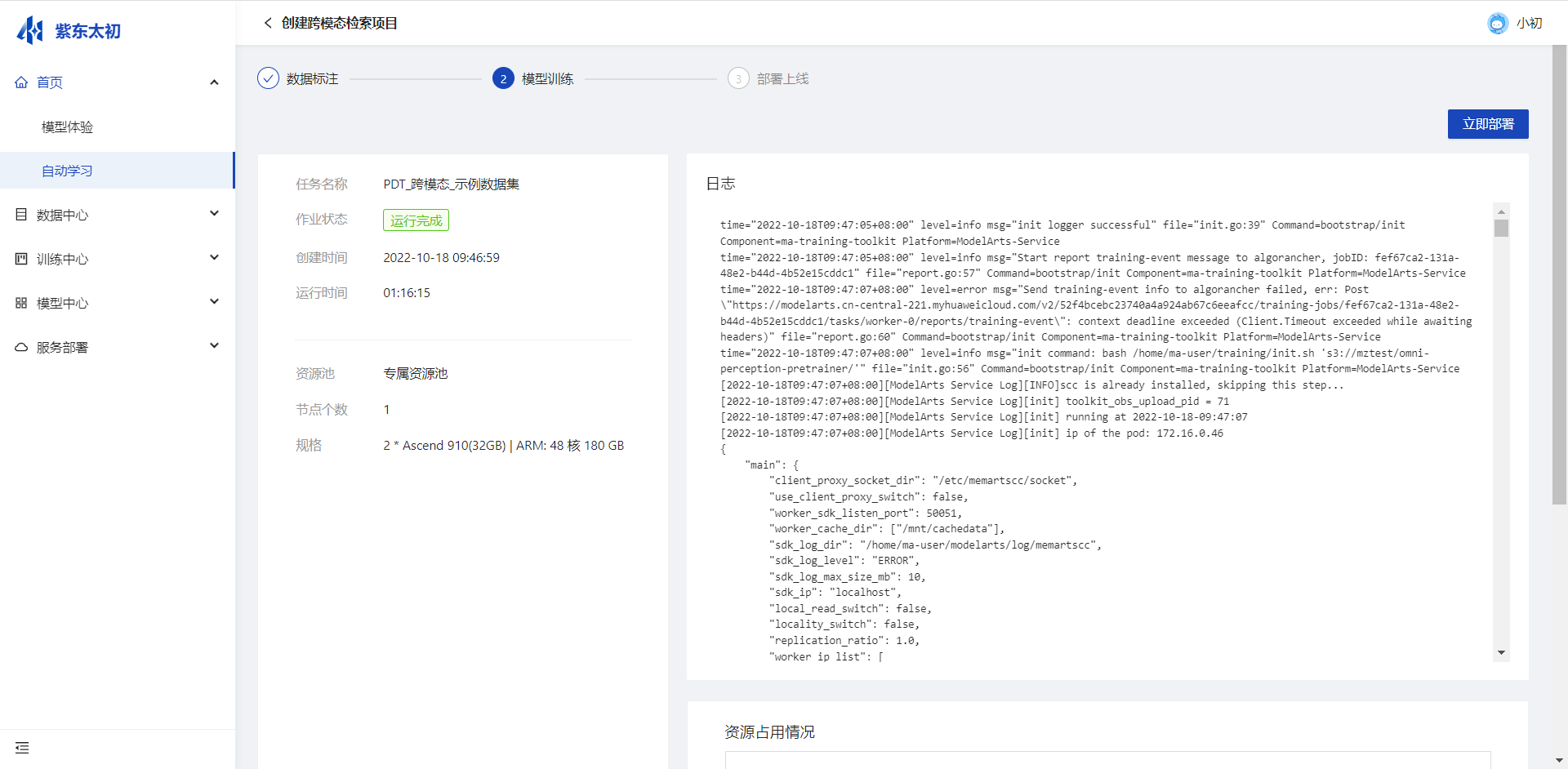
任务输出模型部署
模型部署的操作是将模型部署为在线服务,并且提供在线测试的能力。完成模型训练后,可选择自动学习任务中结果较为理想且训练状态为“运行成功”的任务输出的模型部署上线。
a、在“自动学习任务列表”页面中,待训练状态变为“运行成功”,即可在任务详情中单击“立即部署”进行部署的操作,可将模型部署上线为在线服务。
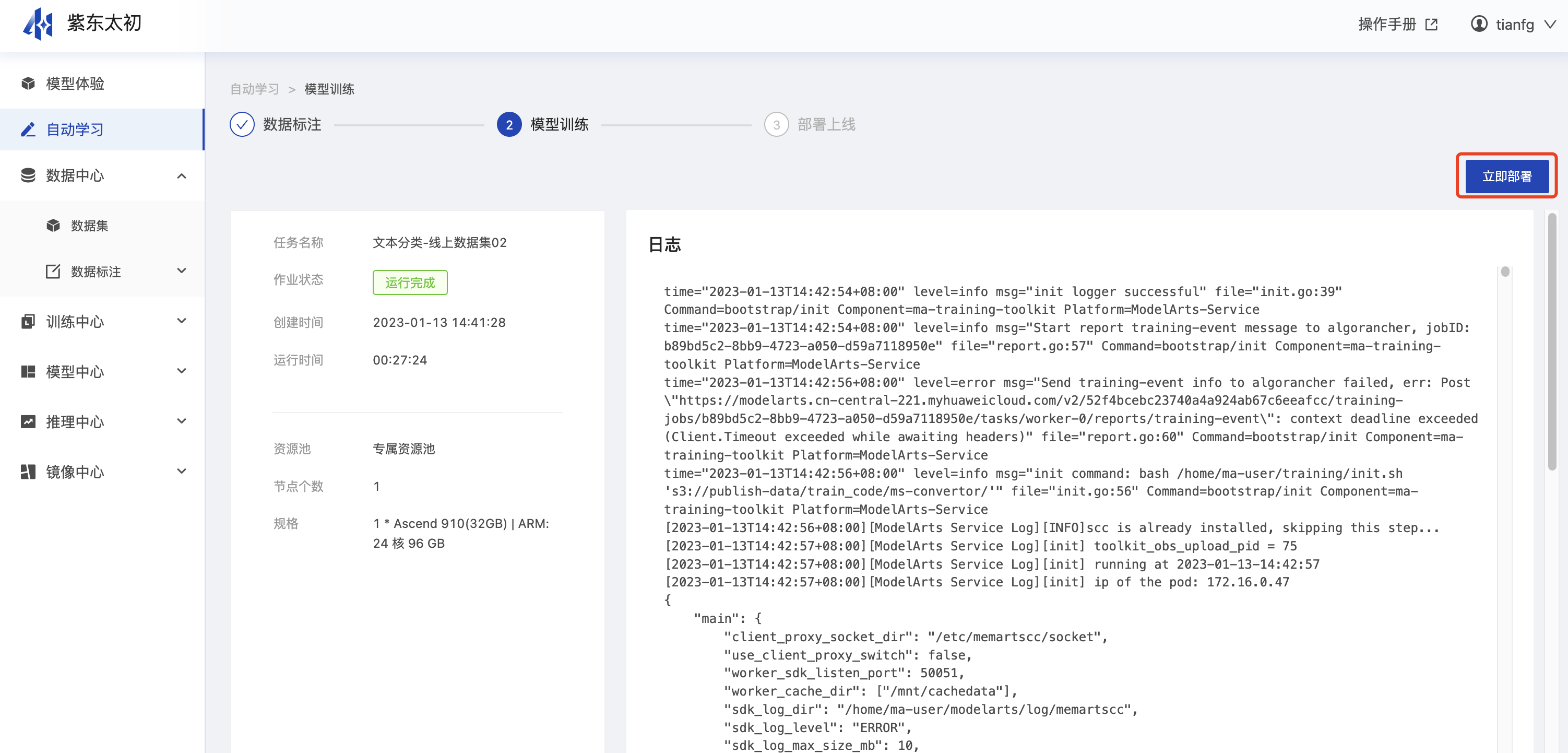
b、在弹出的部署页面中,选择资源规格,同时设置节点数等信息,然后单击“提交”,启动部署操作,为节约资源模型部署后1小时会自动停止。模型部署成功后,其部署状态为运行中,则操作栏可发起预测操作。
模型在线预测
部署成功任务支持在线预测的操作。可点击其操作栏中“预测”进入模型预测页面,用户可选择线上示例数据或上传本地数据发起推理操作,推理完成后输出相应的分析结果。
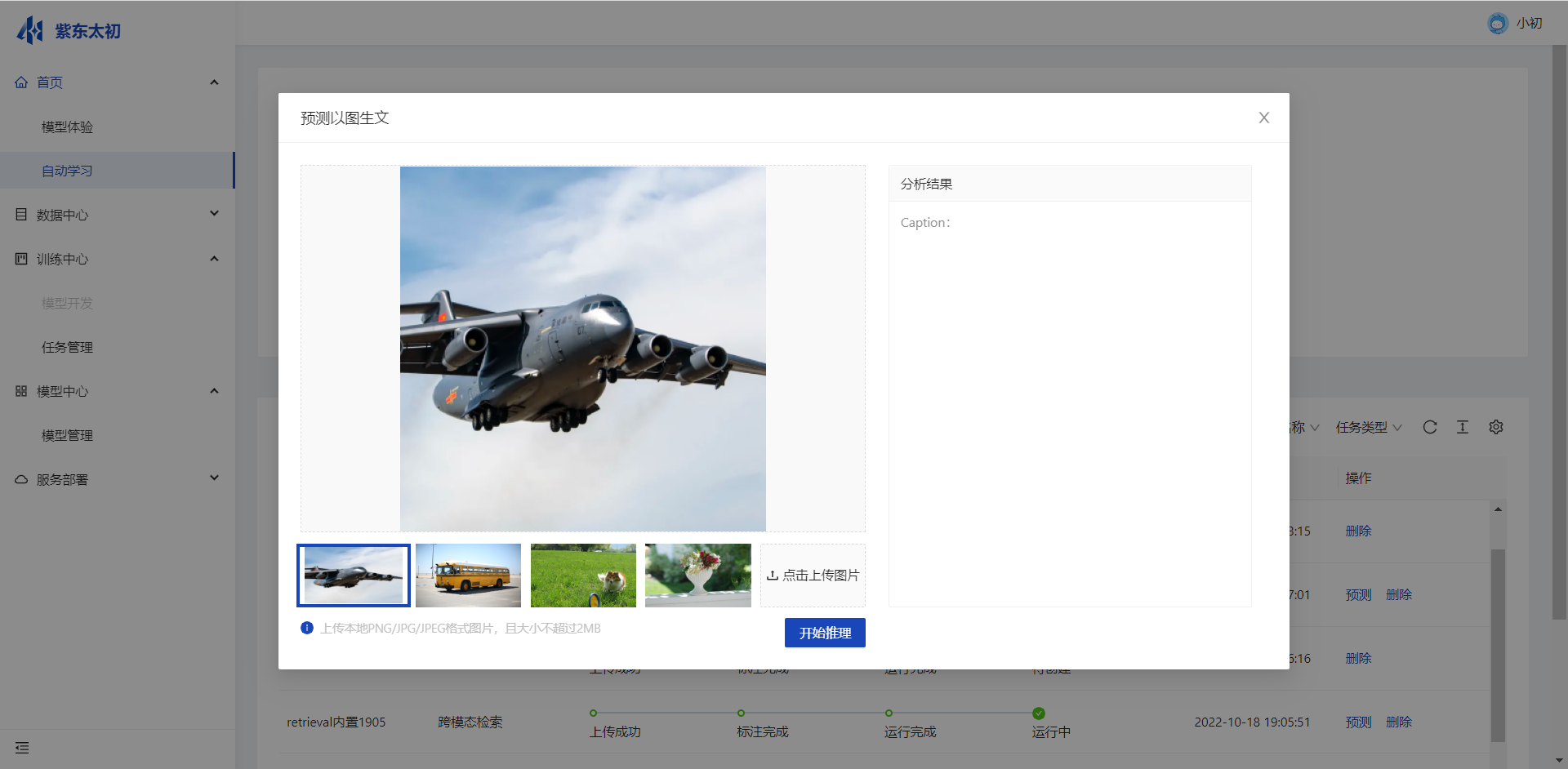
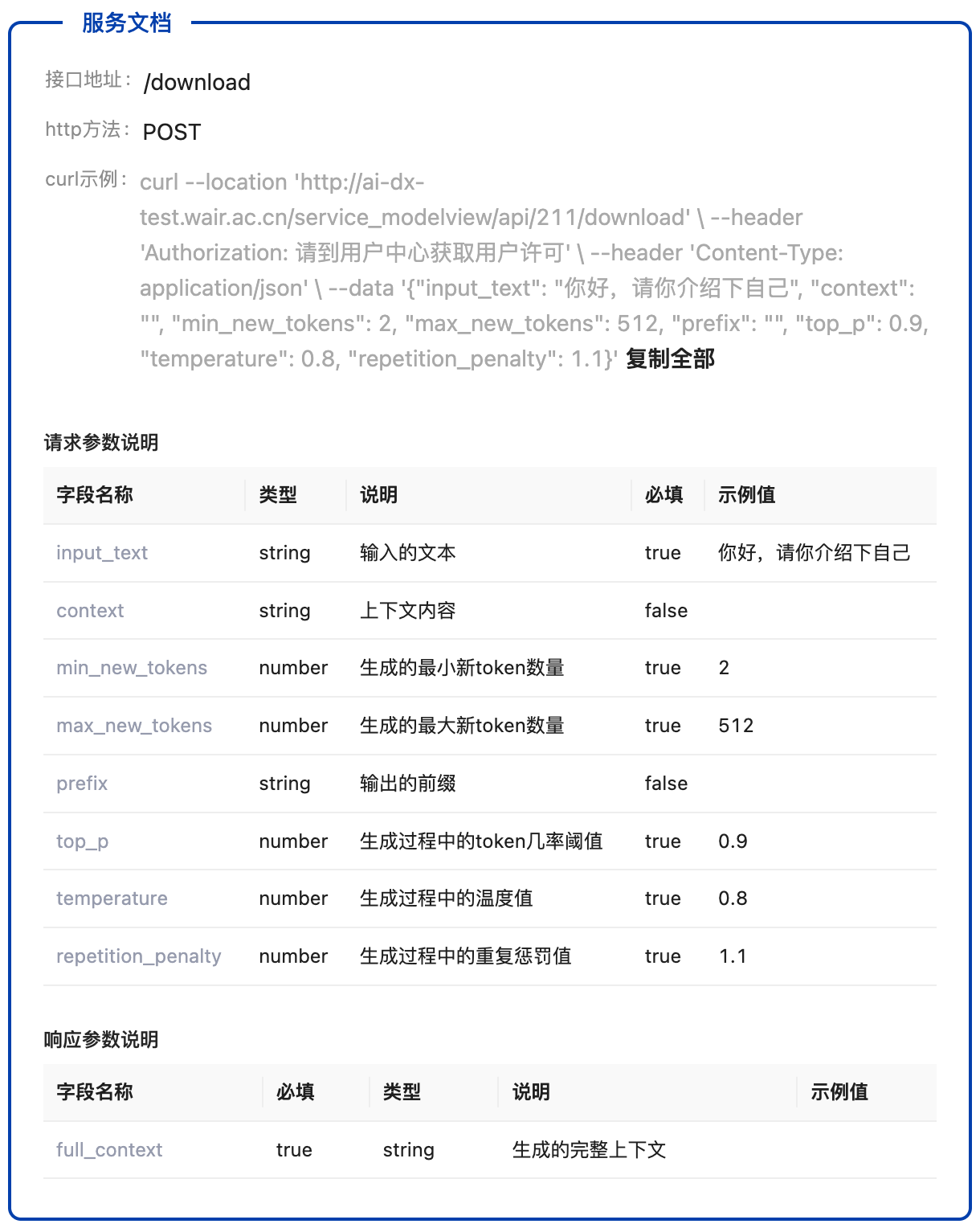
同时在推理页面中会展示服务文档相关的内容,展示接口地址,请求示例,以及请求、响应参数说明。
数据中心
数据中心主要有数据集管理、数据标注、智能标注、标签模板相关功能。用户可上传本地数据作为数据集,创建标注任务后,再对数据进行标注,标注完成后即可进行后续的模型训练操作。
数据集
数据集为数据的管理中心,支持数据集的增删改查,支持基于线下已标注、未标注的数据创建数据集,并支持线上的预览、修改和删除操作。点击页面右上角“添加数据集”按钮进入创建数据集页面,用户可基于自有数据选择数据类型、标注状态,添加数据后提交即可完成数据集的创建,创建成功后展示在数据集表单中。
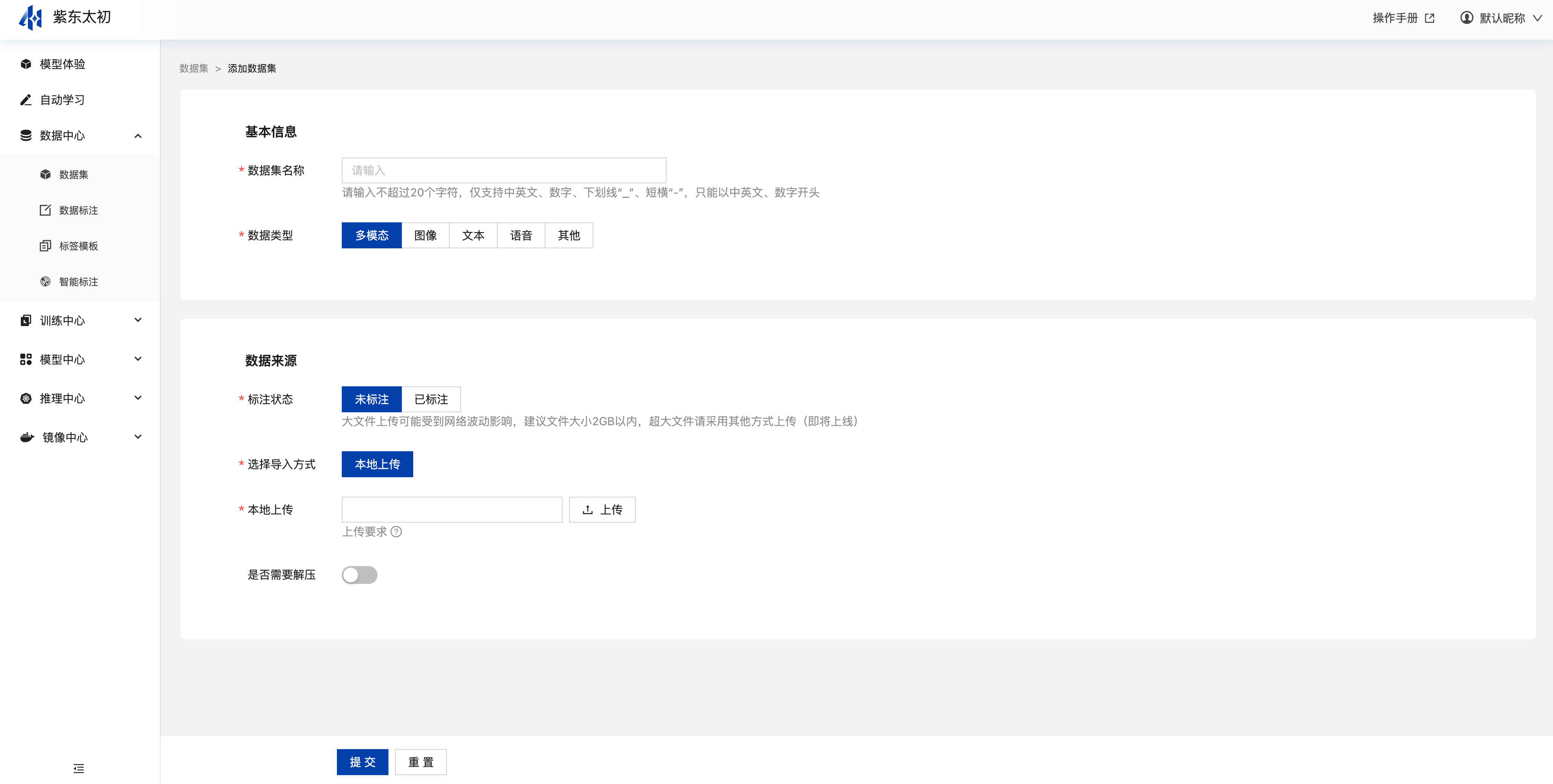
创建数据集参数说明:
| 参数名 | 参数说明 |
|---|---|
| 数据集名称 | 数据集名称:
|
| 数据类型 | 数据类型有多模态、图像、文本、语音、其他等类型。不同数据类型根据实际数据类型选择,例如做目标检测等数据通常为图片类型的数据。
|
| 标注状态 | 标注状态区分为“已标注”、“未标注”,选择“已标注”则后续无需标注流程,若选择“未标注”则后续需要对数据进行标注的操作。 |
| 导入方式 | 支持“本地上传”的方式导入数据。 |
已创建的数据集点击操作栏中“修改”可调整当前数据集的名称,点击操作栏“删除”二次确认后可删除当前数据集。
点击数据集名称可查看当前数据集基本信息和数据来源。

点击操作栏中“预览”可以文件目录的形式查看当前数据集详细数据。
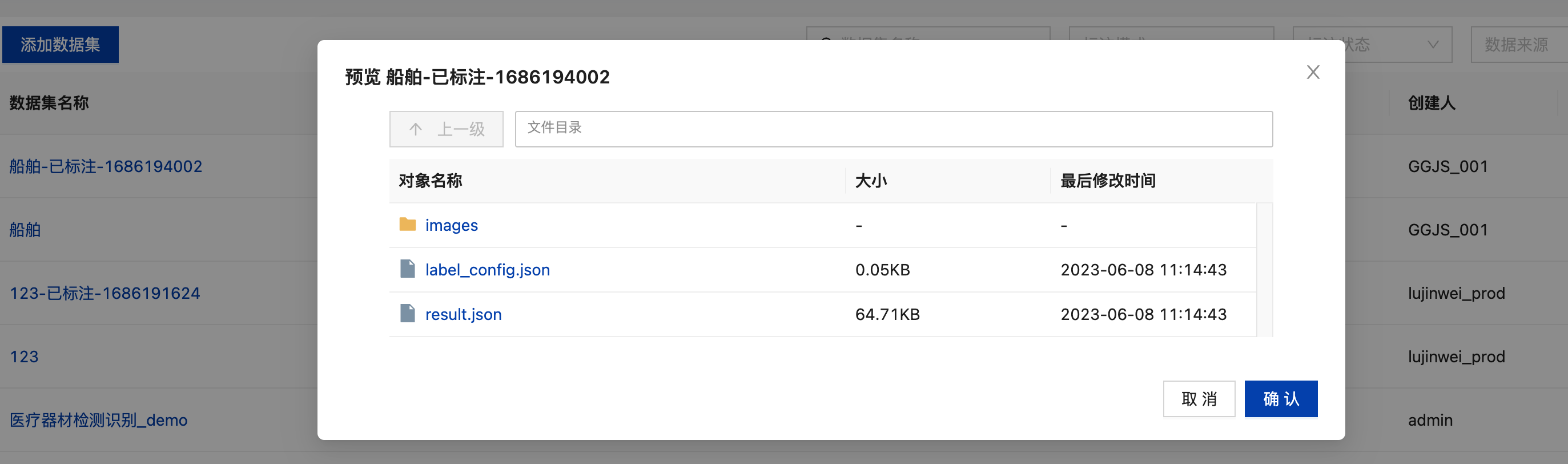
数据标注
线下上传至系统中未标注的数据可在线上数据标注中完成数据标注任务的标注,点击“添加任务”在基础信息中填写任务名称、任务描述(非必填),任务配置中选择标注模板、数据集后配置标签即可点击“提交”创建标注任务。
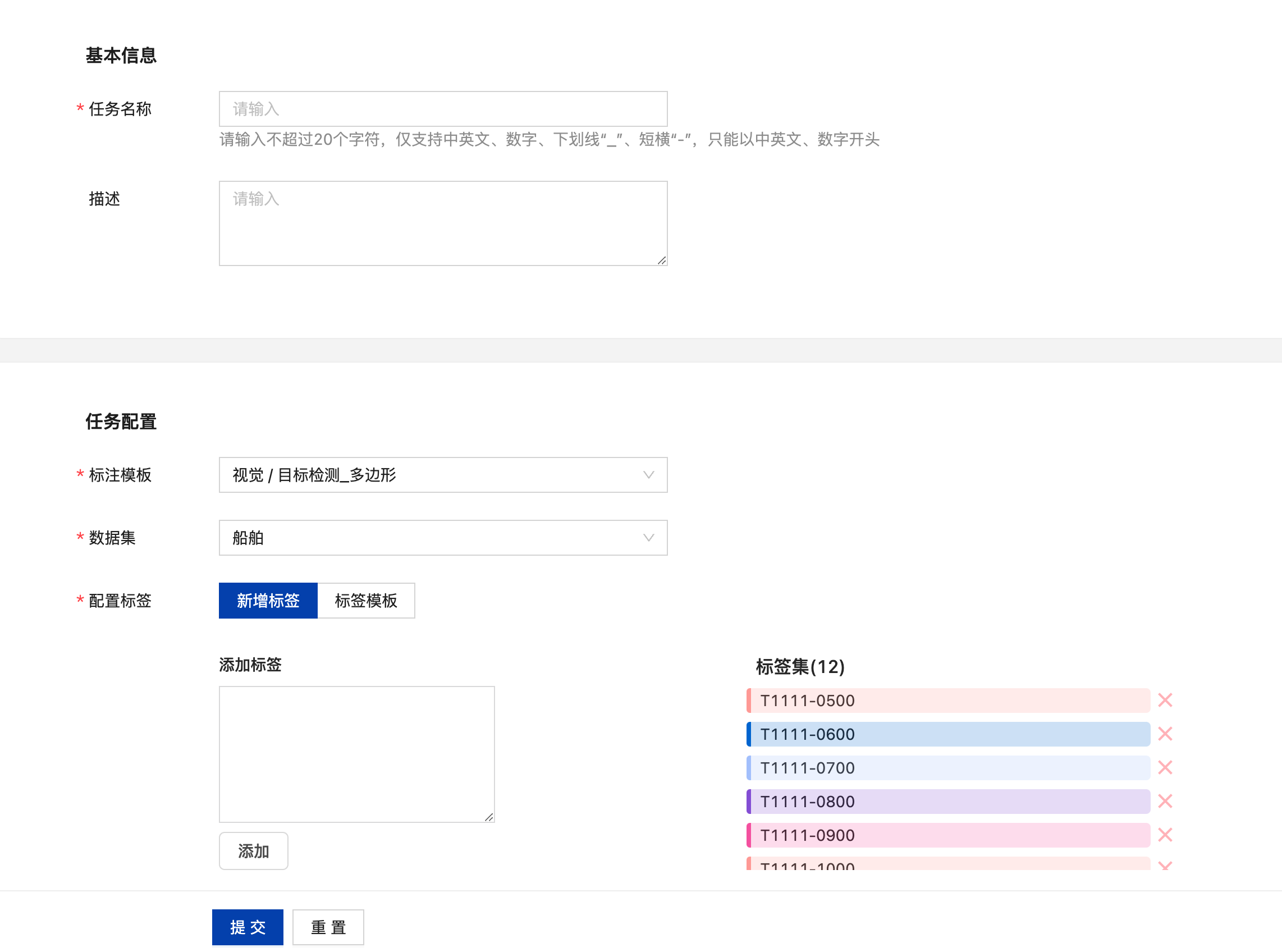
已创建的标注任务可点击任务名称查看任务信息,并支持标注和删除当前标注任务。未标注完成,即数据状态为未开始和标注中的任务可在操作栏点击“标注”进入标注页面。

多模态-图像描述标注任务
创建图像描述标注任务
点击“添加任务”后填写任务名称,在任务配置中选择多模态-图像描述,再选择需要标注的数据集,点击“提交”即可创建标注任务。
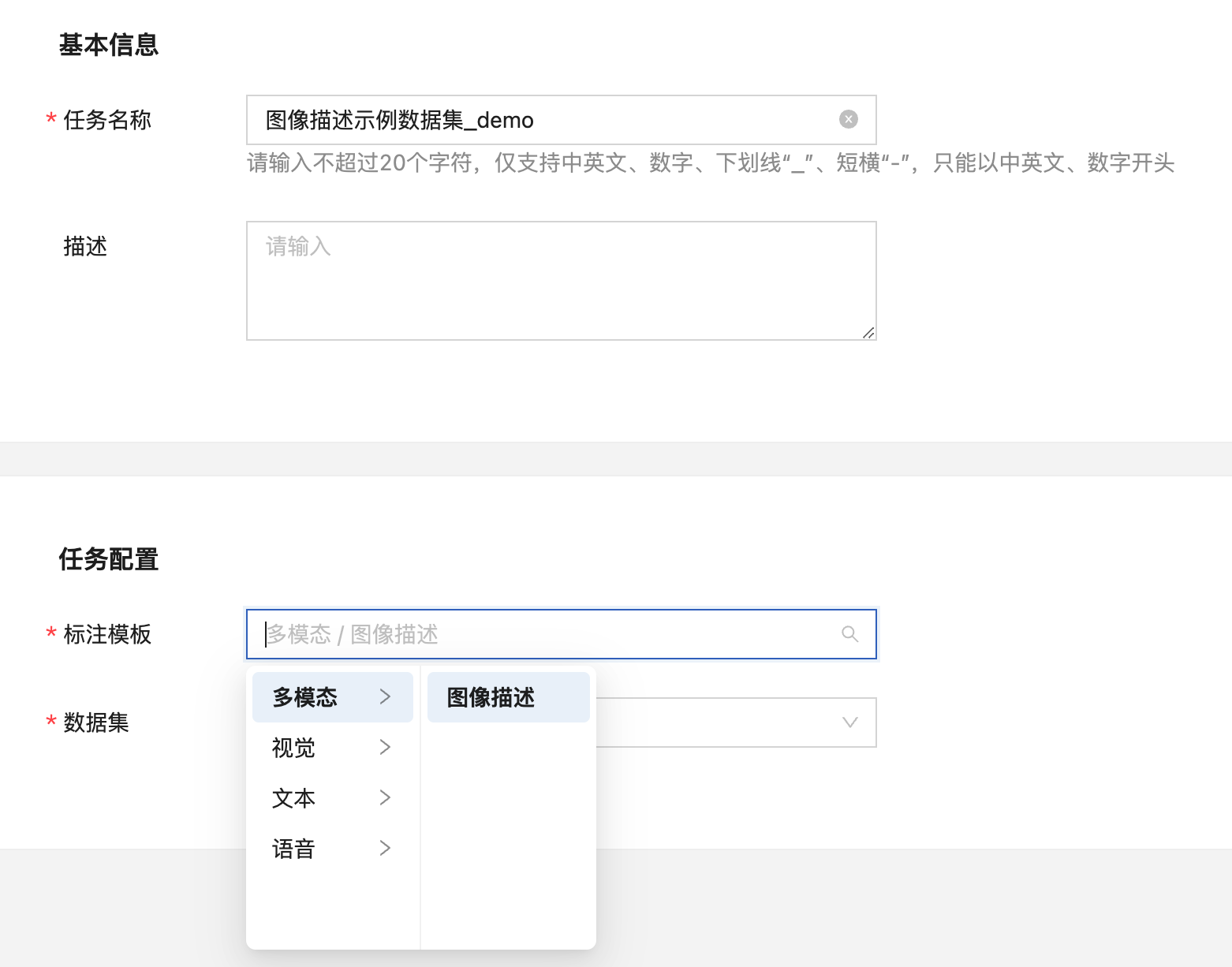
图像描述任务数据标注
创建完标注任务后,在其操作栏点击“标注”可进入标注页,在其无标注栏中可看到未标注的所有数据,在其“图像描述”文本输入框中输入图像描述信息,点击“添加”后保存当前标注即可完成当前图像的标注,保存后自动加载下一张图像。

多模态-图文问答标注任务
创建图文问答标注任务
点击“添加任务”后填写任务名称,在任务配置中选择多模态-图文问答,再选择需要标注的数据集,点击“提交”即可创建标注任务。
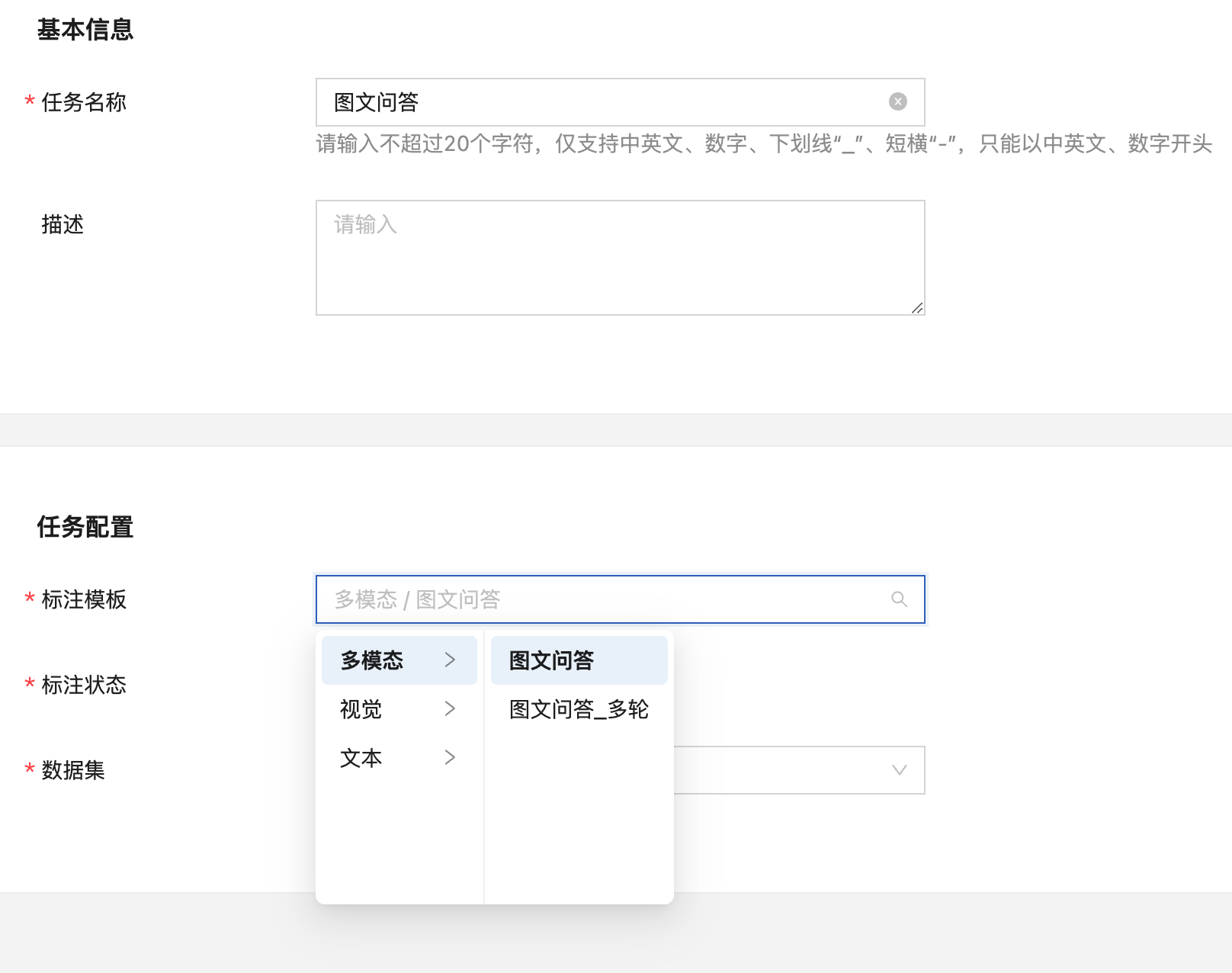
图像描述任务数据标注
创建完标注任务后,在其操作栏点击“标注”可进入标注页,在其无标注栏中可看到未标注的所有数据,在其“问题”文本输入框中输入图文问答中的问题信息,在其“答案”文本输入框中输入图文问答的答案信息,点击“保存当前标注”即可完成当前图像的标注,保存后自动加载下一张图像。
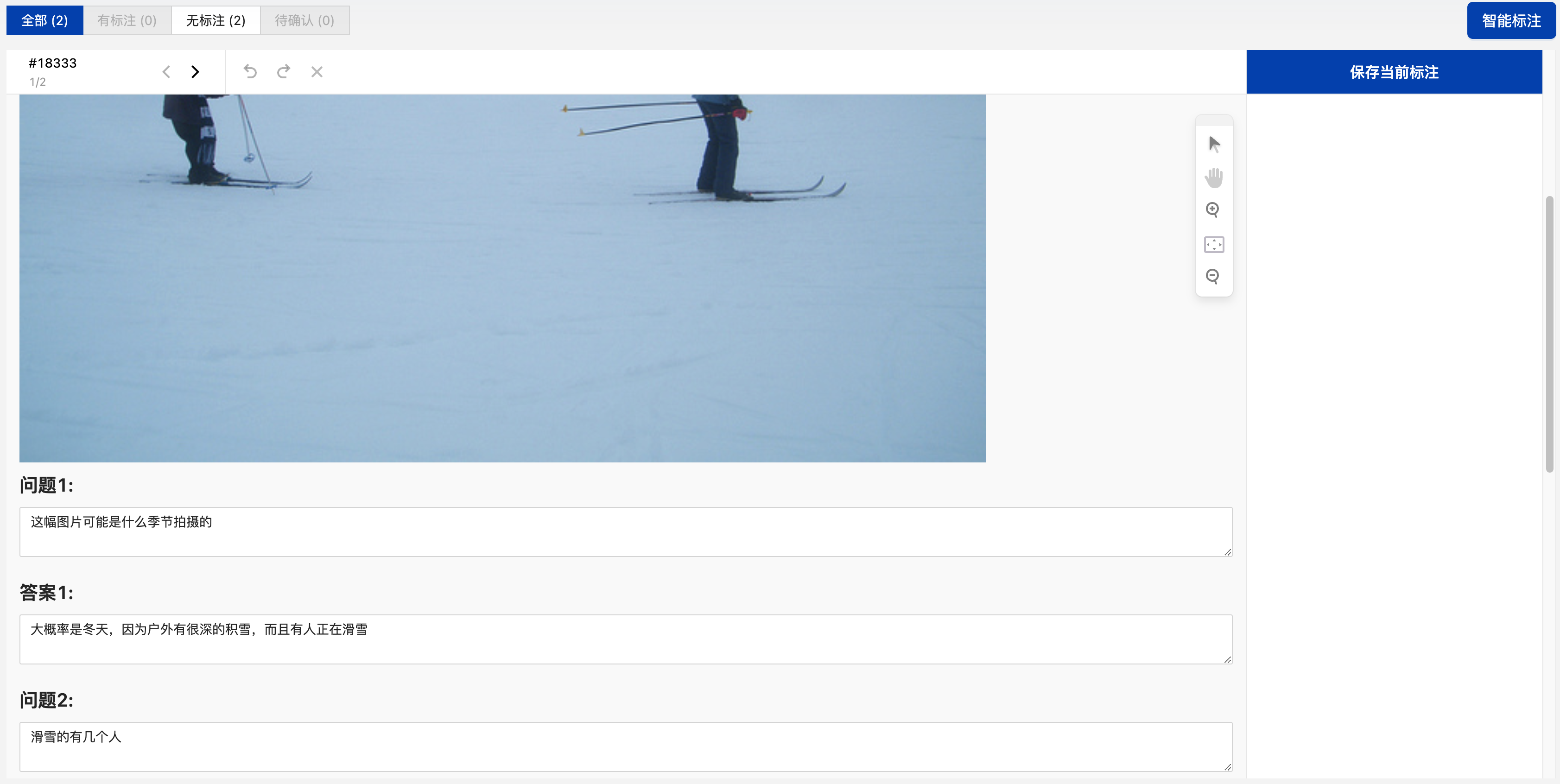
视觉-目标检测_矩形框标注任务
创建目标检测_矩形框标注任务
点击“添加任务”后填写任务名称,在任务配置中选择视觉-目标检测_矩形框,选择需要标注的数据集,再根据需要配置标签,输入标签名后,点击“添加”完成标签的添加,一亦可基于标签模板添加标签。点击“提交”即可创建标注任务。
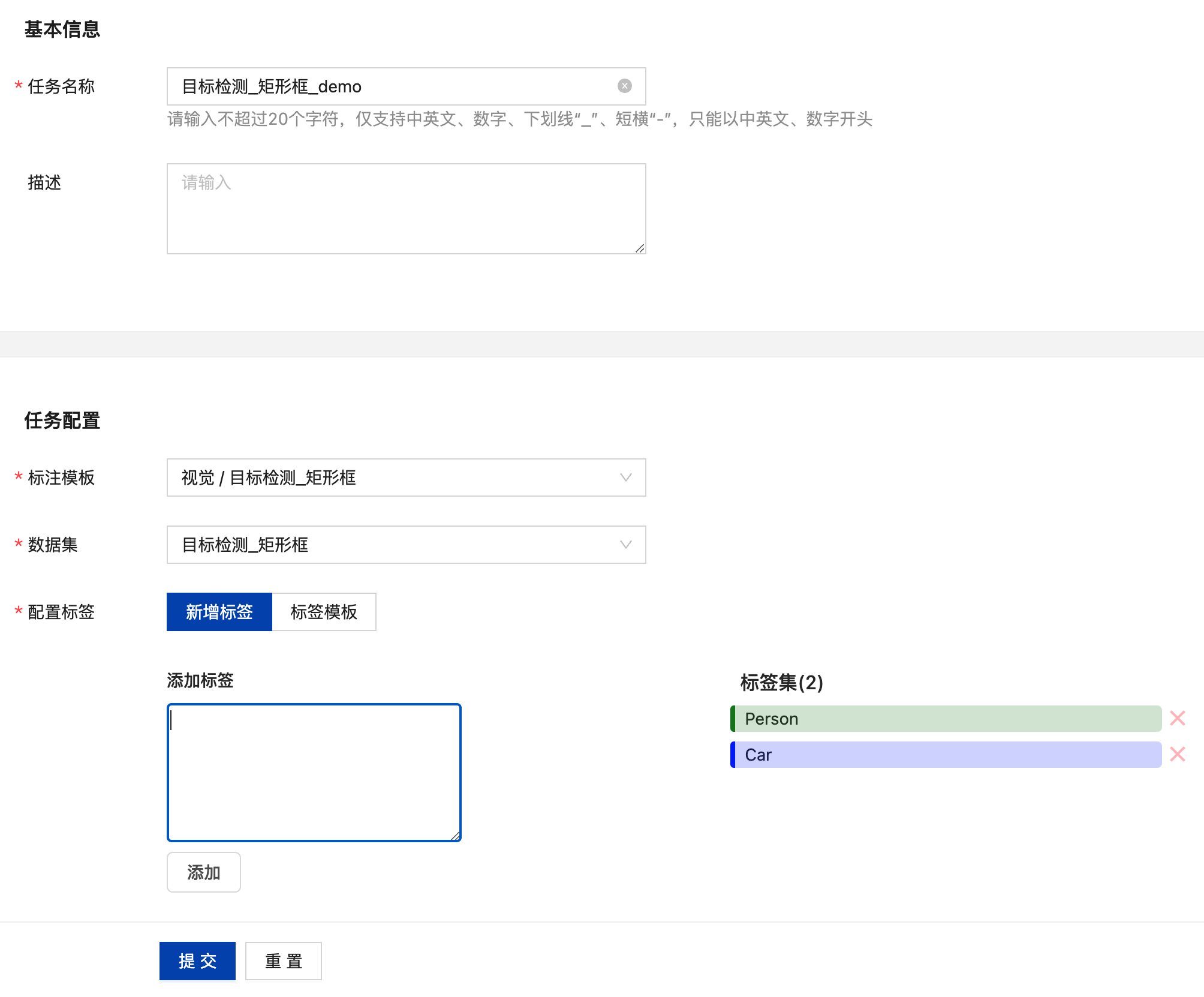
目标检测_矩形框任务数据标注
创建完标注任务后,在其操作栏点击“标注”可进入标注页,在其无标注栏中可看到未标注的所有数据,选择标签后在图像中绘制矩形框,即可完成当前目标的标注,标注完成后点击“保存当前标注”即可完成当前图像的标注,自动进入下一张图像的标注。

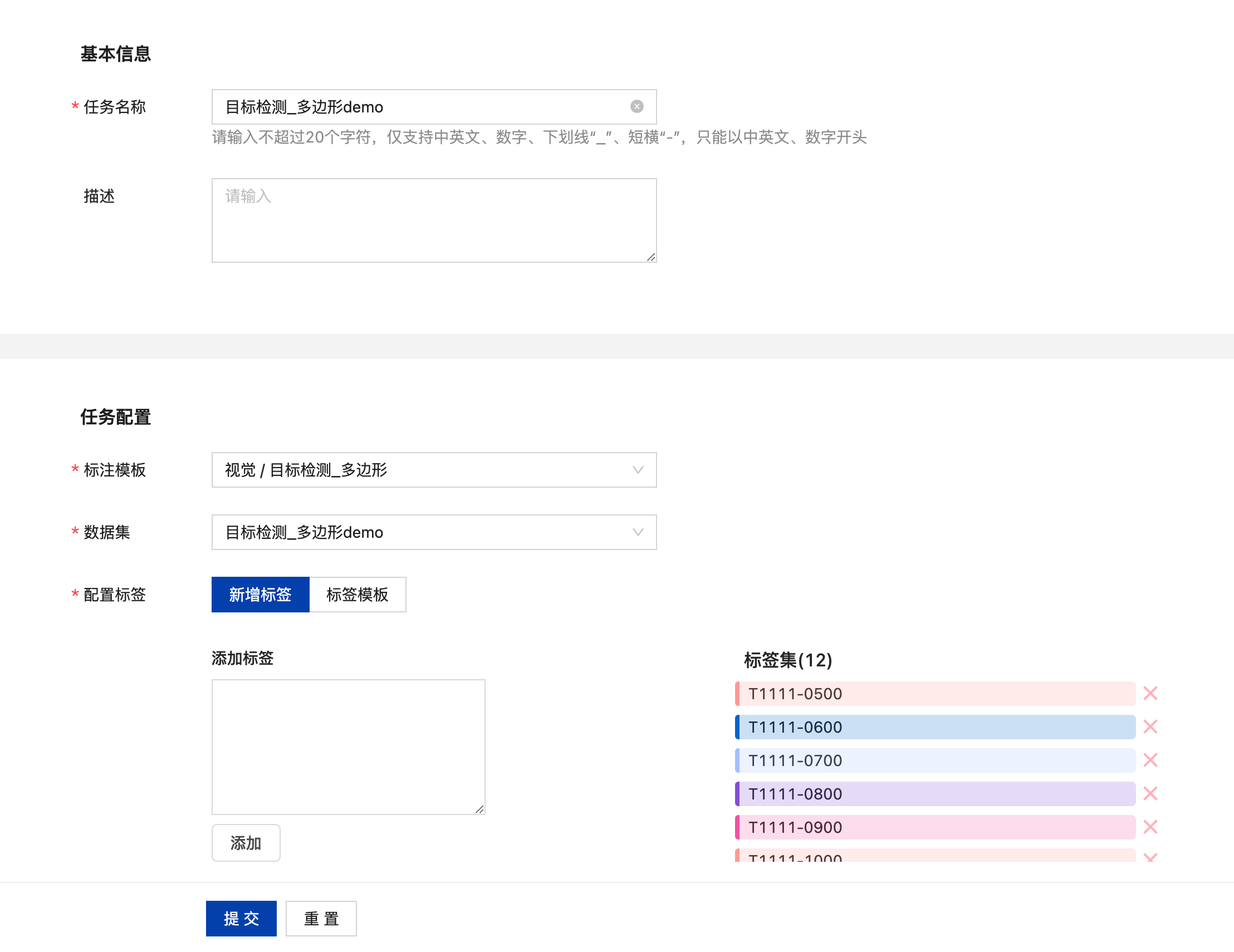
视觉-目标检测_多边形标注任务
创建目标检测_多边形标注任务
点击“添加任务”后填写任务名称,在任务配置中选择视觉-目标检测_多边形,选择需要标注的数据集,再根据需要配置标签,输入标签名后,点击“添加”完成标签的添加,亦可基于标签模板添加标签。点击“提交”即可创建标注任务。
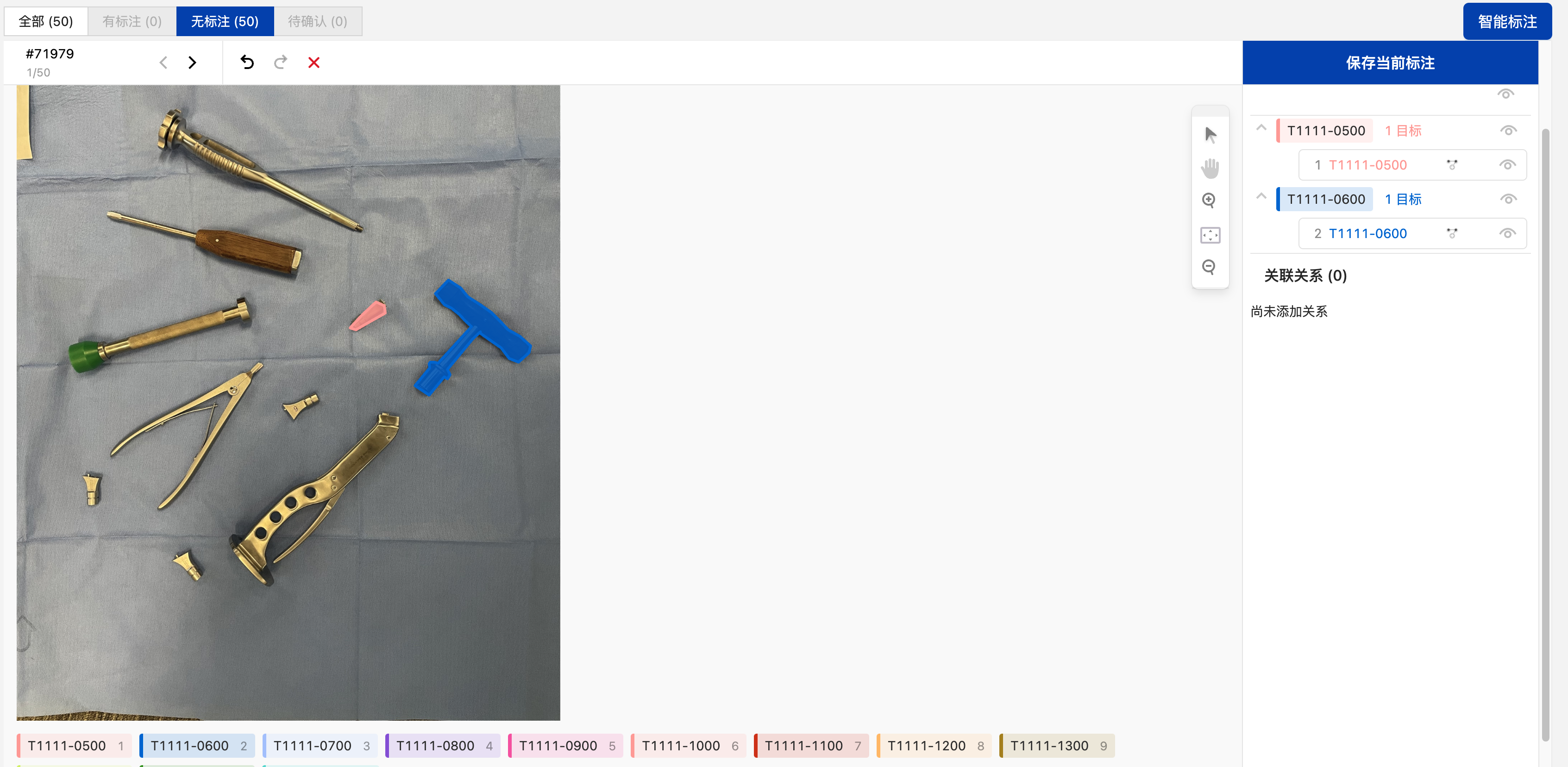
目标检测_多边形任务数据标注
创建完标注任务后,在其操作栏点击“标注”可进入标注页,在其无标注栏中可看到未标注的所有数据,选择标签后在图像中绘制多边形,即可完成当前目标的标注,标注完成后点击“保存当前标注”即可完成当前图像的标注,自动进入下一张图像的标注。
视觉-富文档信息抽取标注任务
创建目标检测_多边形标注任务
点击“添加任务”后填写任务名称,在任务配置中选择视觉-富文档信息抽取,选择需要标注的数据集,再根据需要配置标签,输入标签名后,点击“添加”完成标签的添加,亦可基于标签模板添加标签。
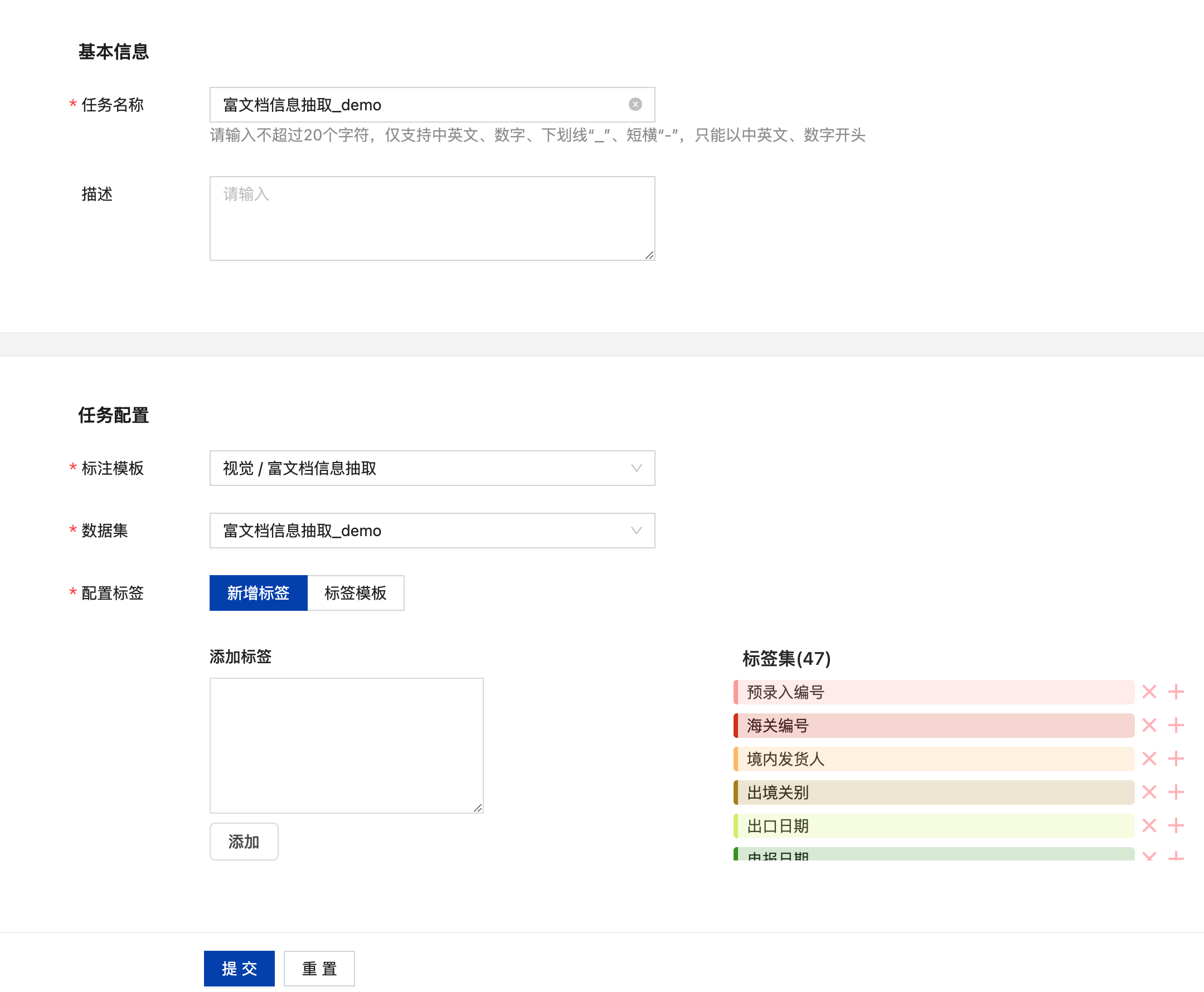
若需要进行关系抽取,则需要针对标签添加关系,点击标签集中标签后的“+”则可在添加关联关系,添加完成后点击“提交”即可创建当前标注任务。

富文档信息抽取任务数据标注
创建完标注任务后,在其操作栏点击“标注”可进入标注页,在其无标注栏中可看到未标注的所有数据,选择标签后在图片中绘制当前标签对应内容所在的位置进行标注,并配置其标签与标签之间的关系,若无关系则无需配置关系。
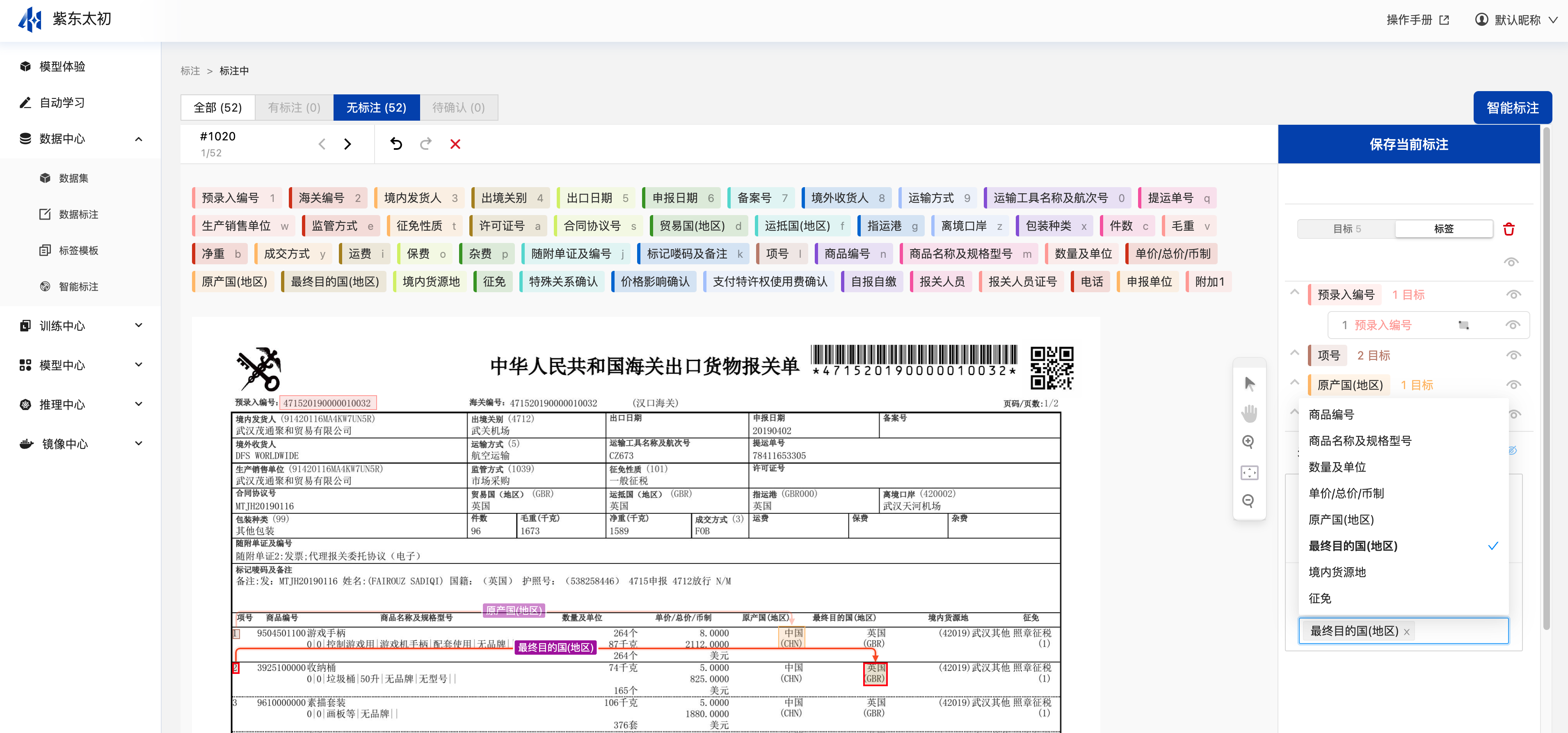
选择标签在图片中绘制当前标签对应内容所在的位置后,点击该位置的矩形框即可添加关联关系,点击“添加关联关系”按钮后,选择与其相关的目标,即可将其关联上。
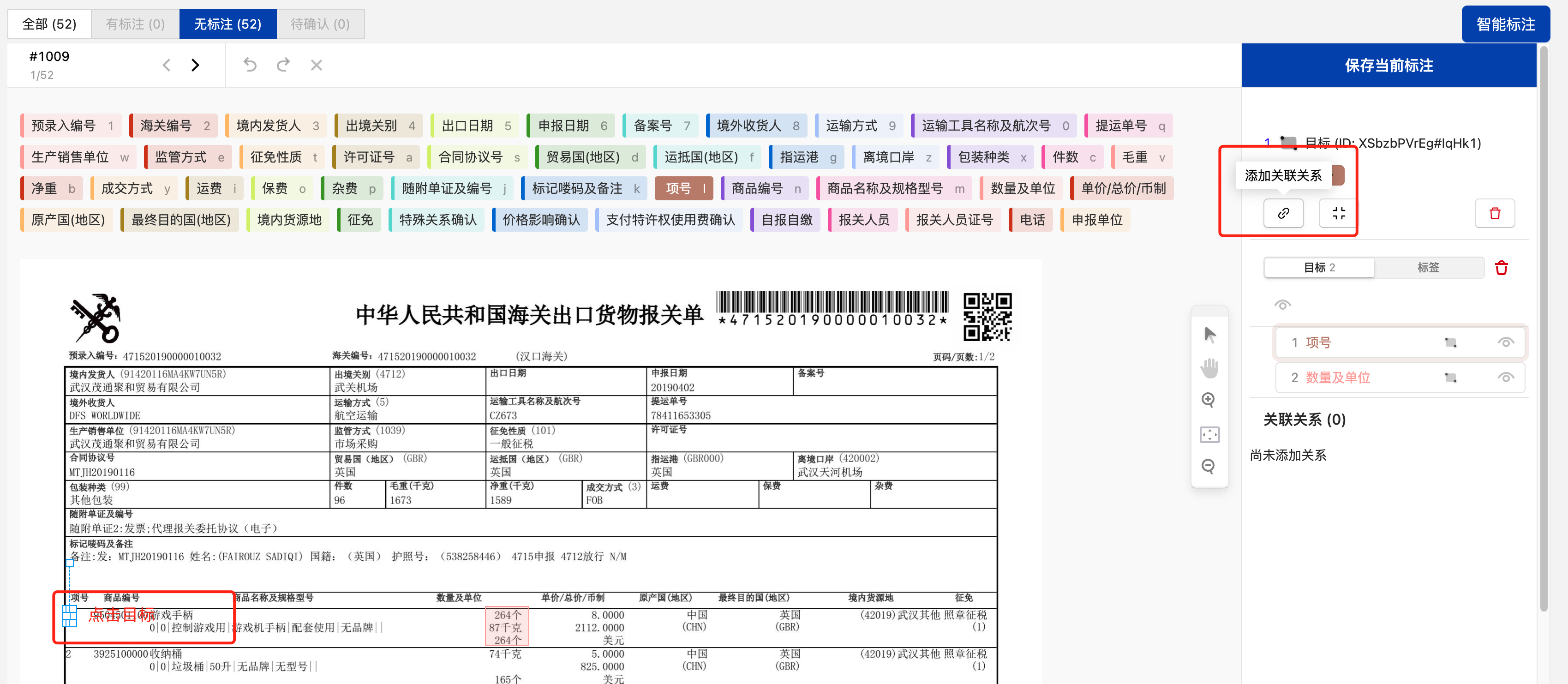
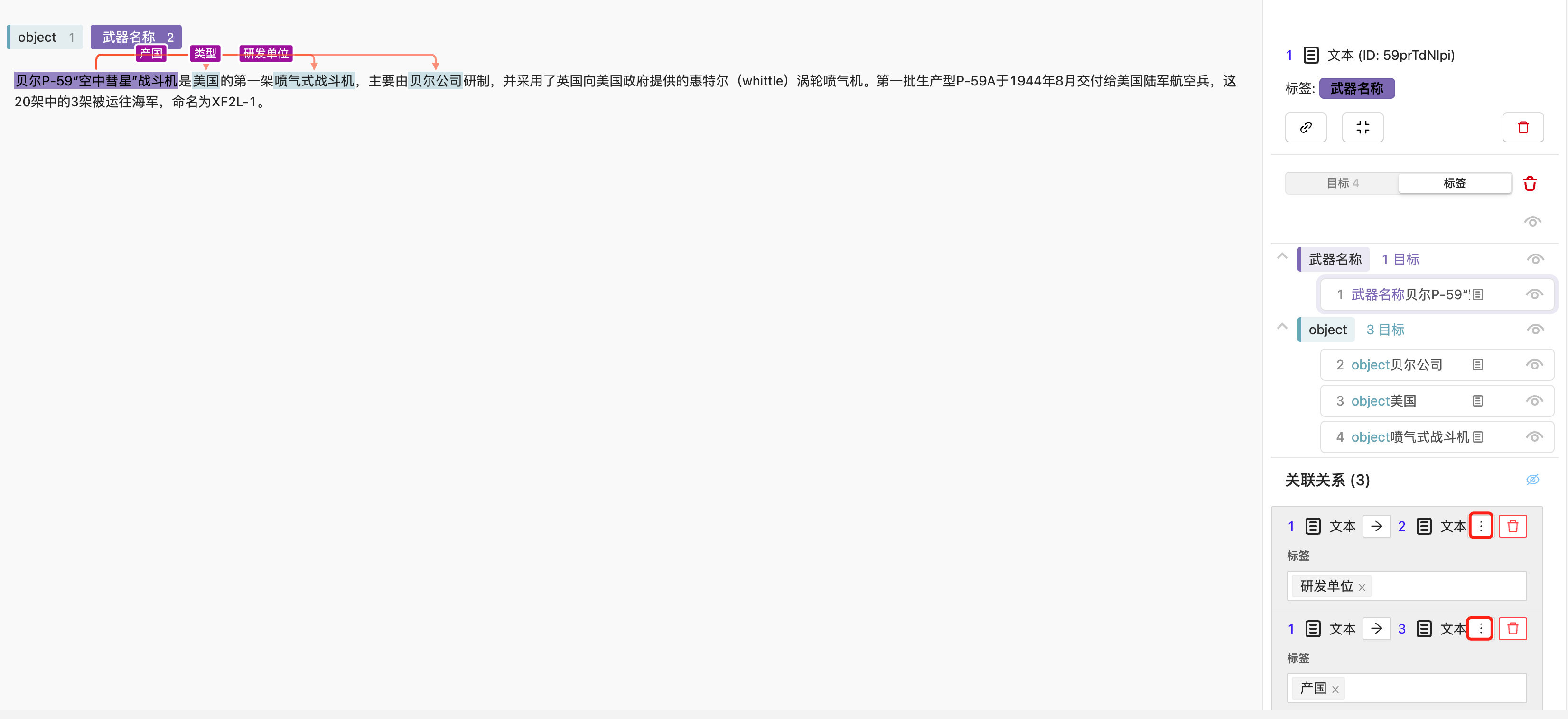
关联上关系后,需在其关联关系中选择其具体的关系标签,点击“⋮”图标,后在下拉列表中选择需要标注的关系标注完成后点击“保存当前标注”即可完成当前图像的标注,自动进入下一张图像的标注。
文本-实体关系抽取标注任务
创建实体关系抽取标注任务
点击“添加任务”后填写任务名称,在任务配置中选择文本-实体关系抽取,选择需要标注的数据集,再根据需要配置标签,输入标签名后,点击“添加”完成标签的添加,亦可基于标签模板添加标签。
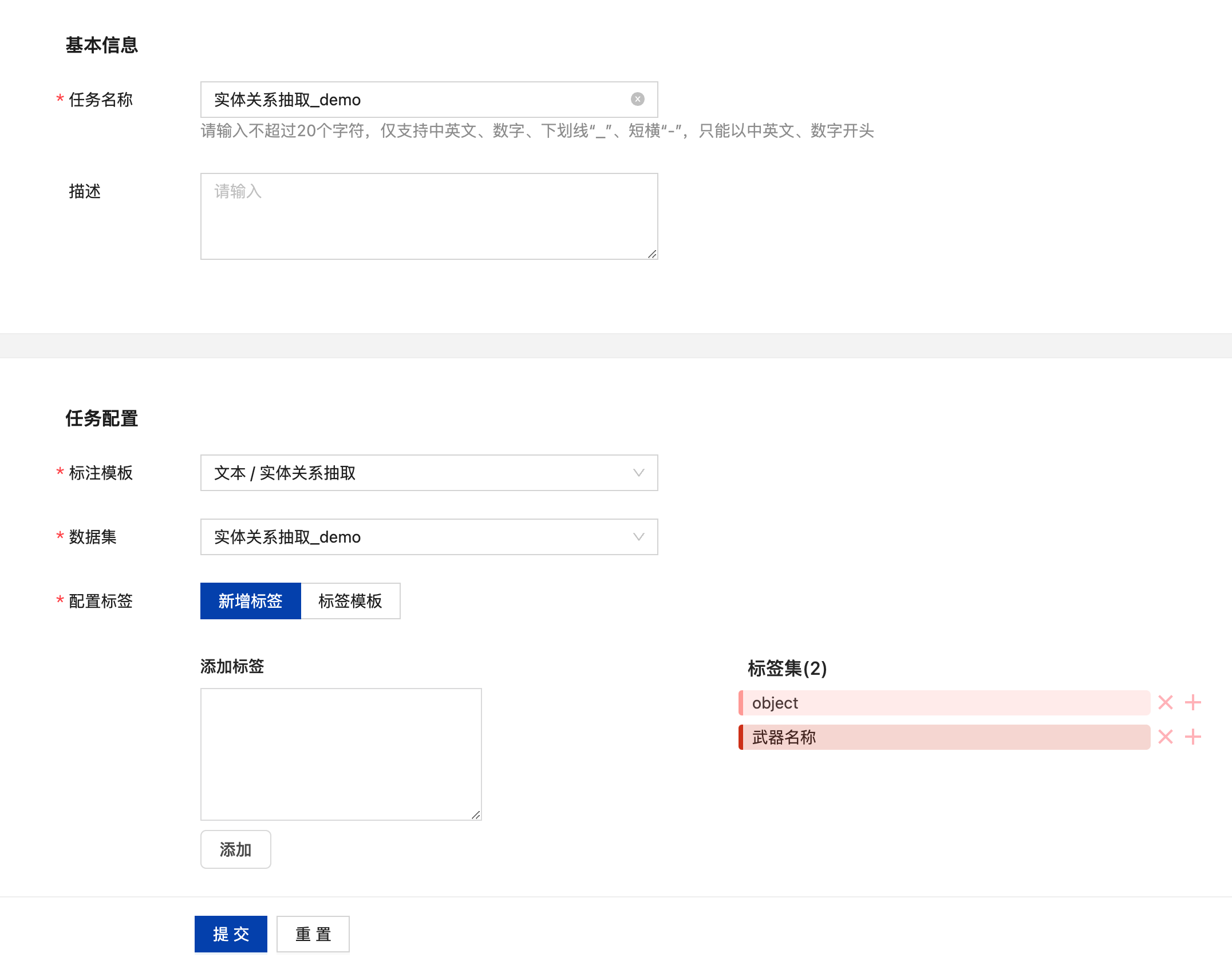
若需要进行关系抽取,则需要针对标签添加关系,点击标签集中标签后的“+”则可在添加关联关系,添加完成后点击“提交”即可创建当前标注任务。
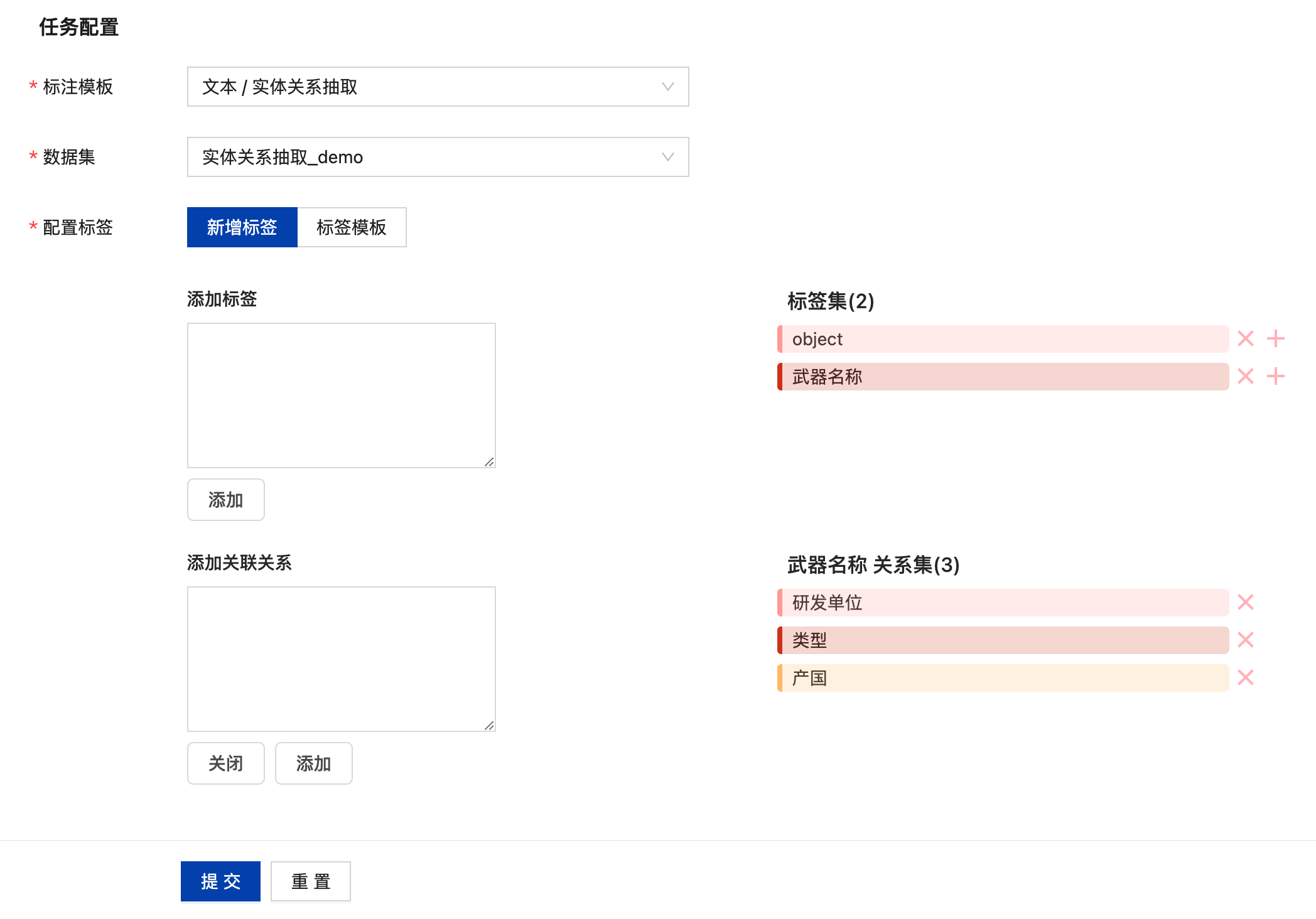
实体关系抽取任务数据标注
创建完标注任务后,在其操作栏点击“标注”可进入标注页,在其无标注栏中可看到未标注的所有数据,选择标签后,在短文本中选择该标签所对应的文字,实现文本目标的标注。
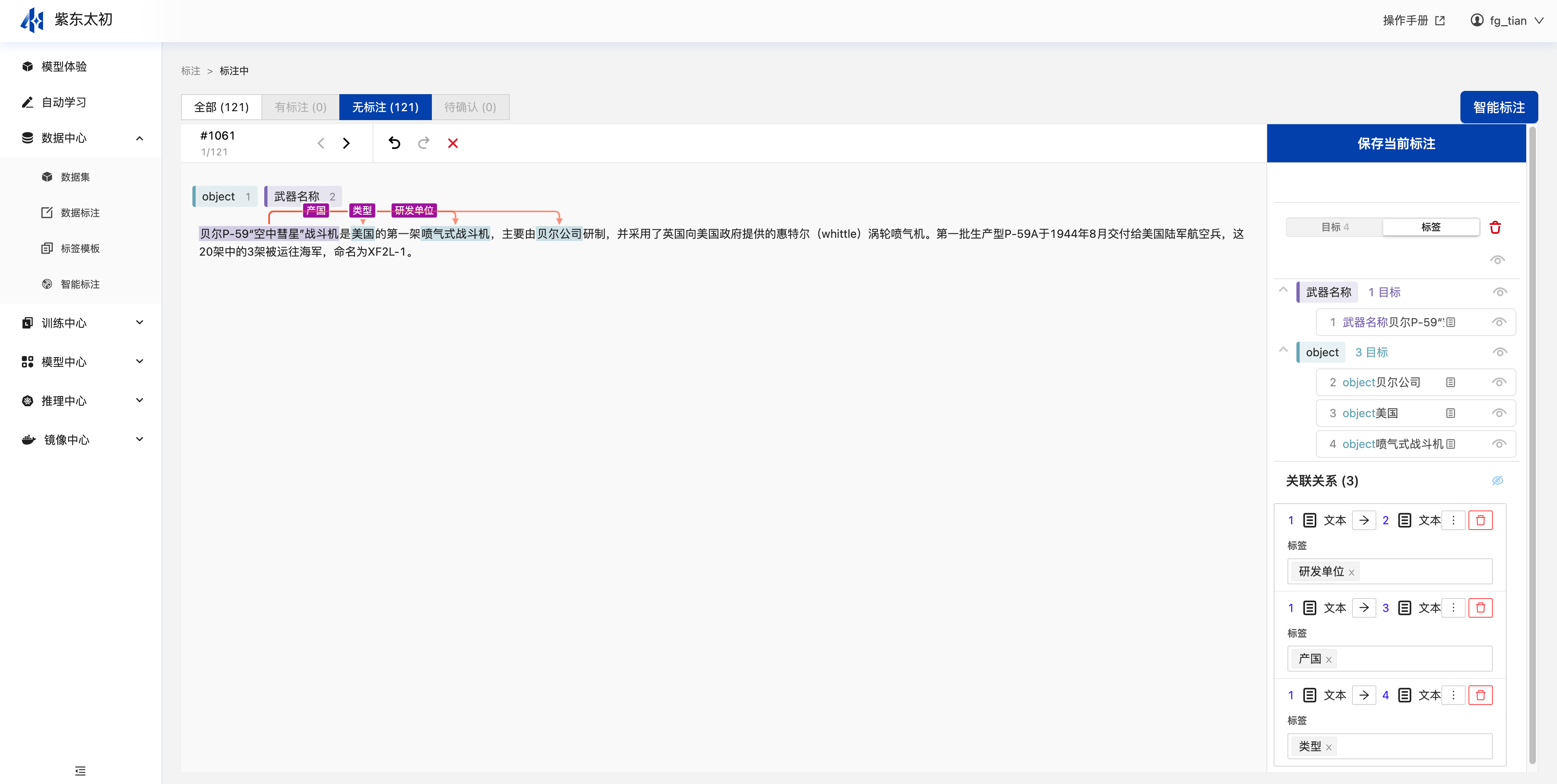
若需要标注关系,则可选择标签所对应的文本内容,并点击后即可添加关联关系,点击“添加关联关系”按钮后,选择与其相关的目标文本,即可将其关联上。
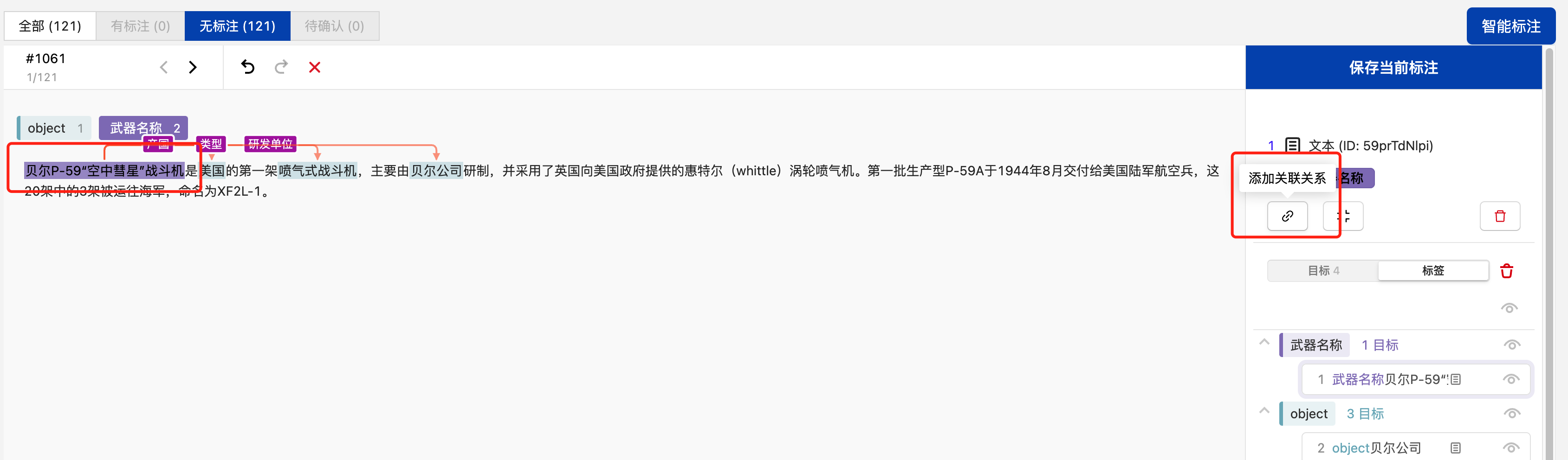
关联上关系后,需在其关联关系中选择其具体的关系标签,点击“⋮”图标,后在下拉列表中选择需要标注的关系标注完成后点击“保存当前标注”即可完成当前短文本的标注,自动进入下一条文本的标注。
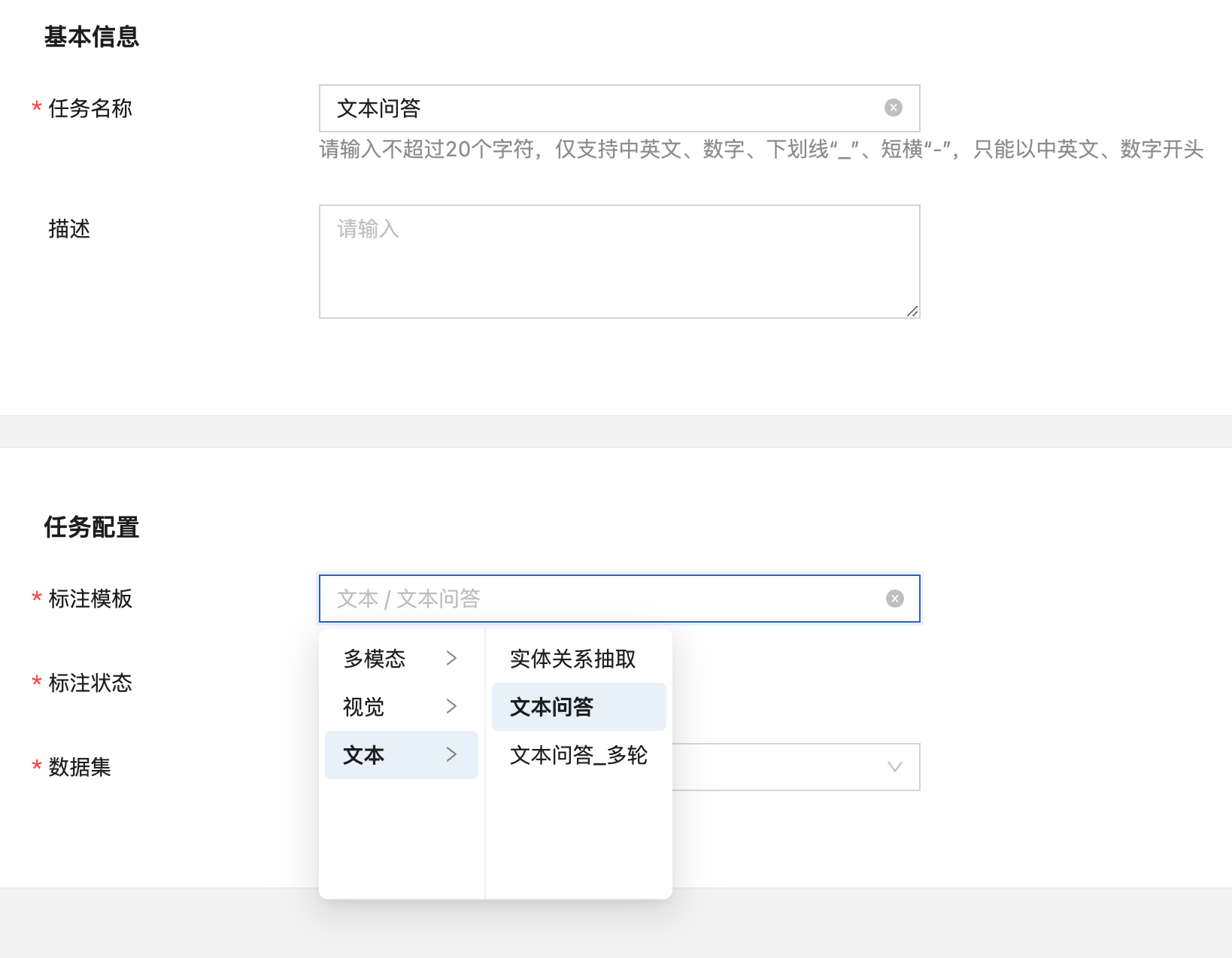
文本-文本问答标注任务
创建文本问答标注任务
点击“添加任务”后填写任务名称,在任务配置中选择文本-文本问答,再选择需要标注的数据集,点击“提交”即可创建标注任务。
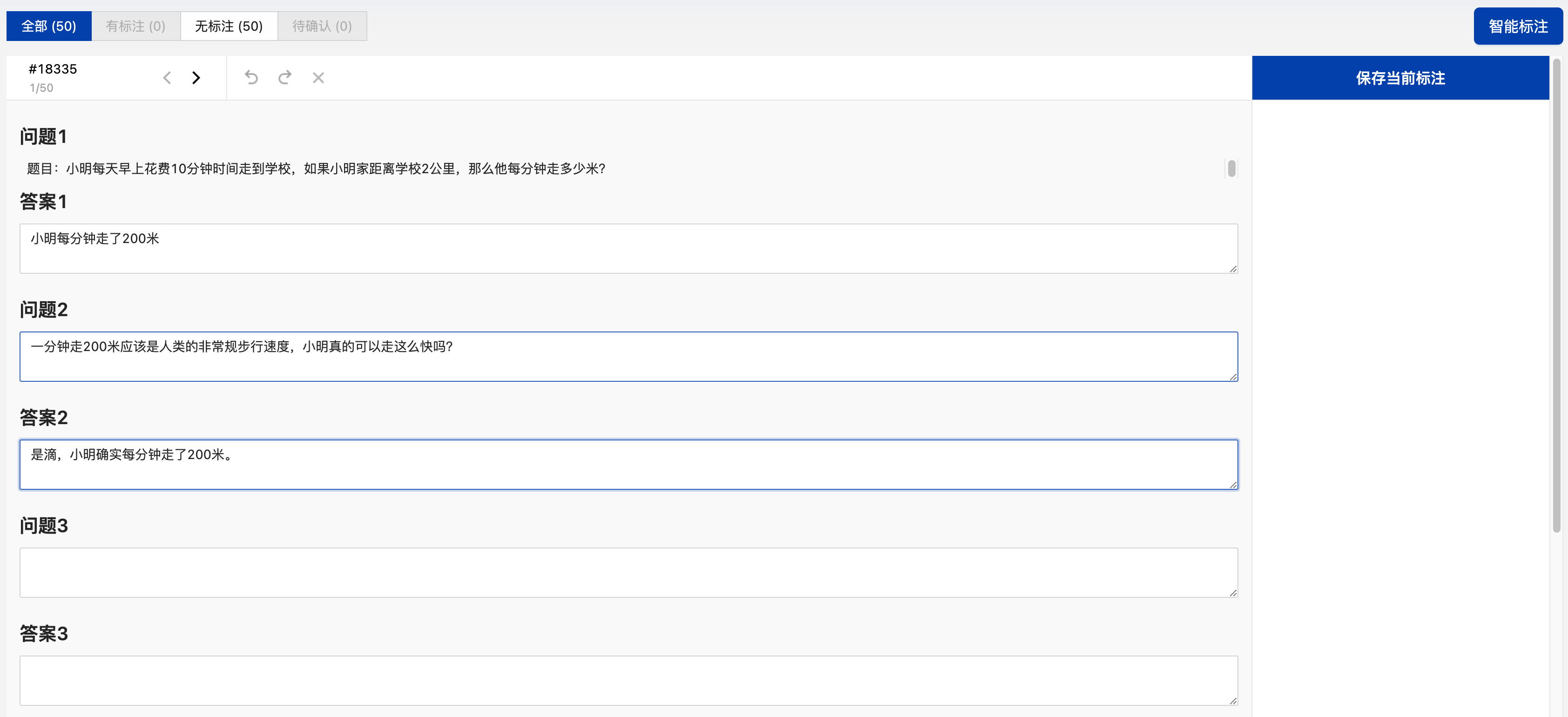
文本问答任务数据标注
创建完标注任务后,在其操作栏点击“标注”可进入标注页,在其无标注栏中可看到未标注的所有数据,在其“答案”文本输入框中输入文本问答的答案信息,点击“保存当前标注”即可完成当前文本数据的标注,保存后自动加载下一条文本数据。
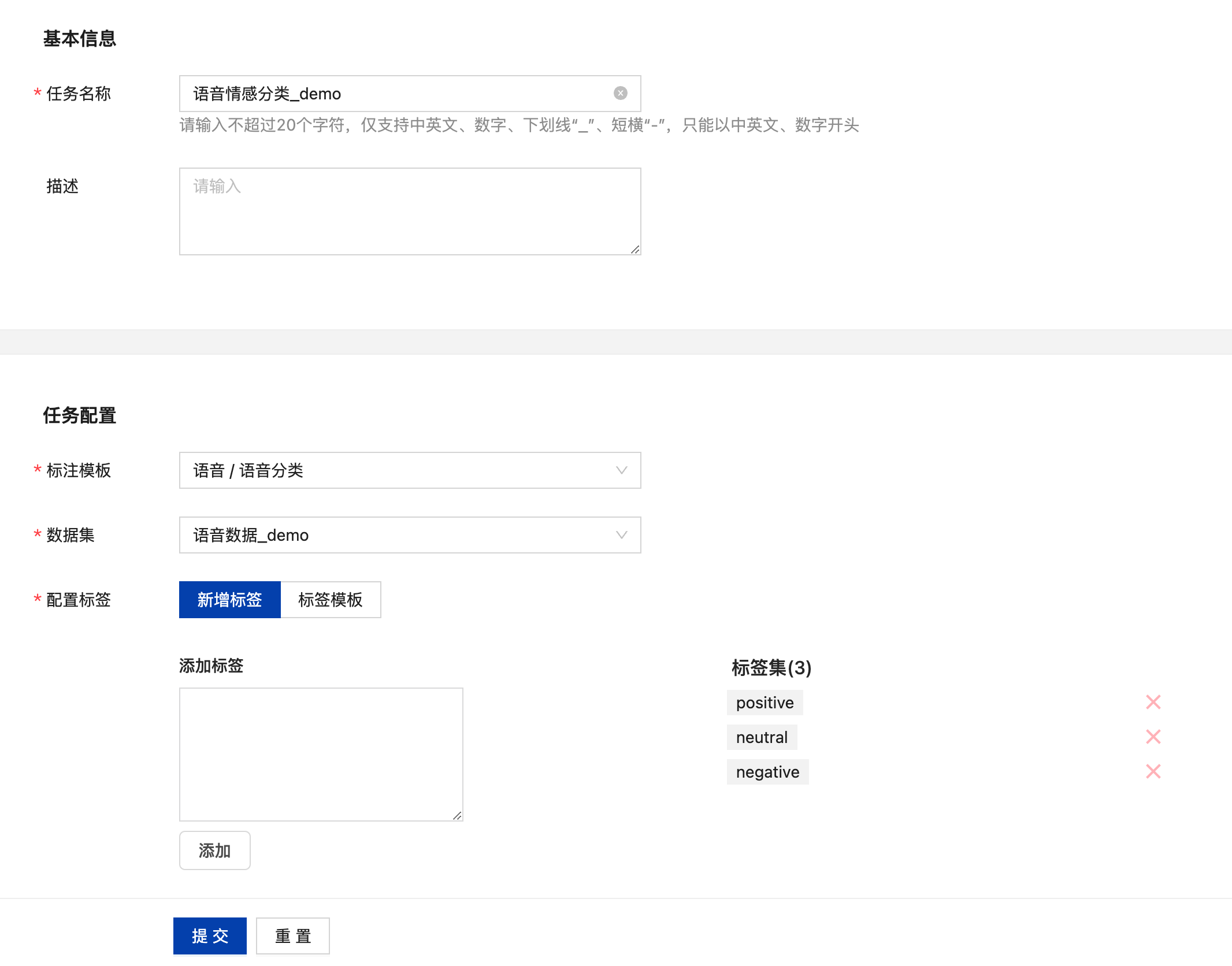
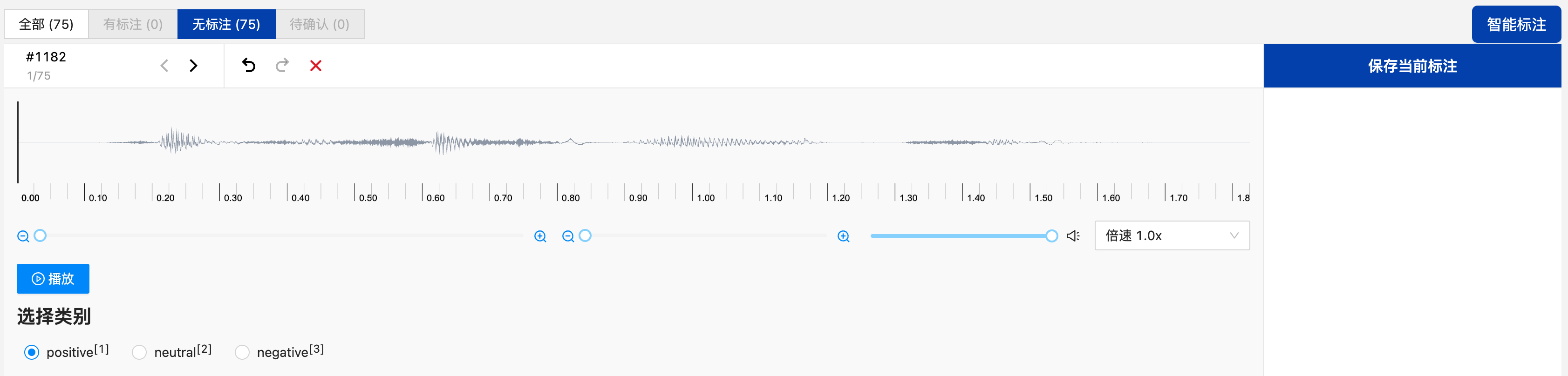
语音-语音分类标注任务
创建语音分类标注任务
点击“添加任务”后填写任务名称,在任务配置中选择语音-语音分类,选择需要标注的数据集,再根据需要配置标签,输入标签名后,点击“添加”完成标签的添加,亦可基于标签模板添加标签。点击“提交”即可创建标注任务。
语音分类任务数据标注
创建完标注任务后,在其操作栏点击“标注”可进入标注页,在其无标注栏中可看到未标注的所有数据,加载语音数据后可点击“播放”按钮播放当前的语音,根据语音内容选择对应的类别,即可实现当前数据的标注,标注完成后点击“保存当前标注”即可完成当前语音的标注,自动进入下一条语音数据的标注。
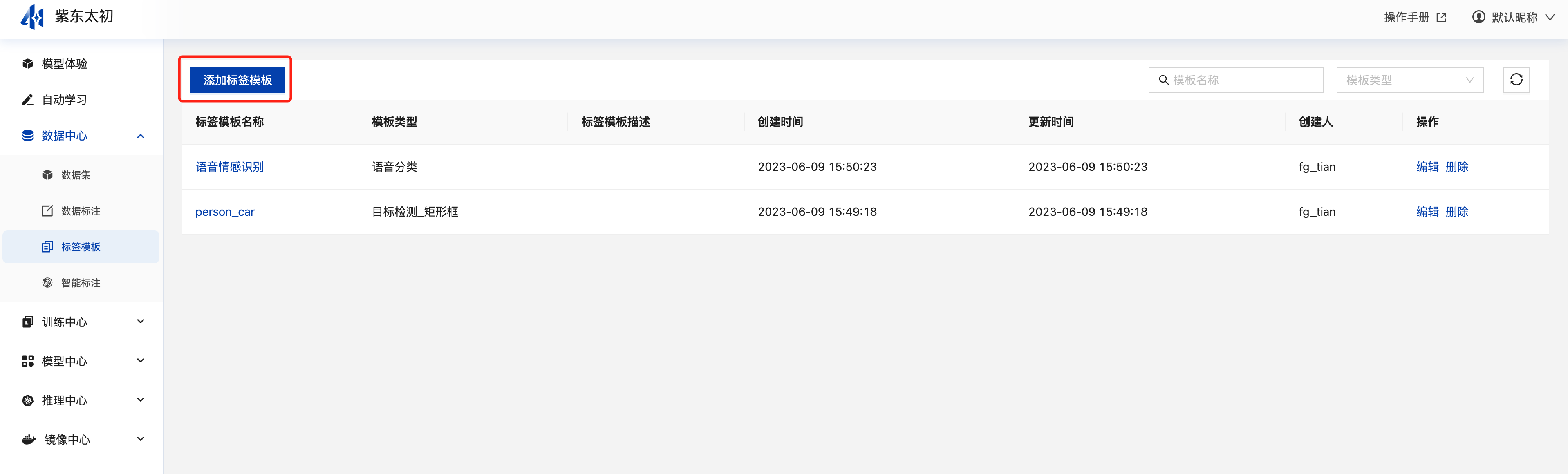
标签模板
标签模板主要是解决在标签比较多的情况下,要针对多个数据集创建标注任务时快速应用的场景。
创建标签模板
导航栏中选择数据中心-标签模板进入标签模板列表页,点击“添加标签模板”,即可开始创建标签模板。
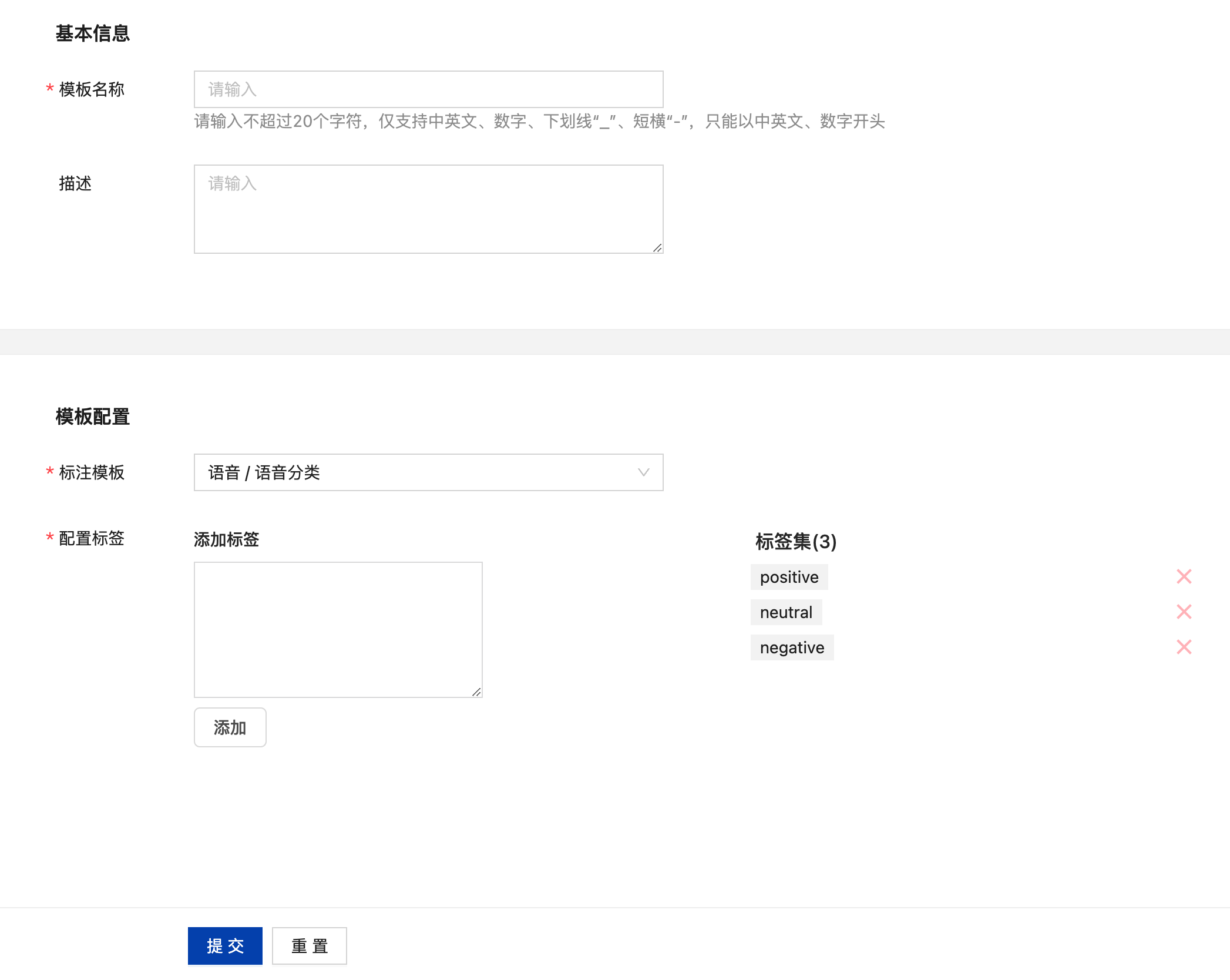
标签模板创建页中输入标签模板名称、描述(非必填)、标注模板、标签信息等内容后即可点击“提交”完成标签模板的创建,若有关系亦可同步创建其关系。
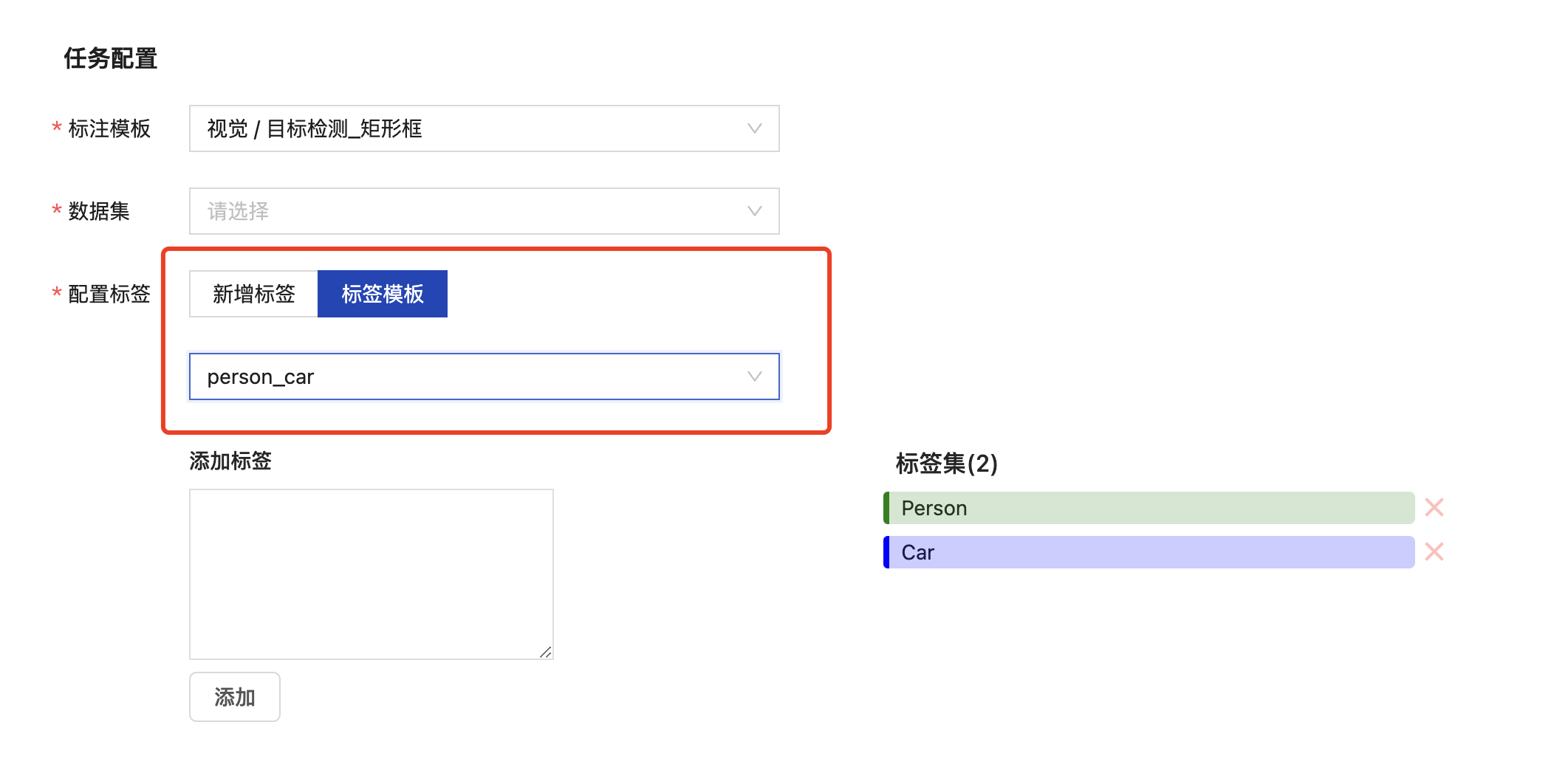
应用标签模板
在创建标注任务时,任务配置中选择标注模板、数据集之后可应用标签模板创建标注任务。
智能标注
除人工在线标注外,平台还提供了智能标注的功能,快速完成数据标注,为您节省数据标注的时间。智能标注是指当前标注阶段的标签、数据或已有的模型进行的智能标注,快速完成剩余数据标注的操作。
创建智能标注任务
在创建数据标注任务后,其右上角有“智能标注”操作入口,点击“智能标注”后在弹框中可选择预置模型服务中的模型进行智能标注。
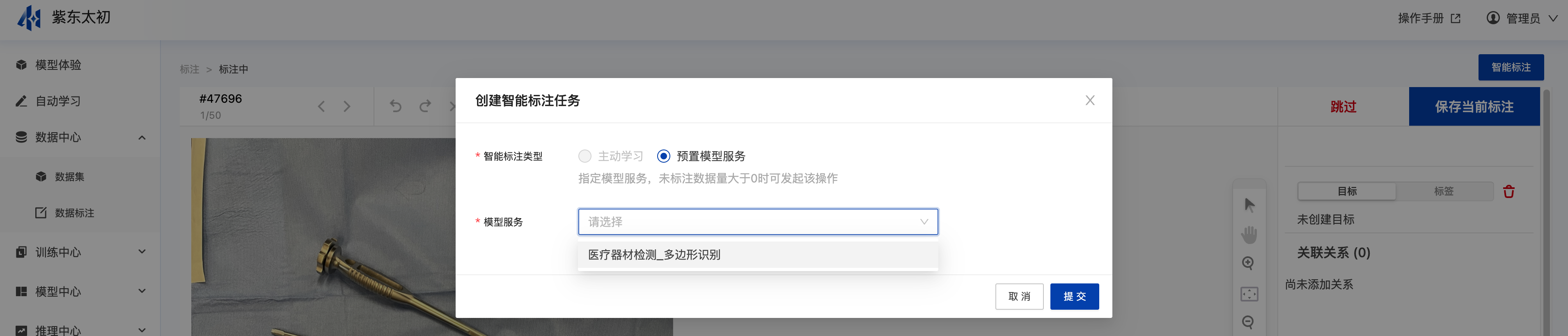
点击“提交”创建智能标注任务后会针对当前任务创建智能标注任务,自动完成未标注数据的智能标注,智能标注任务完成后,在标注页加载智能标注结果。

接收智能标注结果
智能标注任务完成后,进入数据标注页面会加载智能标注的结果,所有智能标注的结果都会在待确认栏中,可对智能标注结果编辑、修改,确认无误后点击“保存当前标注”会保存当前结果,自动加载下一条数据。亦可点击“一键接受智能标注”一次性接受所有智能标注结果,完成当前标注任务。
训练中心
训练中心是AI开放平台中不可或缺的功能模块,用于创建训练作业、查看训练情况以及训练任务管理。模型训练是一个不断迭代和优化的过程。在训练模块的统一管理下,方便用户试验算法、数据和超参数的各种组合,同时便于用户追踪最佳模型的相关参数配置,而确定最佳训练作业。
线下上传的已标注数据或线上标注完成的数据均可用于创建模型训练任务,支持用户通过平台创建自动学习任务、自定义任务、可视化建模任务。
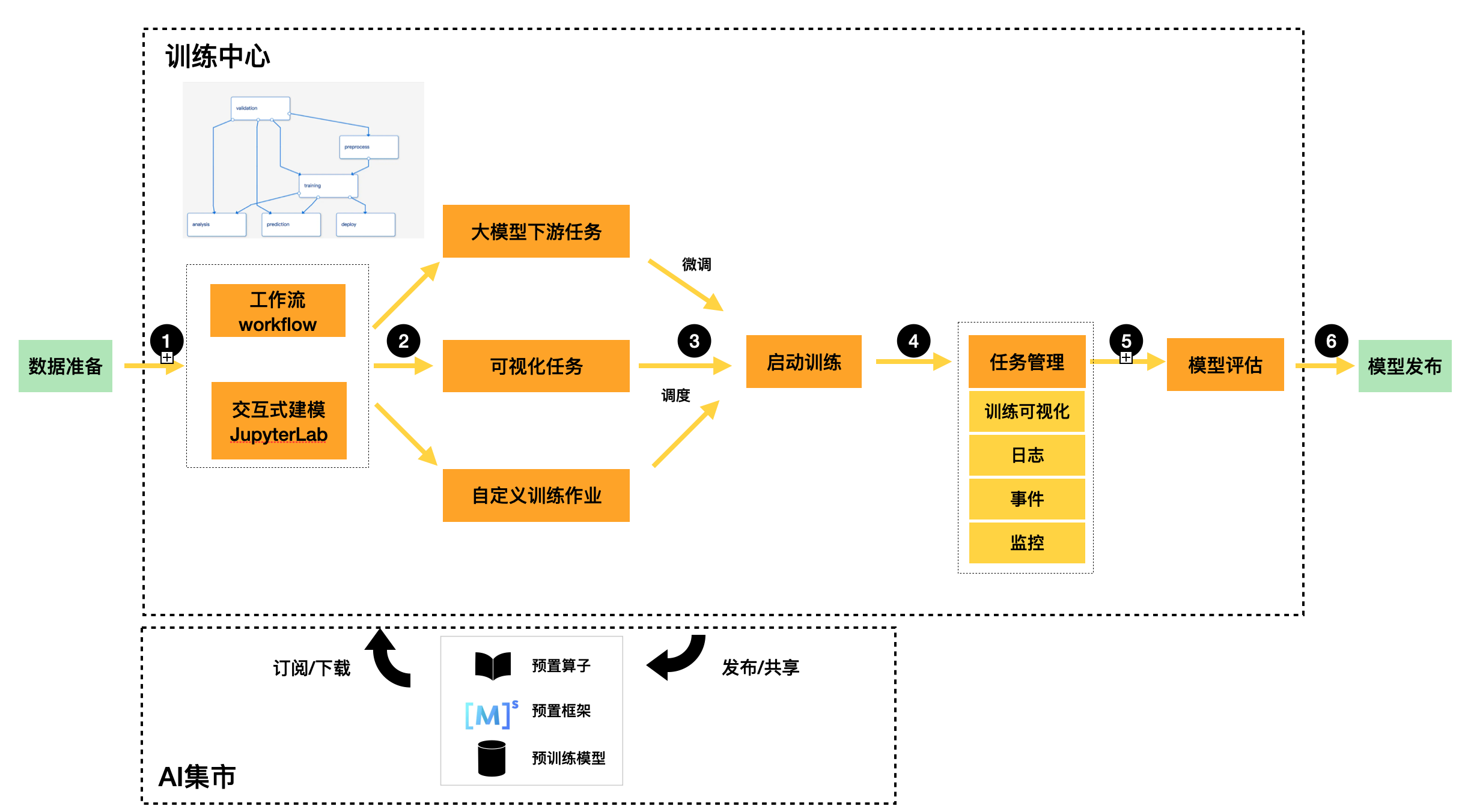
自定义任务
自定义训练任务提供高性能的计算环境,用于进行大模型微调、模型优化等场景。可以使用不同框架,编写自定义代码进行多轮训练和迭代,将模型作为结果输出,或者导入模型到模型中心,用户后续的部署推理服务。
自定义作业预置的训练环境支持机器学习和深度学习常用的基础镜像。可以将代码文件预先上传到代码管理中心,在创建自定义任务时选择代码中心的代码文件,同时选取数据中心的数据集,即可发起自定义任务的训练。
自定义任务管理
自定义任务区分于自动学习任务,支持用户自定义训练输入、输出、训练脚本、超参数、资源规格等内容,创建自定义任务之前需要提前准备相应的数据集添加到数据中心,训练代码包上传到代码管理中心。
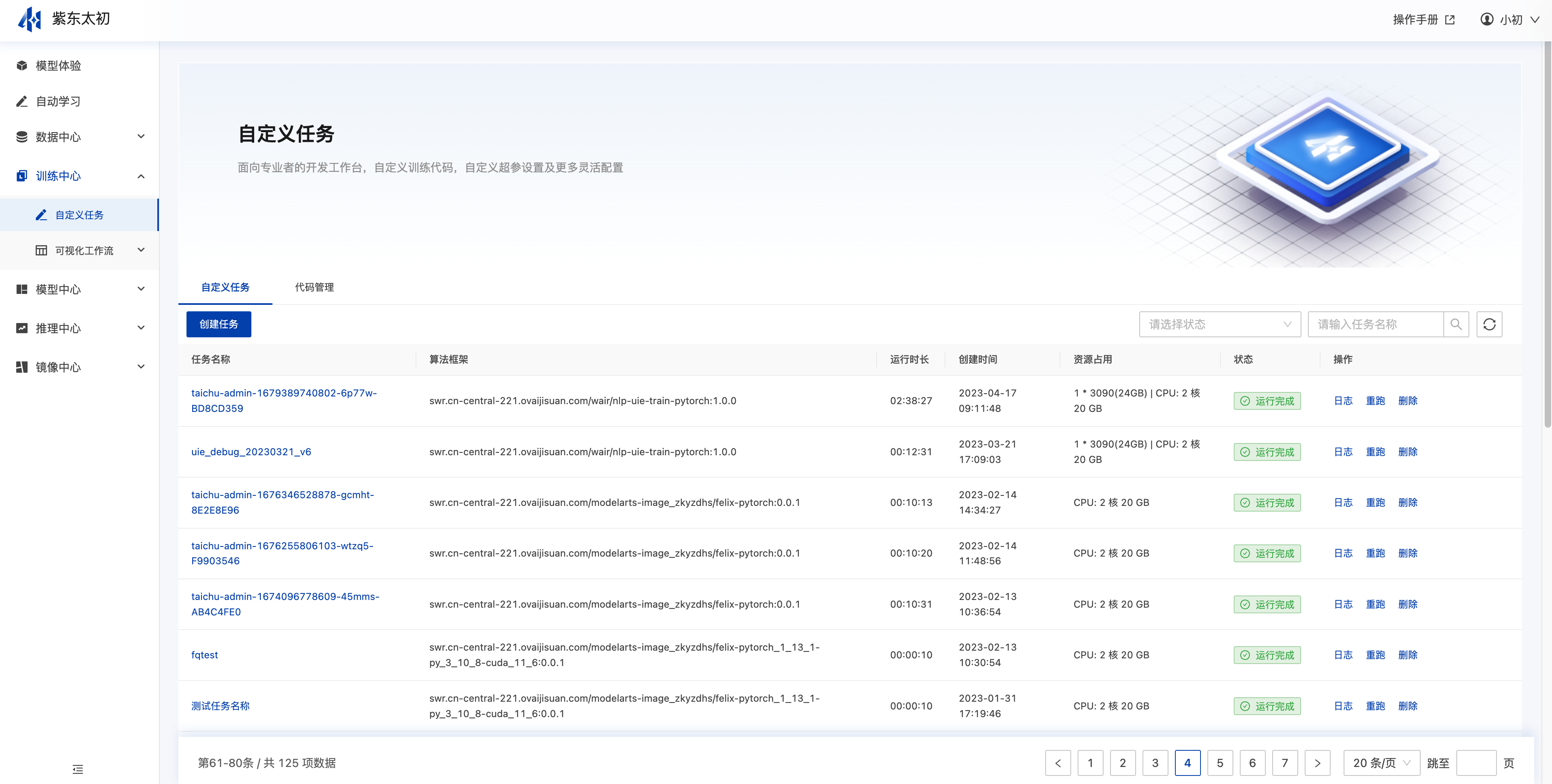
创建自定义任务
用户在自定义任务中点击表单右上角“创建任务”可创建自定义建模任务。在创建自定义任务页面需填写任务基本信息、算法配置、输入输出、算法配置等内容。
(1)基本信息
基础信息包含任务名称和描述(非必填)。
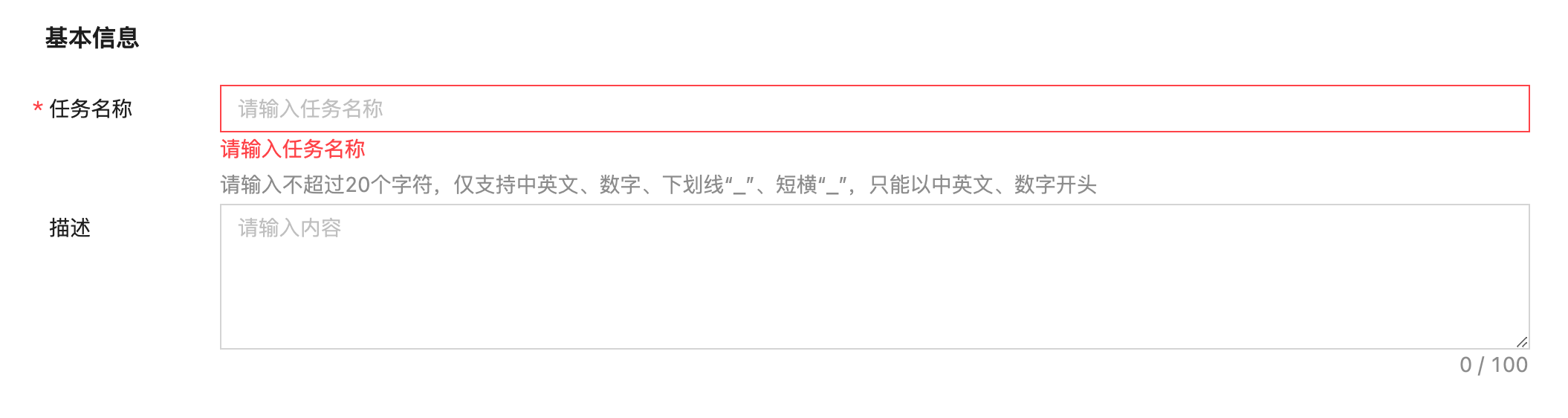
| 参数名 | 参数说明 |
|---|---|
| 任务名称 | 自定义任务名称:
|
| 描述 | 针对当前自定义训练任务的描述信息,非必填项。 |
(2)算法配置
算法配置包括创建方式、计算框架、代码、启动文件等内容,均为必填项。
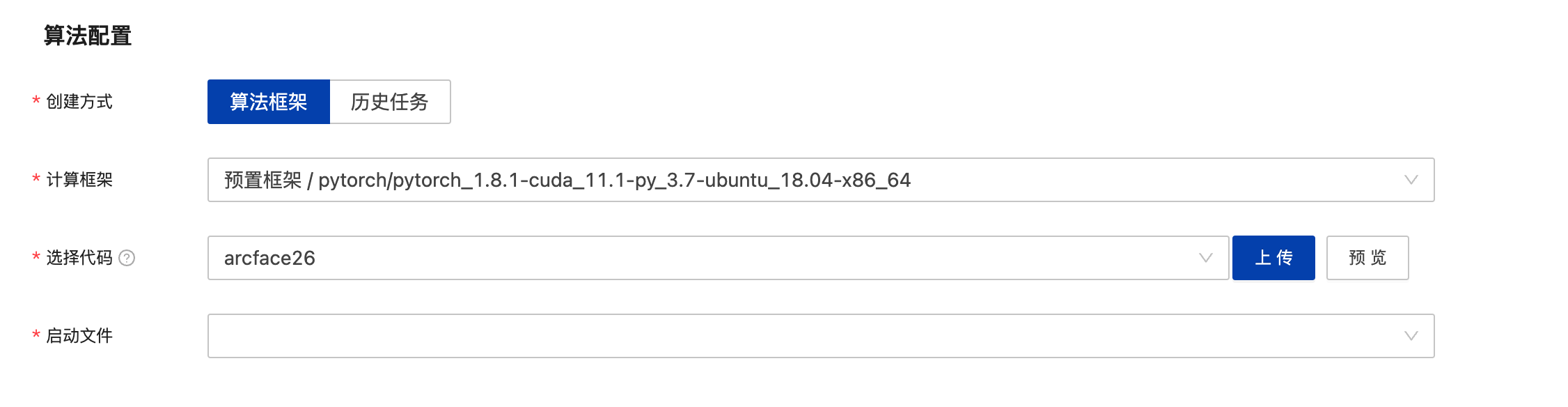
| 参数名 | 子参数 | 参数说明 |
|---|---|---|
| 创建方式-算法框架 | 计算框架-预置框架 | “创建方式”选择“预置框架”时,需要选择预置框架,并配置指定“代码目录”和“启动文件”。
|
| 计算框架-自定义镜像 | “创建方式”选择“自定义镜像”时,需要提前在镜像中心添加自定义的镜像文件,选定后需指定“代码目录”和“启动文件”。
| |
| 创建方式-历史任务 | 历史任务 | 创建方式选择历史任务之后可选择历史任务作为创建自定义任务的模板,带入历史任务填写的相关数据,支持用户修改后二次创建任务。 |
(3)输入输出
输入输出中可填写训练输入、训练输出、超参数、环境变量,用户可根据具体参数名配置其相关路径信息,输入输出相关信息均为非必填项。
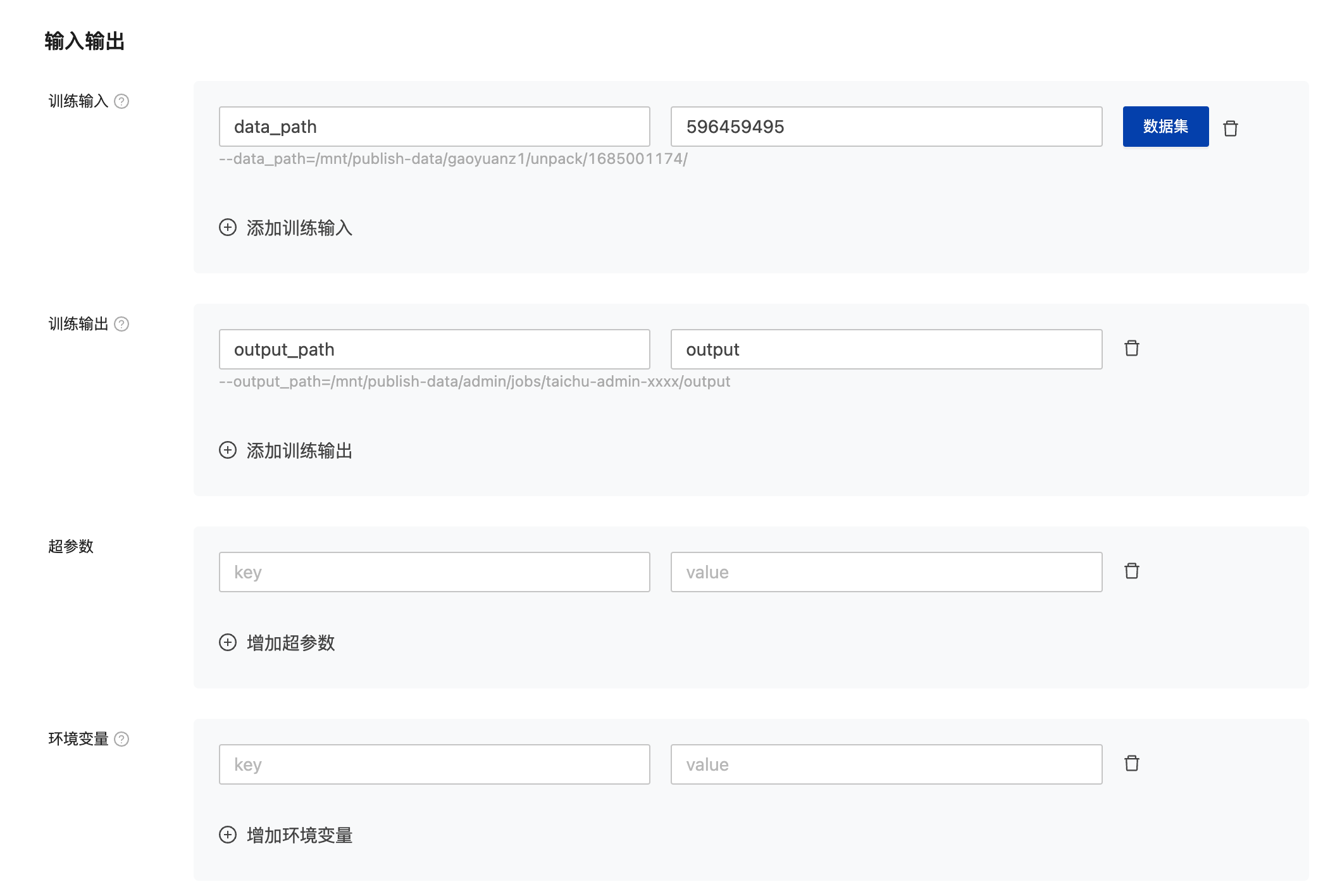
| 参数名 | 子参数 | 参数说明 |
|---|---|---|
| 训练输入 | 参数名称 | 可以设置为“data_path”,训练输入与所选择算法的“输入数据配置”需要匹配,训练启动时,会下载输入data_path所对应路径中的数据至训练容器中。 |
| 数据集 | 从平台数据中心中选择可用的数据集。单击“数据集”,在弹框中选择对应的数据。 | |
| 训练输出 | 参数名称 |
|
| 超参 | - | 超参数与算法相关,算法选择不同,超参数则不同。超参可修改、删除,取决于在创建算法时的超参约束设置,一般超参数可以设置epoch、step、batch等参数。 |
| 环境变量 | - | 根据具体需要添加环境变量 |
(4)资源配置
资源配置中选择资源池、资源类型、资源规格,填写节点数、训练最长时长等信息。
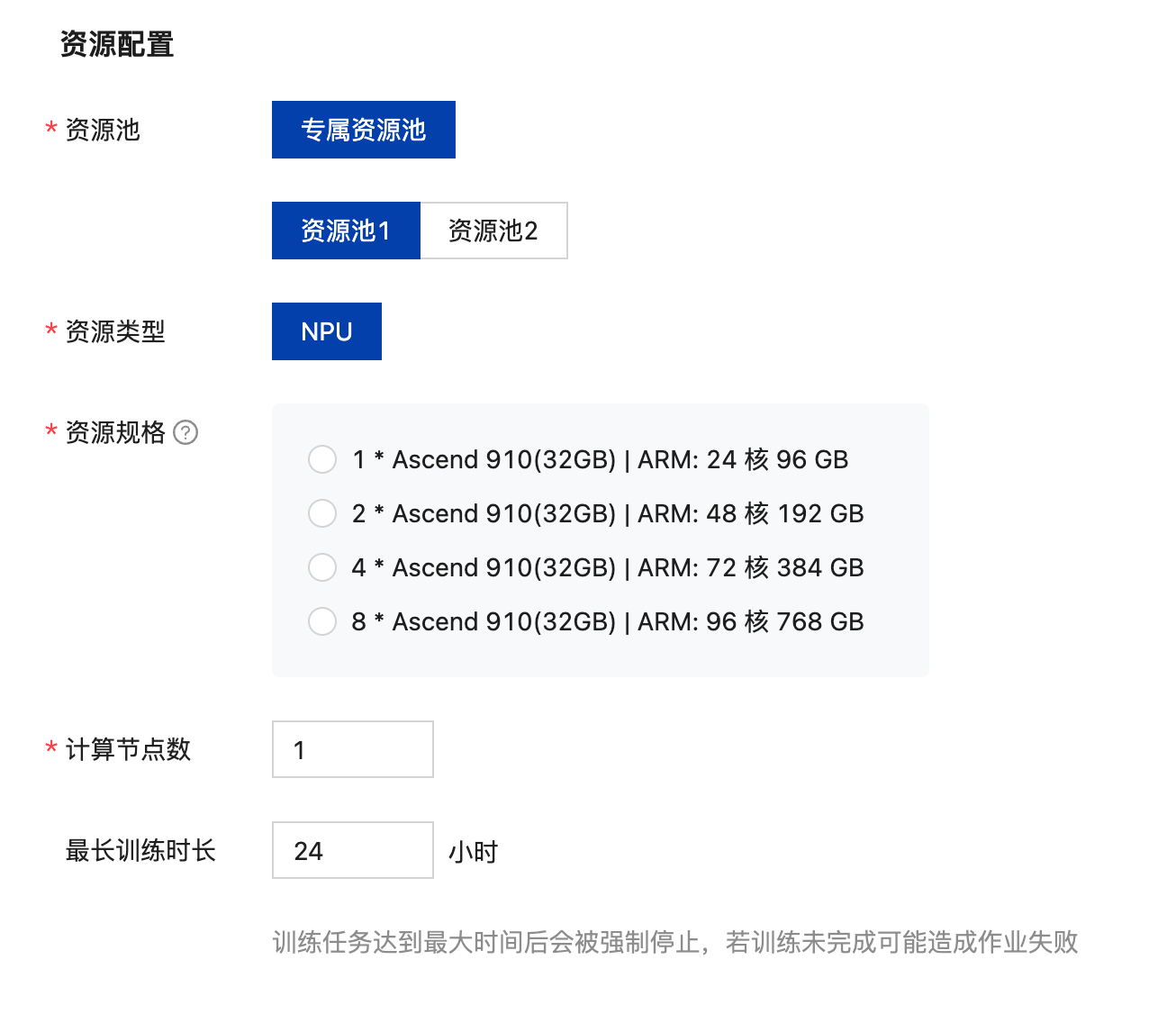
| 参数 | 参数说明 |
|---|---|
| 资源池 | 选择训练任务需要的资源池,可选择“公共资源池”或“专属资源池”。
|
| 资源类型 | 资源类型支持CPU、NPU、GPU,根据实际硬件资源类型。 |
| 资源规格 | 对应资源类型下的实际资源规格,创建自定义任务时,可以在有效规格内选择合适的资源,无效选项置灰不可选。例如:资源类型选择为NPU,资源规格为1 * Ascend 910(32GB) | ARM: 24 核 96 GB。 |
| 计算节点 | 填写计算节点的个数,默认节点数为1 |
| 最长训练时长 | 当前训练任务的最长训练时常。
|
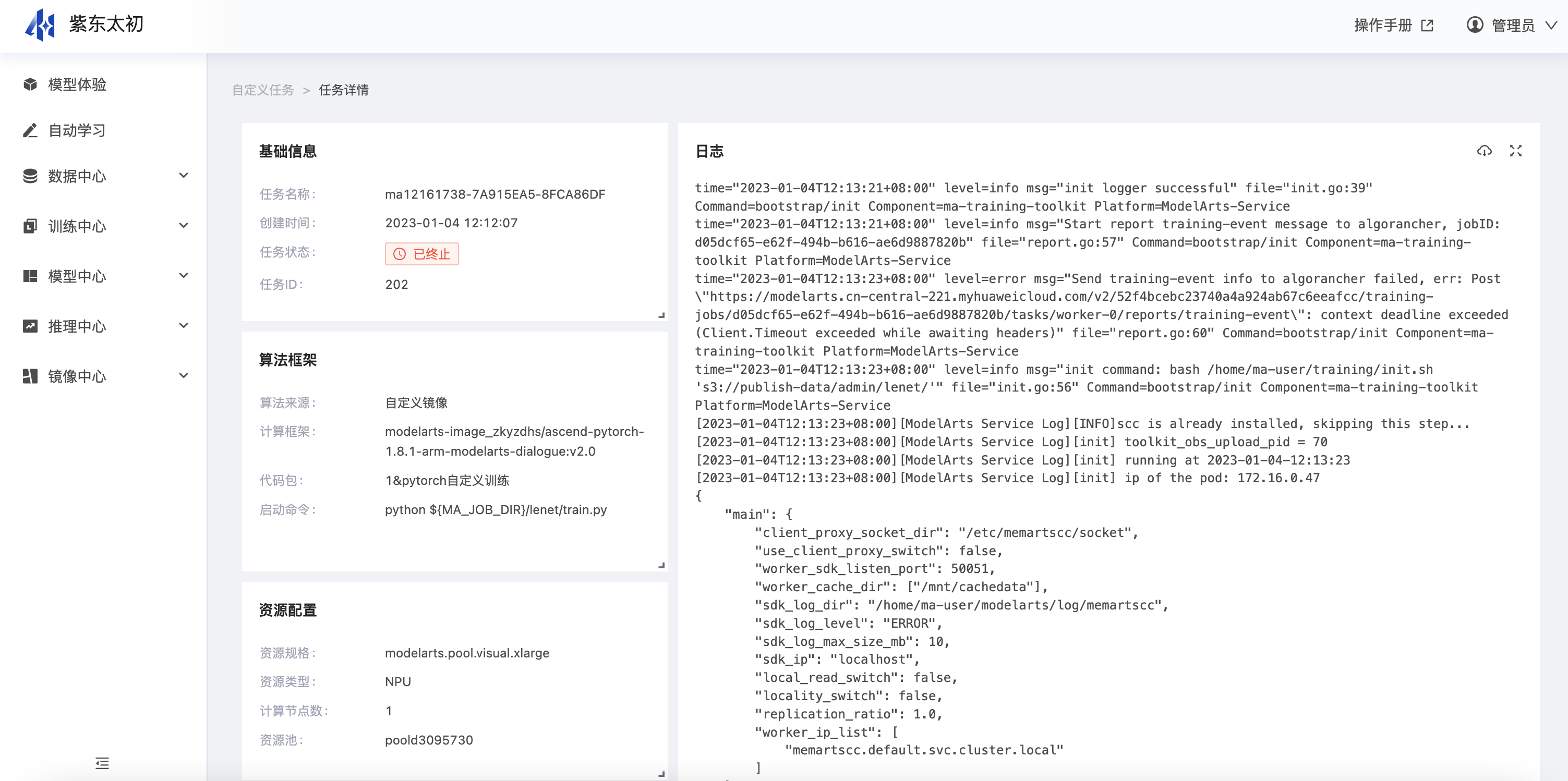
(5)自定义任务详情
在“自定义任务”列表中单击任务名称,可进入当前训练任务详情页,在训练任务详情页中可查看到当前训练任务关联的信息。自定义任务详情中除了展示创建自定义任务时填写的基础信息、算法框架、资源配置、输入输出等内容,还展示训练过程中的日志和训练资源实时占用情况。
代码管理
自定义任务区别于自动学习任务,用户具有较高自定义的操作权限,需准备自定义训练代码。通常情况下,训练代码可以复用,故而在平台自定义任务中对用户上传的代码进行统一管理,存放在代码管理中,用户在创建自定义任务时可直接选择代码管理中的代码包作为训练代码。
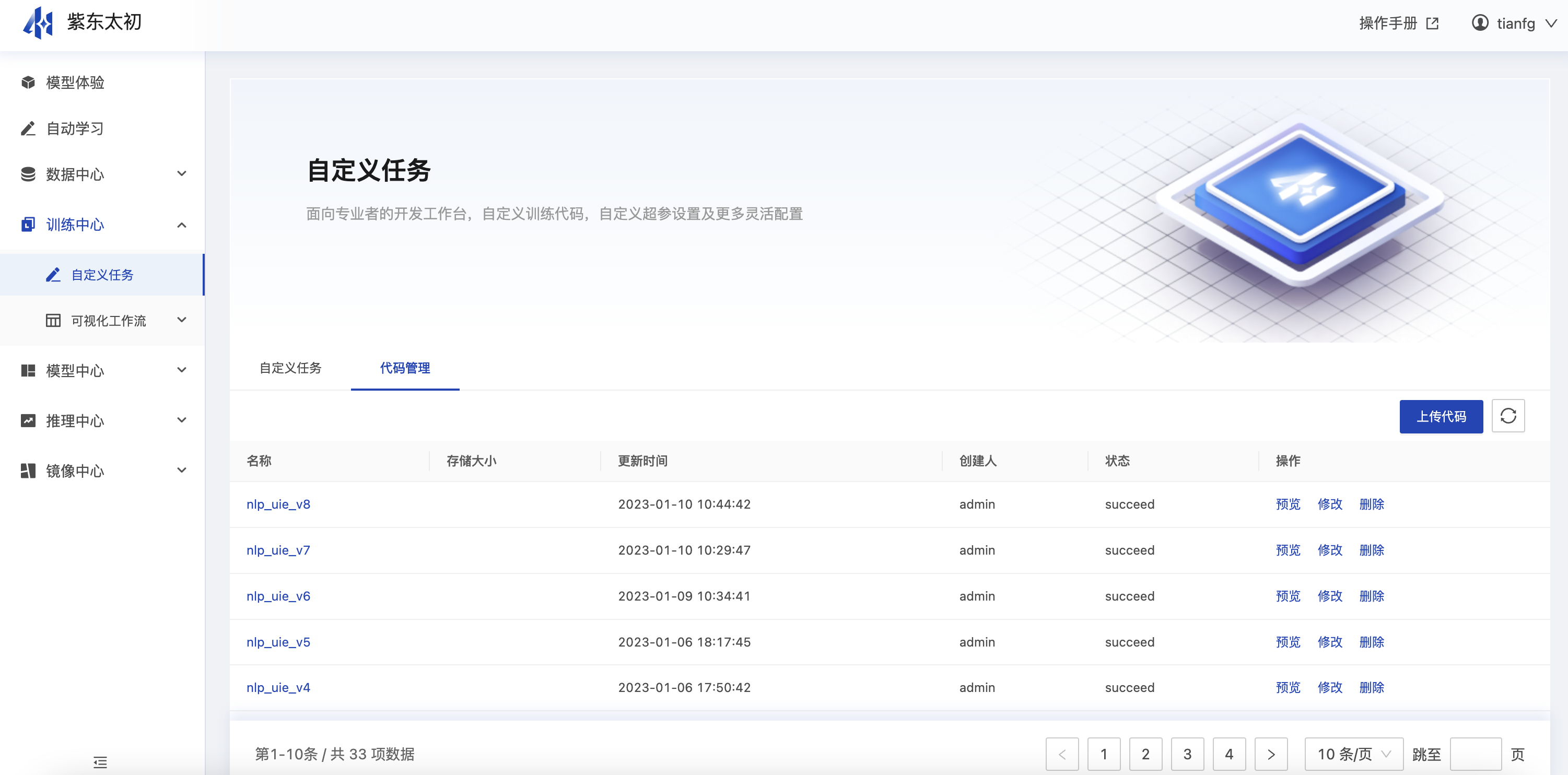
(1)上传代码
点击代码管理页面中“上传代码”跳转至上传代码的页面可进行上传代码的操作,需填写代码包名称,并上传本地zip格式代码包文件。
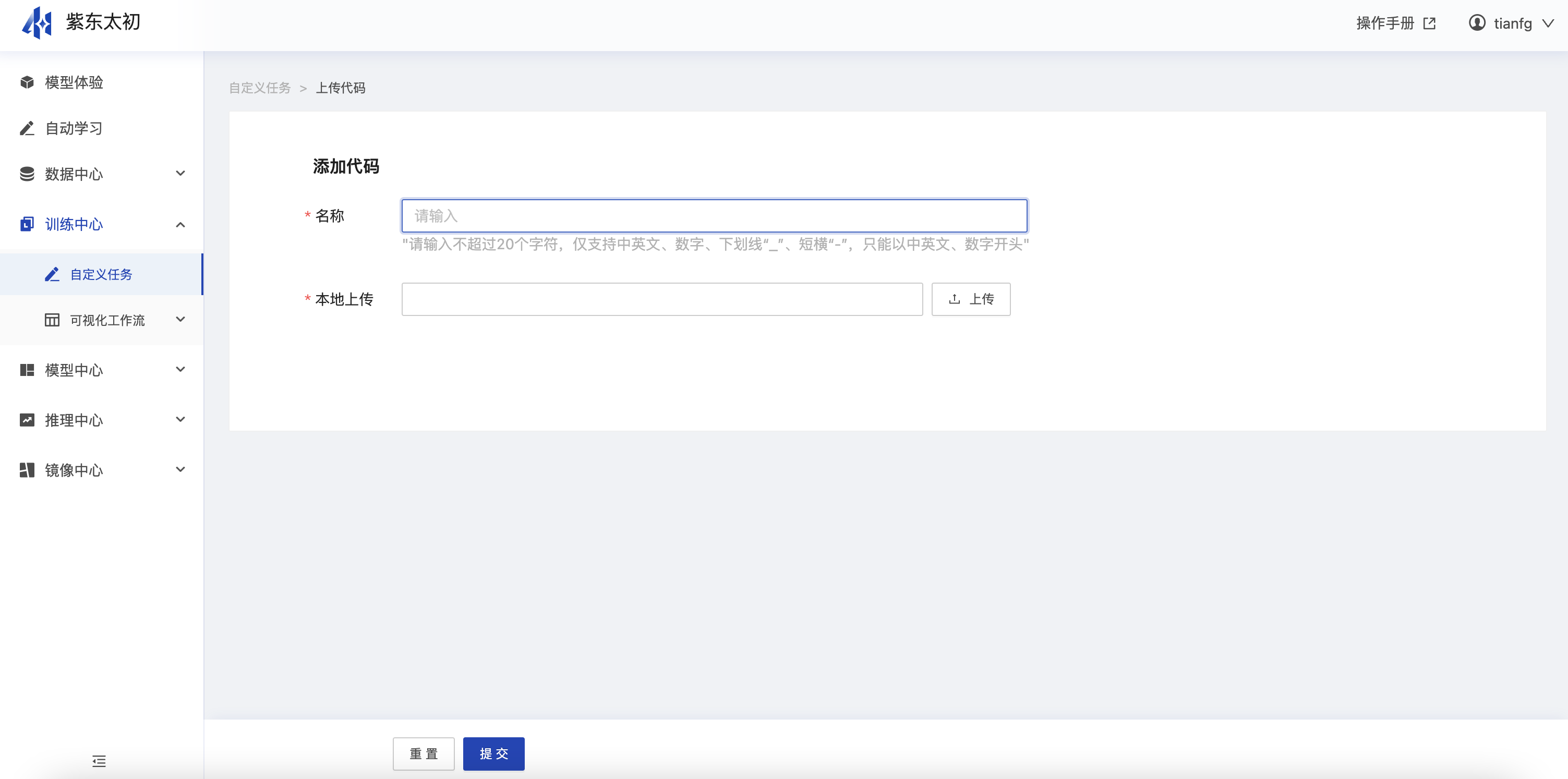
(2)代码预览
点击“提交”后会将代码包上传至平台,平台会自动进行解压的操作,解压后代码包支持预览,可查看其目录结构,内部代码文件等信息。

可视化建模任务
可视化建模任务分为工作流和运行实例,工作流是当前用户创建的可视化任务,预置模板是由系统预置的可视化模板任务。
可视化建模任务管理
用户可基于模板快速创建对应的可视化任务,可视化建模可组合各种数据源、算法、部署、评估等组件,通过拖拽的方式完成建模任务的搭建,为AI工程师打造AI建模过程的全流程开发支持。
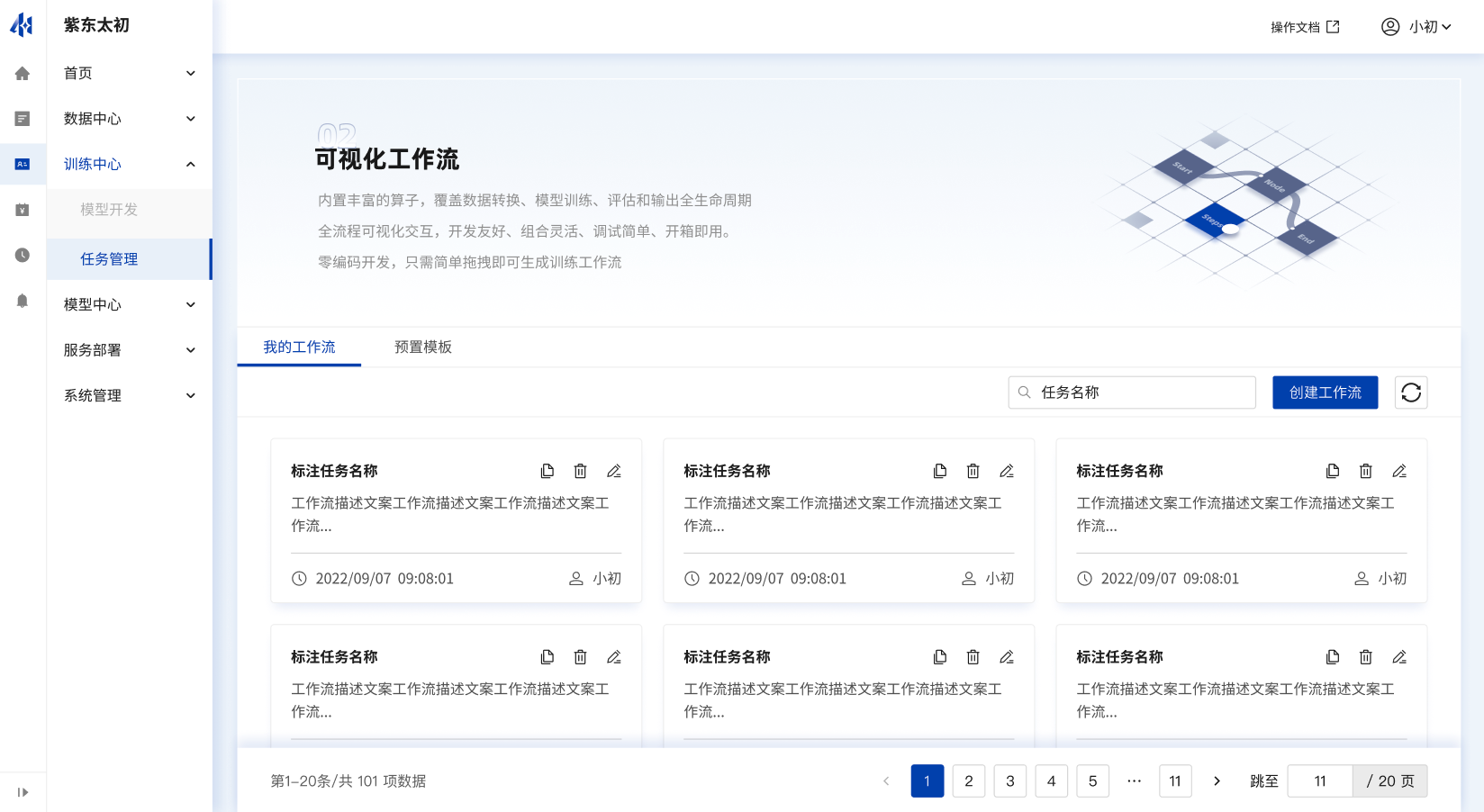
创建可视化任务
用户在可视化任务中点击“创建工作流”可创建自定义建模任务。在创建任务页面需填写工作流名称、描述后提交完成创建。

| 参数名 | 参数说明 |
|---|---|
| 任务名称 | 工作流名称:
|
| 描述 | 针对当前自定义训练任务的描述信息。 |
大模型服务平台为您准备了工作流模板,勾选“从模板创建”,可选择内置的模板新建工作流任务。创建完成后,您还可以对工作流进行编辑/复制/删除等操作。点击工作流卡片即可进入到画布编辑页面,在画布编辑页面可将左侧算子拖拽至画布中,配置算子参数、输入输出,即可组建成pipeline。
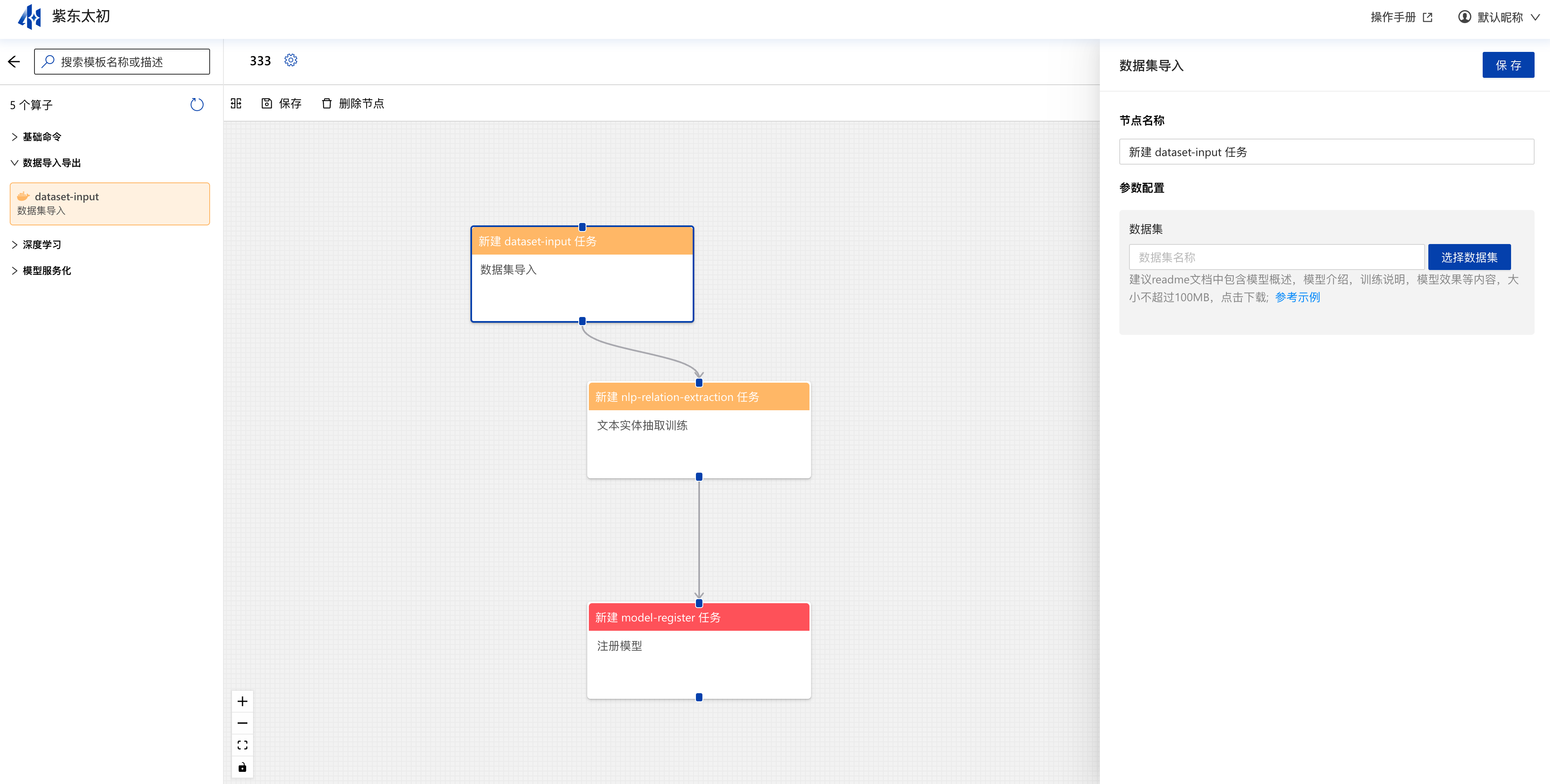
运行实例
点击画布右上角“运行”按钮,可运行当前工作流实例。实例每运行一次会在运行实例的表单中生成一条运行记录。

点击名称即可进入查看运行详情,每个组件均会展示起运行状态,并支持查看其单节点的运行日志。
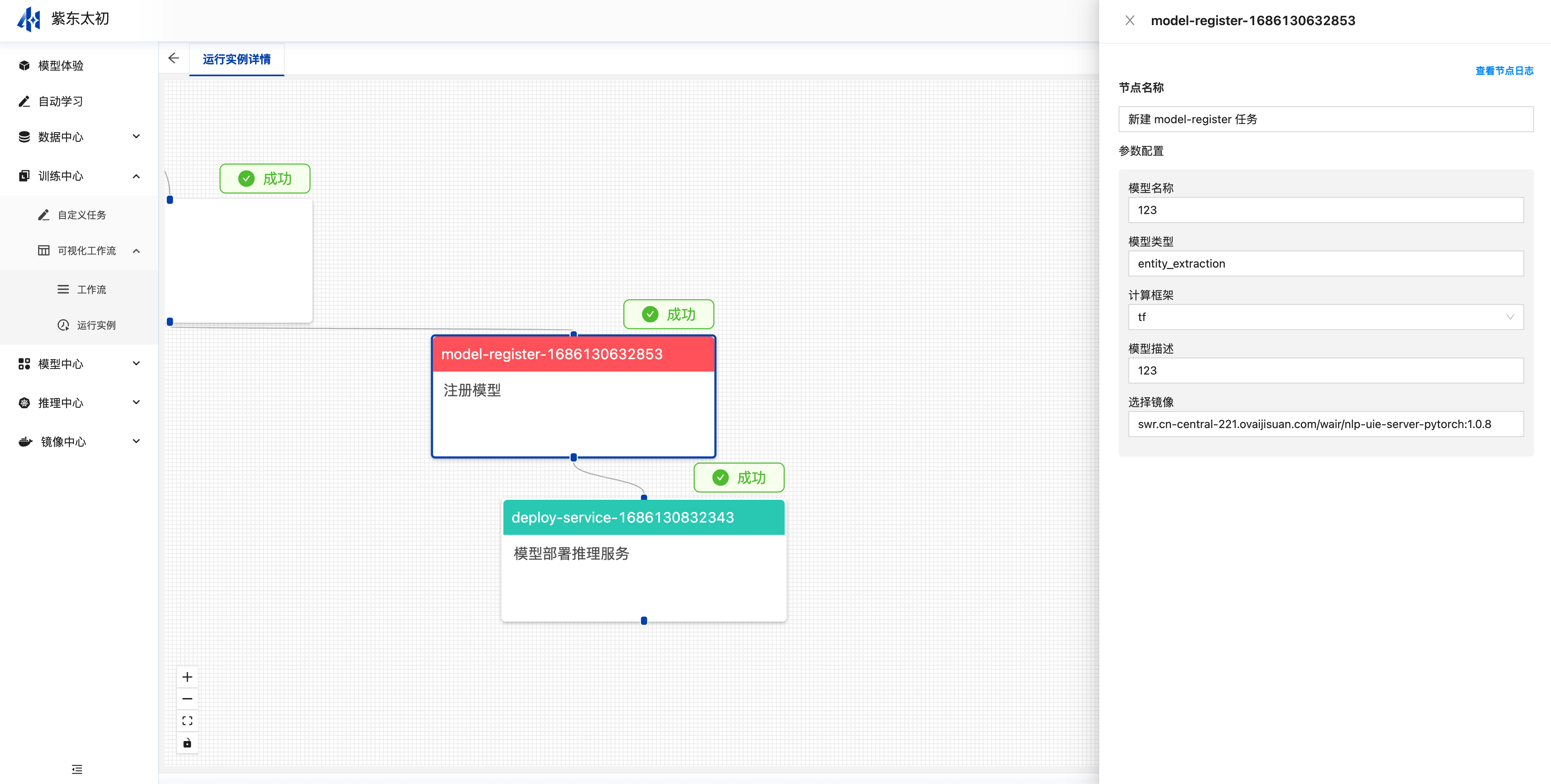
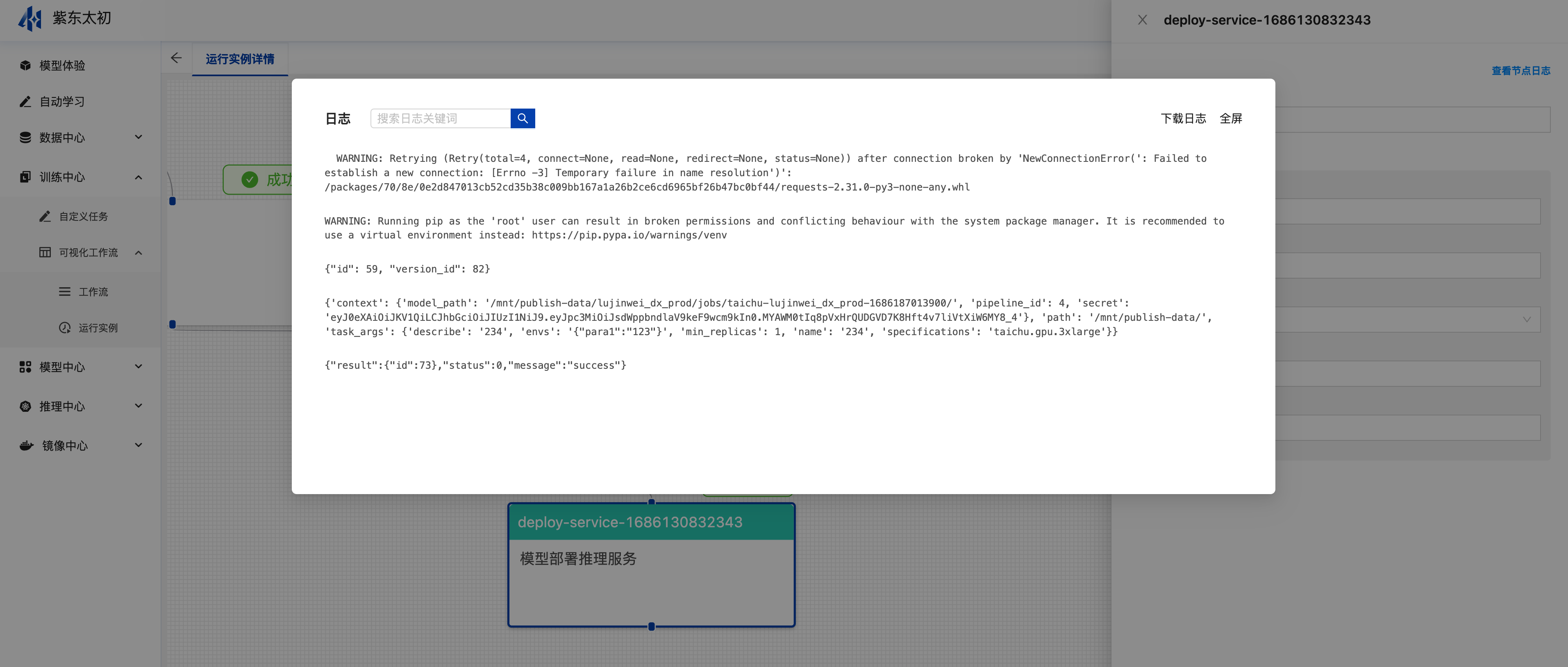
点击节点后,在其弹出抽屉中点击“查看节点日志”即会弹框展示当前节点运行的日志信息。
模型中心
模型中心包含了对训练中心训练任务生成的模型和第三方模型的统一管理。用户通过指定任务名称导入来自[自动学习]、[自定义任务]、[可视化建模]等模块产生的模型文件,也可以本地上传符合平台规范的其他来源的第三方模型。模型可以是主流框架支持的业内通用导出格式,如mindir、onnx、savedmodel等,也支持直接导入一个已在镜像中心注册的镜像。用户可以在模型中心对模型进行增删、版本管理、部署在线服务等操作。
模型管理
模型管理列表列出了用户的所有模型资源,每个模型可以创建多个版本。当首次创建模型时,会自动创建一个模型版本;当删除最后一个模型版本时,模型也会随之删除。模型的每个版本均可以从训练任务中导入或者从本地上传。模型的每个版本都可以独立部署成一个在线服务,实现灰度发布和A/B测试等服务能力。
模型列表以折叠表的形式展示模型数据,展开可展示各版本模型信息。点击模型名称可查看当前模型的详细信息,点击操作栏中“导入新版本”可将训练任务得到的模型作为新增版本添加至当前模型中。点击操作栏中“删除”确认操作后会删除当前模型的所有版本数据。点击模型版本操作栏中“部署”可跳转至创建在线服务的操作。
导入模型
平台支持三种导入模型的方式:
- 从训练任务中导入
- 从本地导入一个自定义镜像
- 本地上传
从训练任务导入
模型中心作为连接训练和推理的桥梁,对训练产生的模型进行统一的管理,包括版本管理、模型优化、格式转换等。版本管理方便对不同的训练实验产生的模型进行评估。训练产生的模型只有导入到模型中心后,才可以部署到推理服务。模型版本管理通过模型评估指标等手段可以对同一个训练场景的多次训练实验进行评价;模型格式转换和优化、压缩等工具可以打通训练和推理环境的差异,可以适配更多的推理框架、异构的推理硬件资源、适配云边等多种部署环境。
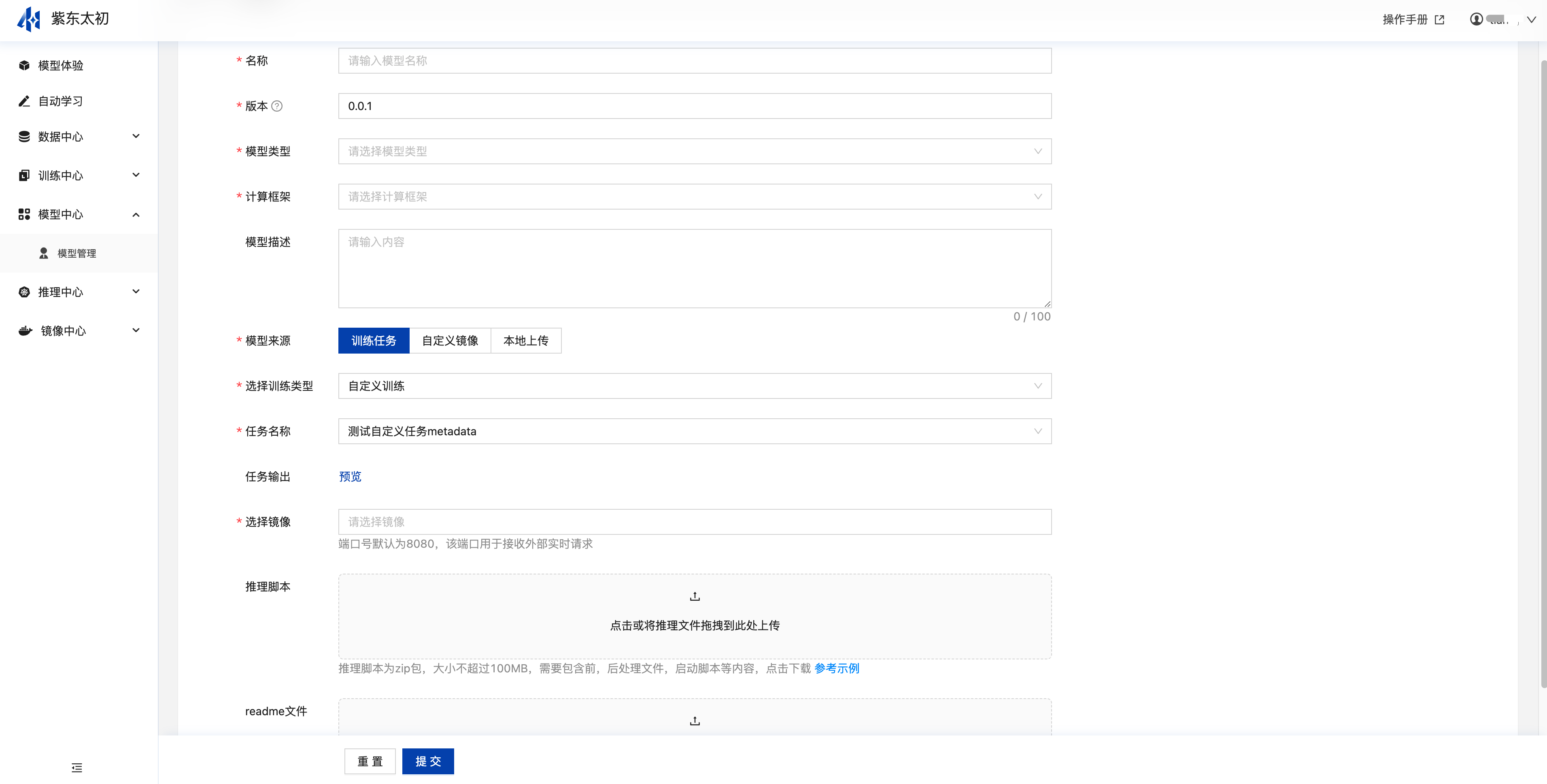
从训练中心导入支持来自于自定义任务产生的模型文件,自动学习任务输出的模型可自动添加至模型表单,可视化任务输出模型,支持通过算子组件写入到模型表中。基于自定义任务导入模型,选择训练任务类型和名称后,可以预览训练任务输出目录下的文件,选择镜像、上传推理脚本、readme文件(非必填项)即可导入当前模型文件。平台支持pytorch、mindspore、tensorflow等多种主流框架的模型格式,同时支持onnx等开放模型格式。
从自定义镜像导入
模型来源选择“自定义镜像”即可基于镜像导入模型,实际应用中,往往需要对模型运行环境做定制,以及进行前置后置的处理、模型预测输入请求的标准化、自定义预测过程代码等等。用户可以在本地制作好模型运行的镜像,提前将模型文件和前置后置处理的代码准备好,按照平台提供的规范格式构建好镜像之后注册到平台镜像中心,在模型导入时选择自定义镜像即可。平台提供高度灵活、高度定制化的部署机制,将用户的自定义镜像部署成在线服务。导入时选定镜像文件后,上传readme文件(非必填项)点击“提交”既可完成模型的创建。
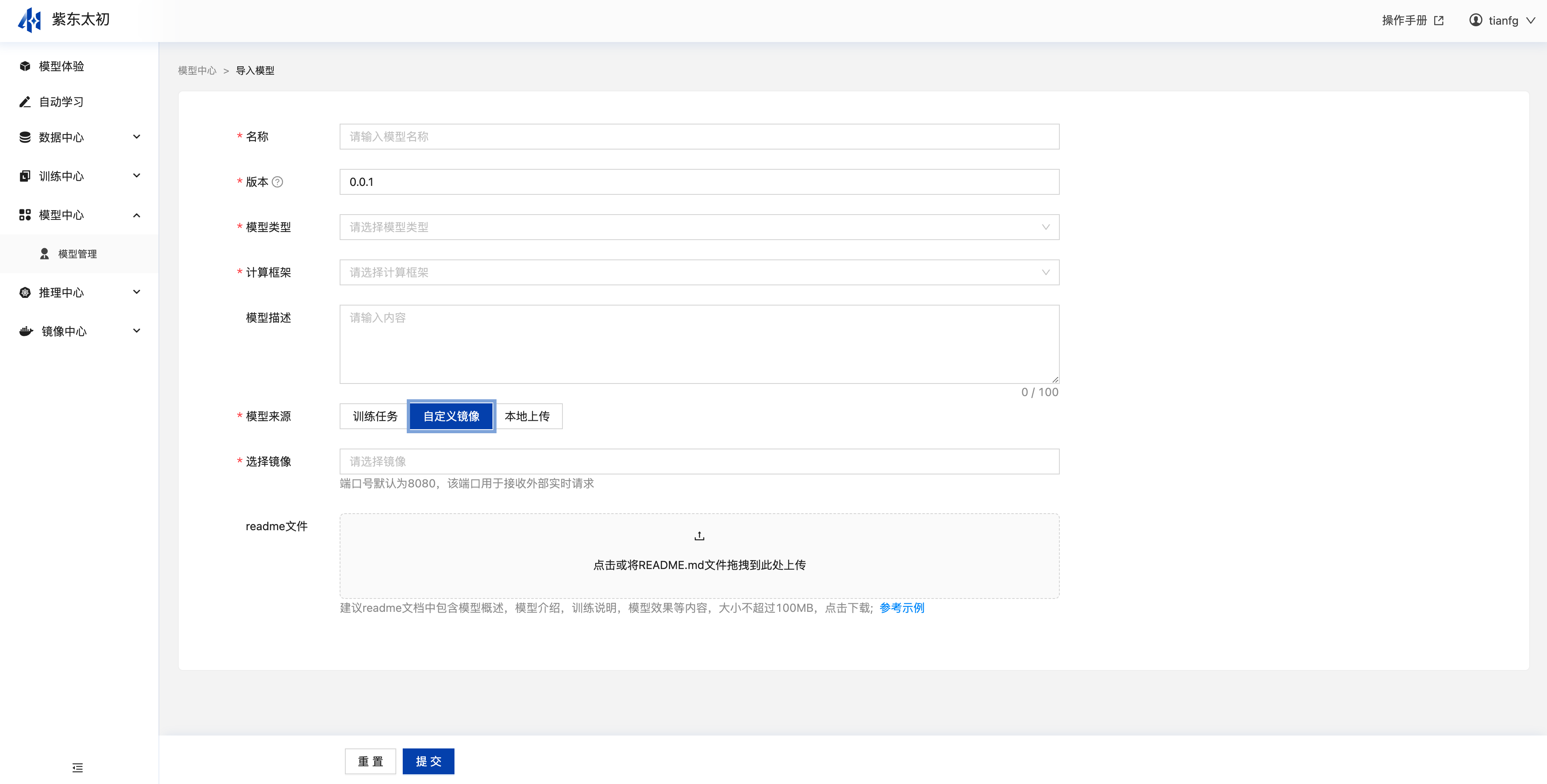
从本地上传模型
平台还预置了大量的基础镜像,用户可基于平台预置的基础镜像创建模型,选择“本地上传”后,选择基础镜像,并上传模型文件、模型readme文件(非必填项)点击“提交”即可导入本地模型。
推理中心
模型中心模型管理中的状态为成功的模型可用于部署,部署成功后,可提供模型在线预测服务,若模型有多个版本则支持模型的灰度发布。已部署模型可发起在线预测操作,用户添加待预测数据后,提交即可基于当前模型对输入数据预测输出;亦可通过调用API的方式把AI推理能力集成到其他业务系统中。
创建服务
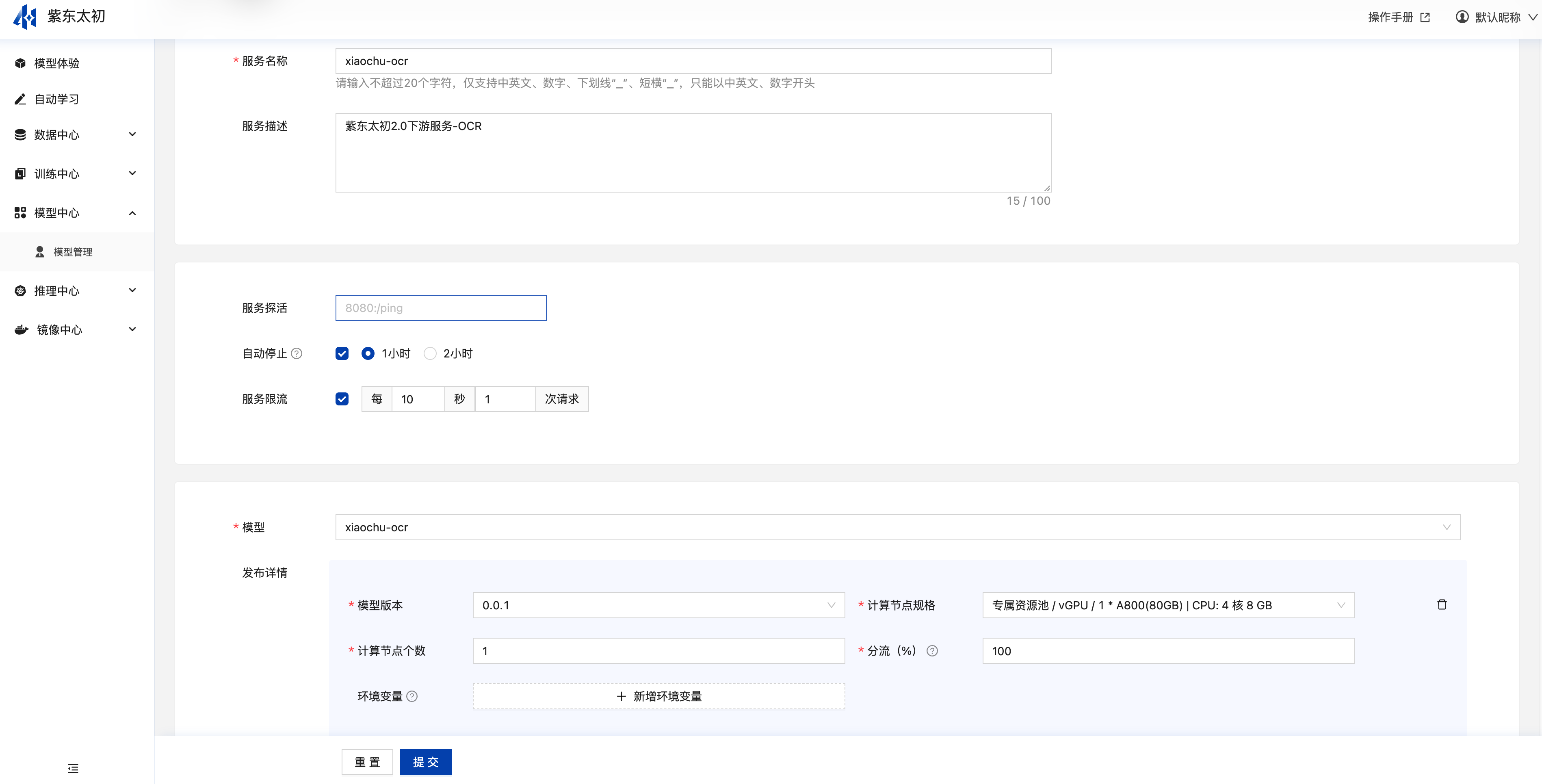
服务部署成功后可在平台内或作为独立API提供模型的在线预测服务。在服务部署在线服务列表右上角点击“创建服务”或在模型管理模型版本操作栏中点击“部署”均进入创建在线服务的页面,用户填写服务信息,选择模型,确认资源、计算节点等信息后即可点击“提交”创建模型的在线服务,若模型有多个版本,可添加模型版本,设置分流策略进行灰度发布。
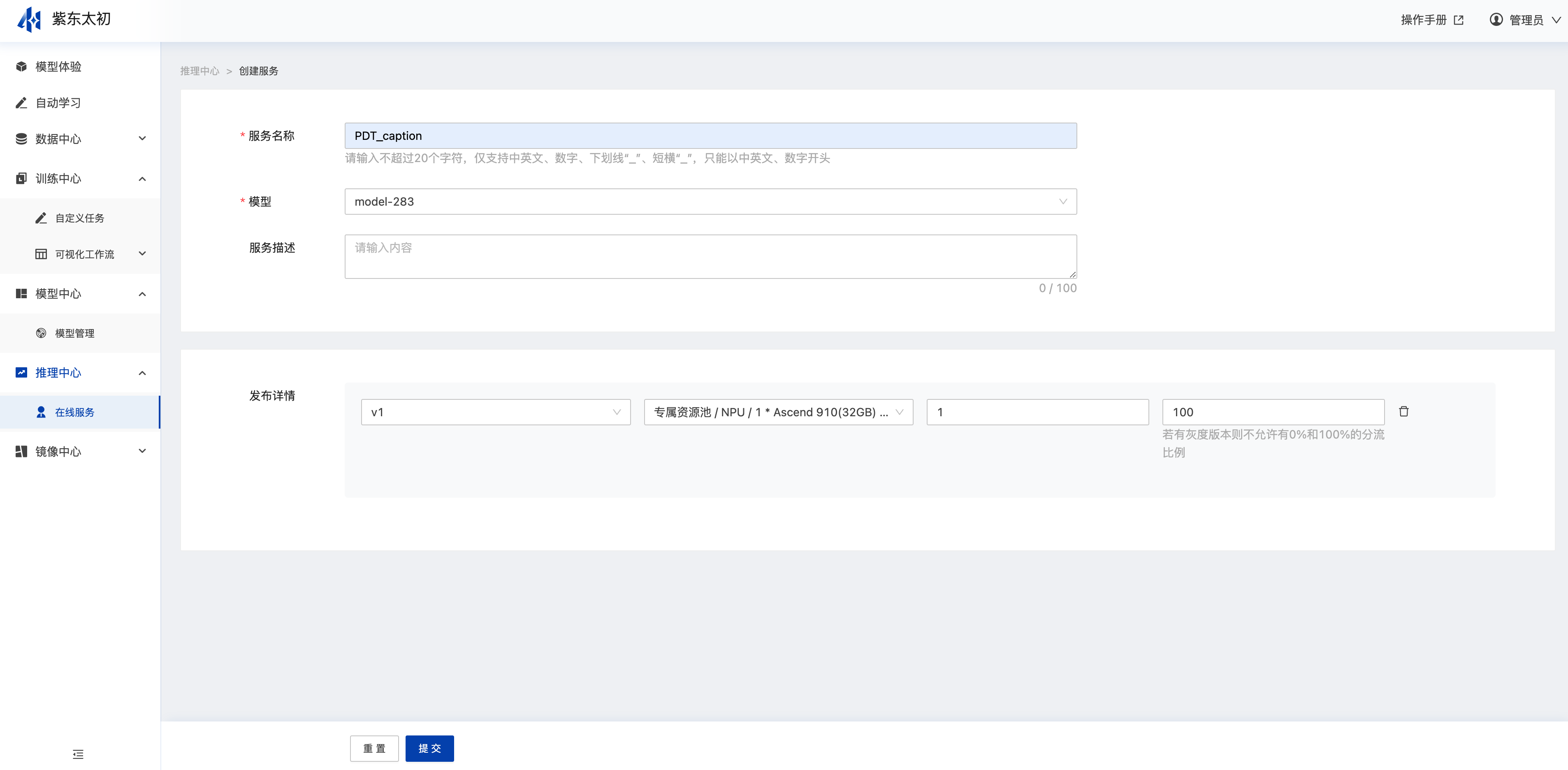
创建服务提交后在服务列表中会新增一条服务数据,运行状态为部署中,部署成功后运行状态会变更为运行中,可在操作栏发起更新服务、预测、启停用和删除等操作。
服务更新
已部署服务点击其操作栏“更新”可进入更新设置的页面,更新服务时可设置其服务探活、自动停止、限流策略,同时支持变更其模型版本、节点数以及其节点对应的资源。
服务回滚
已部署服务点击其操作栏“回滚”可进入回滚设置的页面,回滚时可设置具体需要回滚的服务版本,服务中会记录最近更新的5个最近版本,每个版本会记录其对于的模型、模型版本、分流、资源等信息。

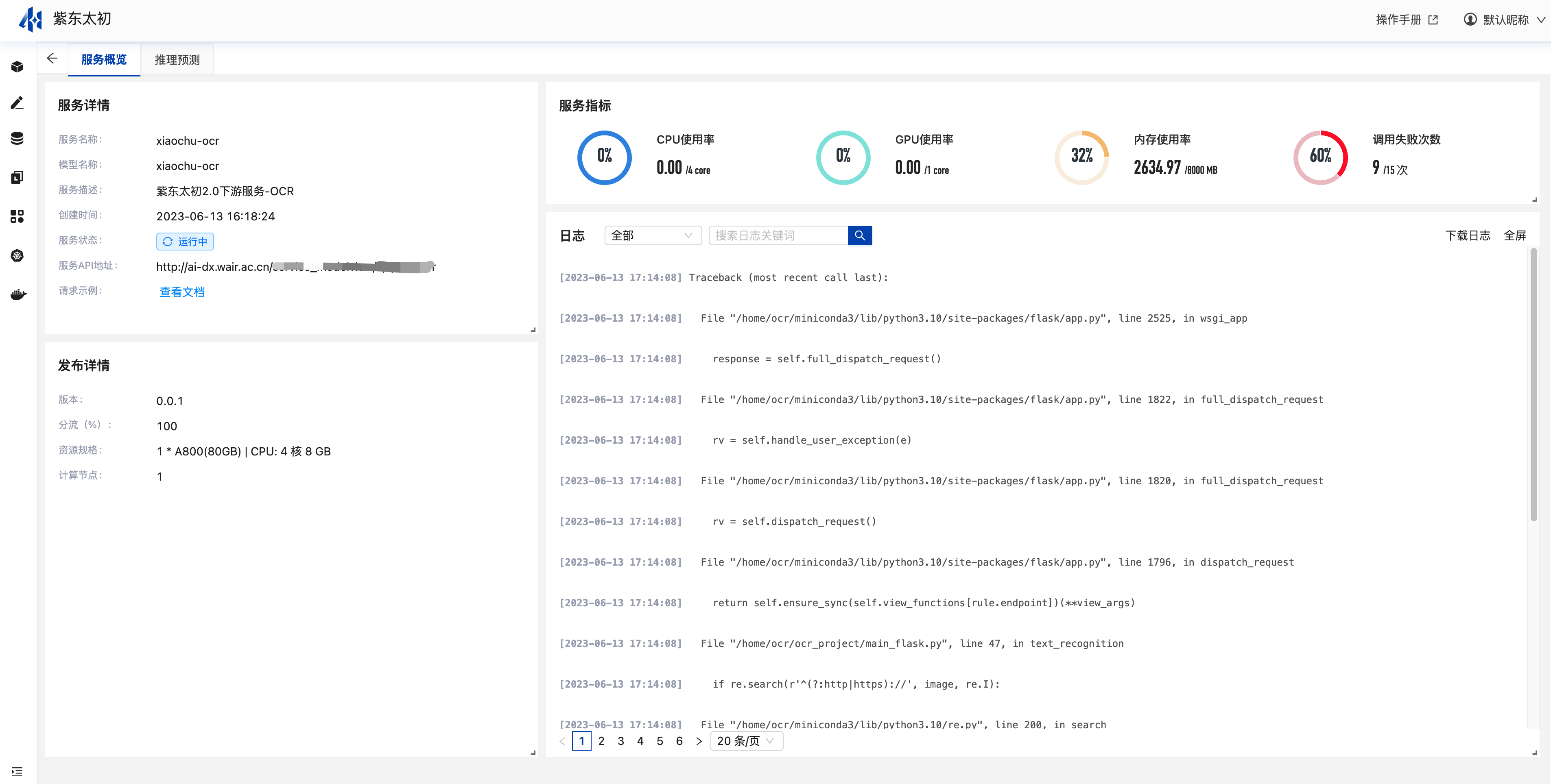
服务详情
服务表单中点击服务名称可查看服务详情,服务详情中记录当前服务名称、描述、创建时间、服务地址等相关信息。发布详情中会记录当前服务的版本、分流策略、资源节点等信息。服务指标中可查看当前服务CPU、GPU、内存、调用情况以及日志信息。
服务API调用说明
获取用户许可
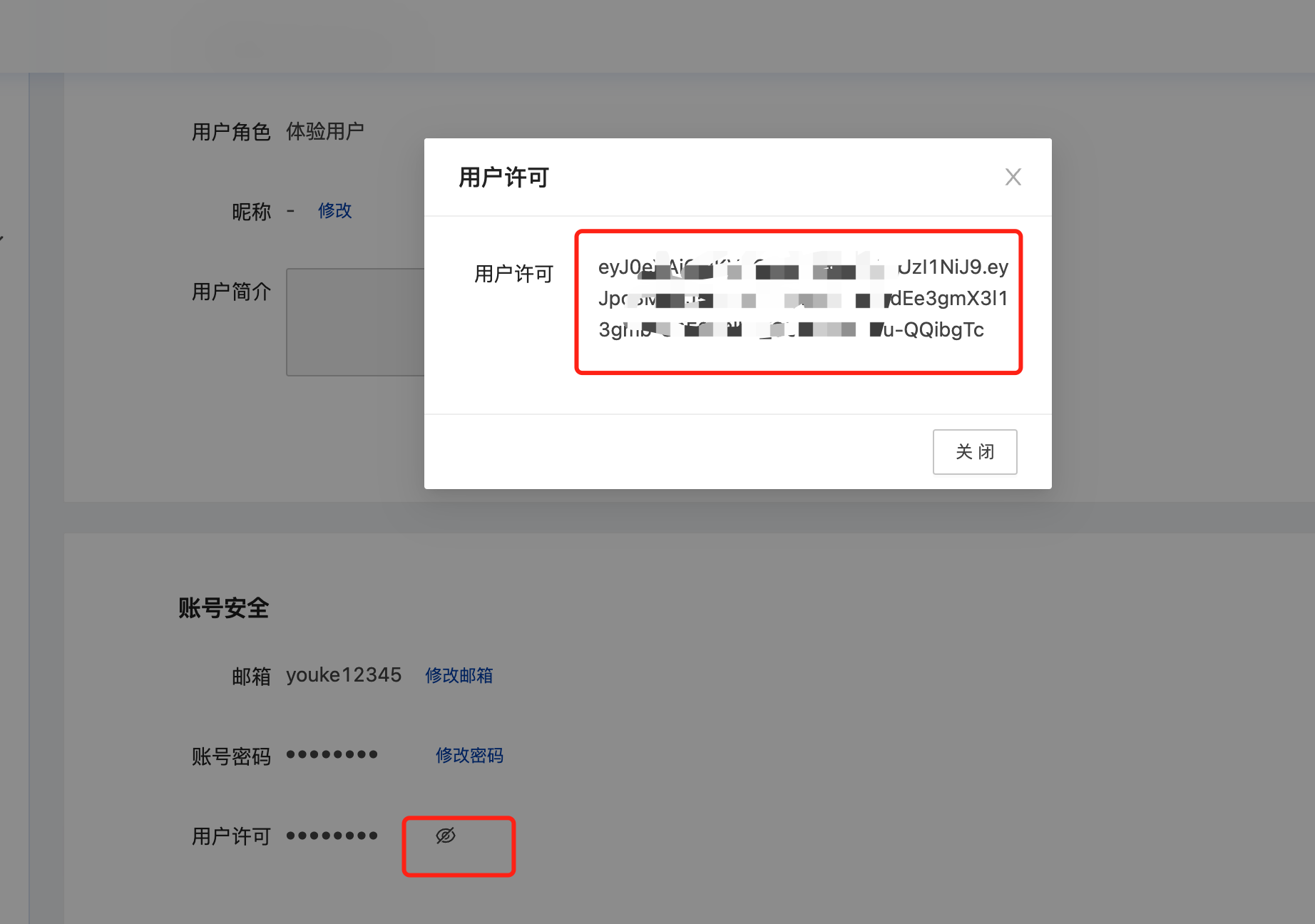
获取用户许可需要用户登录平台,进入用户中心,在用户中心账号安全中获取用户许可。

在用户中心点开用户许可,在弹框中输入密码校验后,用户许可信息中的长串字符串即为用户许可信息,可用于后续的API调用请求。
构造请求
请求URL:
服务详情页中展示服务相关信息,以及发布详情,服务API地址在服务详情中,可查看到对应请求地址。
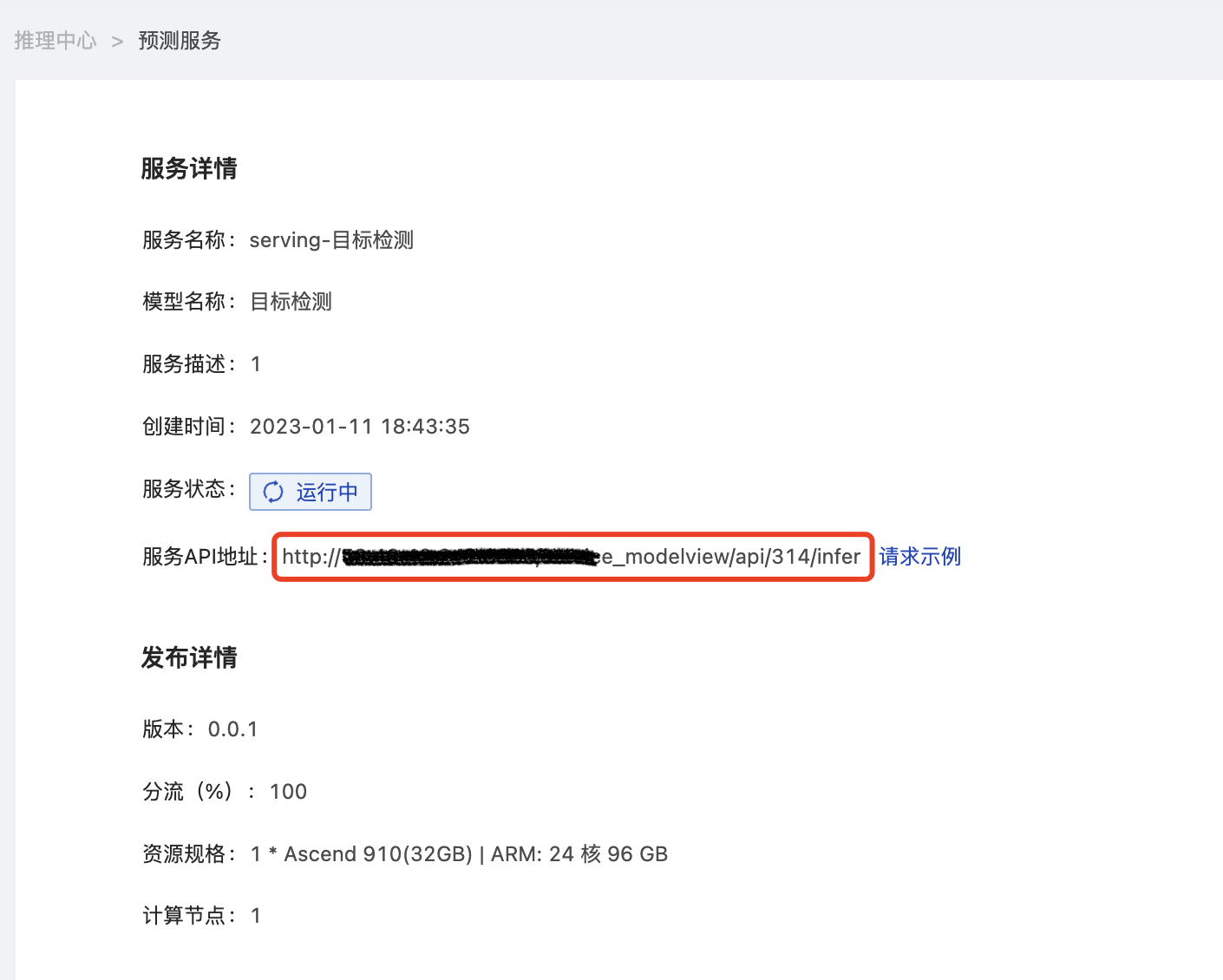
请求URL组成部分:
{domain}/service_modelview/api/{service-id}/infer/
**domain:** 网站的域名
**service-id:** 服务的ID
**predict-path:** 预测请求的path,非必填项,若模型存在内部url路径就追加到这里
**请求消息头: **
用户许可需要添加到请求头中,Authorization:eYjxxxxxxxxxxxxxxxxxxxxxxxxxGf
请求示例
使用curl请求大模型-以图生文
curl --location --request POST 'http://ai-cloud.wair.ac.cn/……' \
--header 'Authorization: {填你的用户凭证}' \
--form 'file=@"/Users/root/Desktop/COCO_train2014_000000057362.jpg"'响应示例
{
"result": {
"inference_result": ["两个女人和一只猫在飞机上"]
},
"status": 0,
"message": "success"
}使用平台推理预测实现接口请求 点击推理中心服务表单操作栏中的“预测”进入推理页
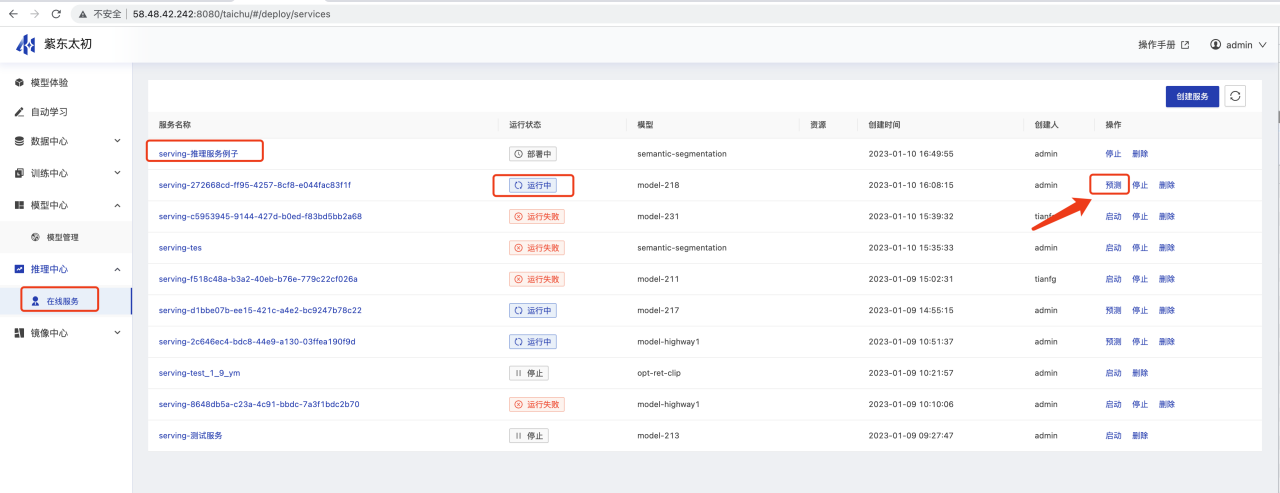
进入类似postman的API调用功能
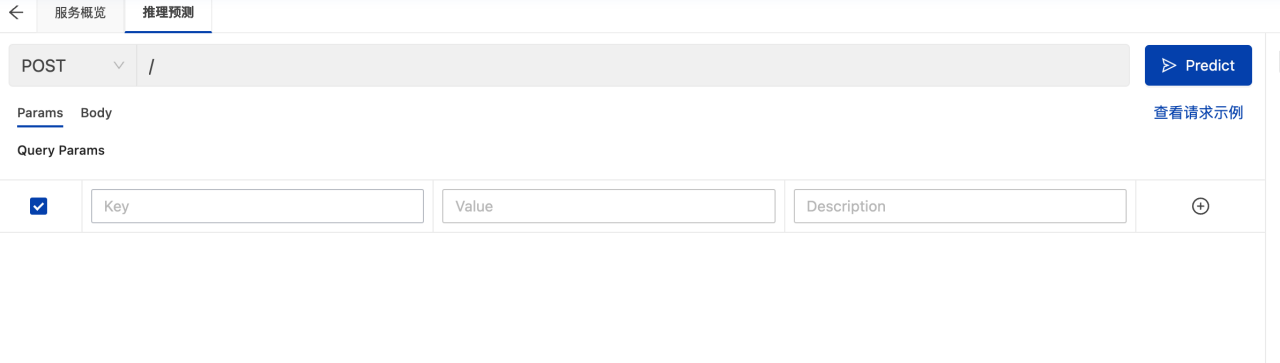
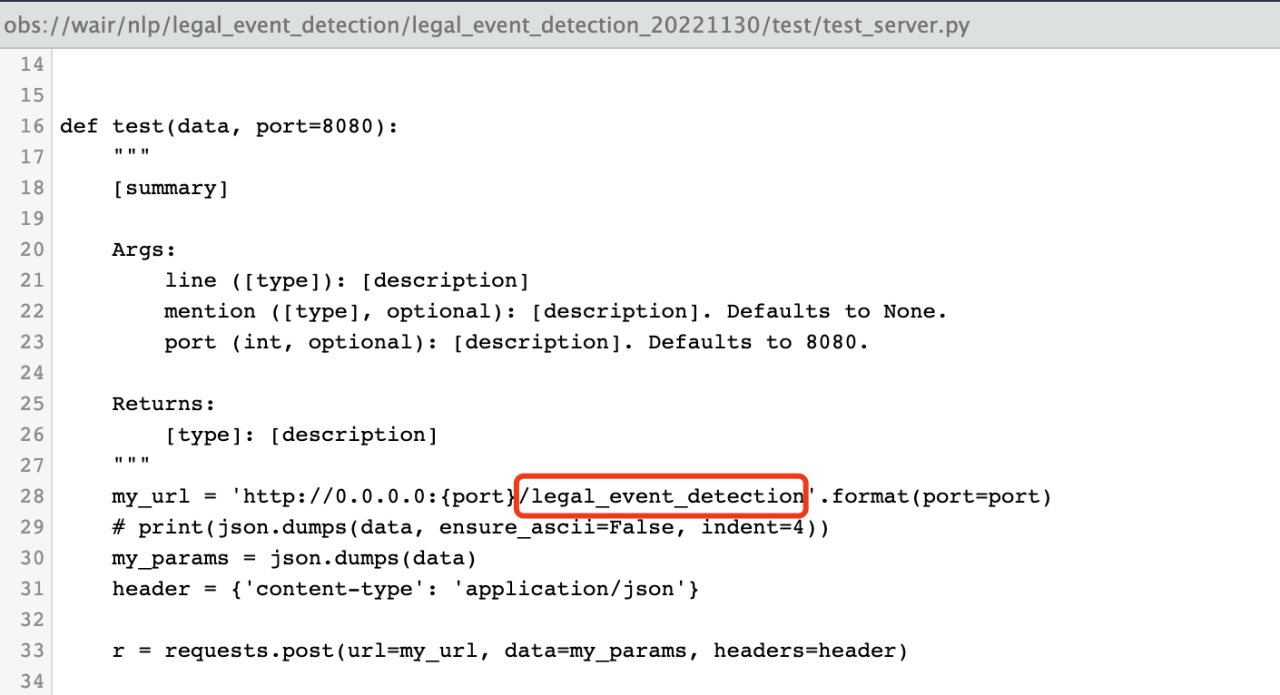
如果你的镜像中添加类似下图中的的“请求后缀”,则需要把该后缀手动添加到请求url中
镜像中心
平台提供镜像中心模块,管理训练和推理任务中使用到全部镜像,同时也支持在网络环境满足的前提下,用户导入第三方镜像仓库的模型,包括各大云厂商的容器镜像服务、私有化habor镜像仓库等。平台提供镜像构建规范,用户根据规范构建的镜像可以用于自定义训练任何和导入模型,实现对训练和推理任务运行环境的高度定制化。
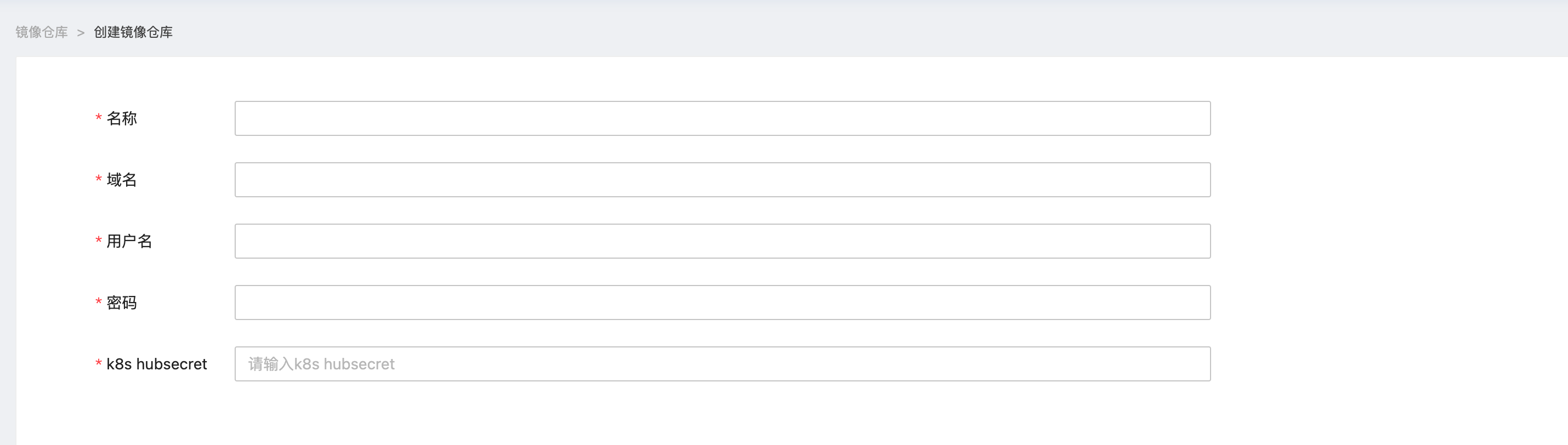
镜像仓库
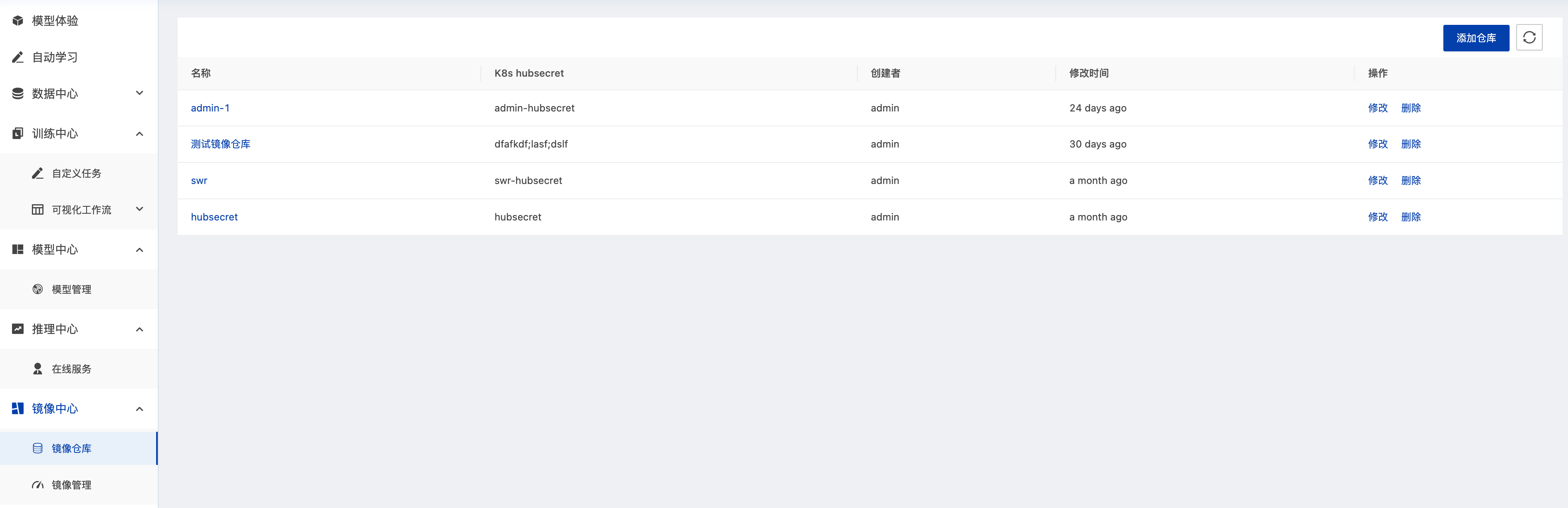
管理员可以通过创建镜像仓库,配置外部镜像仓库的域名和用户认证信息在平台注册外部容器镜像源,如dockerhub、阿里云ACR、华为云SWR、腾讯云TCR等云厂商容器镜像服务。镜像仓库创建后,普通用户即可在镜像管理页面导入来自该镜像仓库的镜像。
私有Harbor镜像仓库
平台私有部署场景下,会默认创建Harbor镜像仓库,平台内置的训练和推理镜像均托管在Harbor镜像仓库,用户也可以导入本地镜像到Harbor用户训练和推理。私有环境下镜像仓库和训练推理容器引擎在同一局域网下,这样可以大大提高拉取镜像的效率。
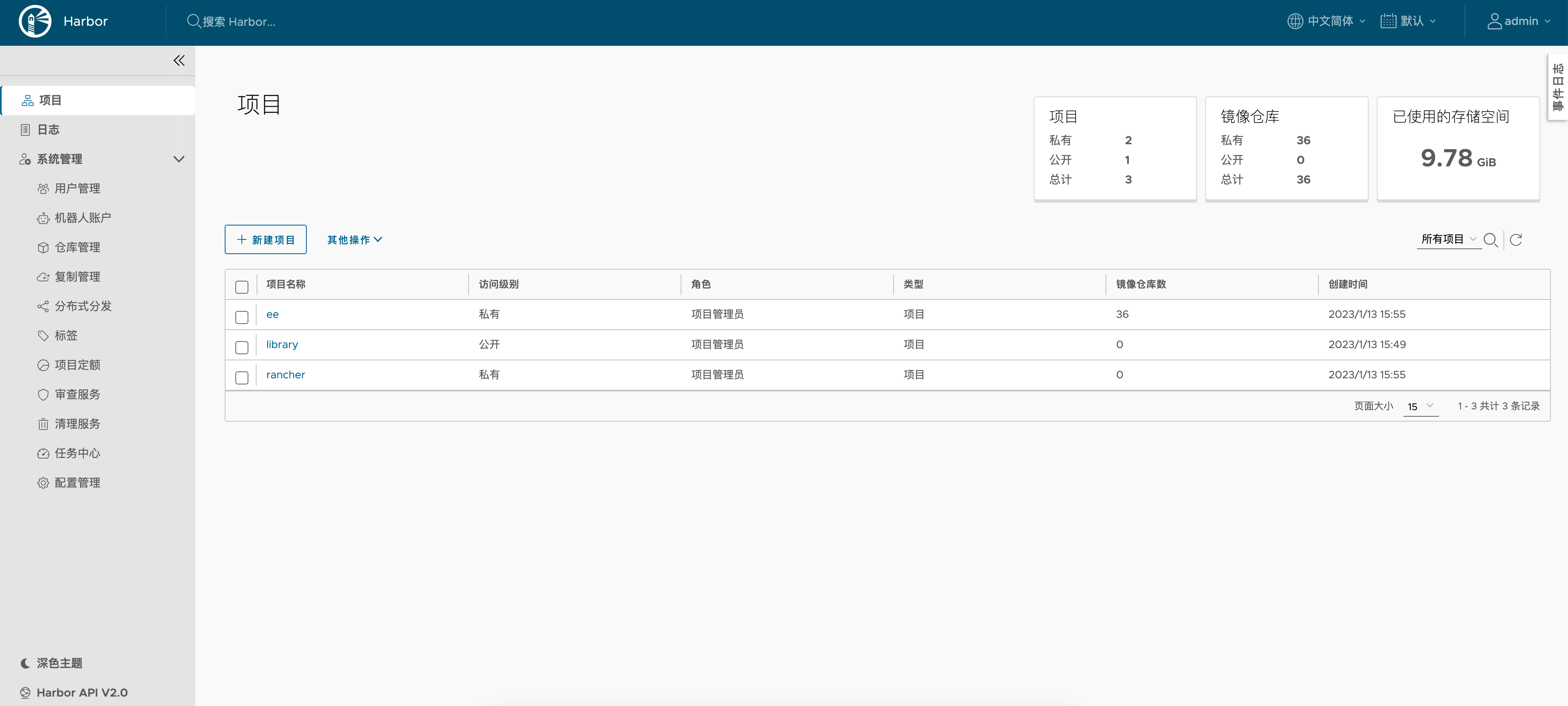
Harbor镜像仓库提供基于用户角色的访问控制,可追溯的审计日志管理,提供单独的图形化运维页面,标准化的Restful API可以集成到第三方系统。Harbor的高可用部署方式下,镜像可以在多个Registry实例中同步,Harbor会监控整个复制过程,遇到网络等错误,会自动重试,保证整体可用性。
镜像管理
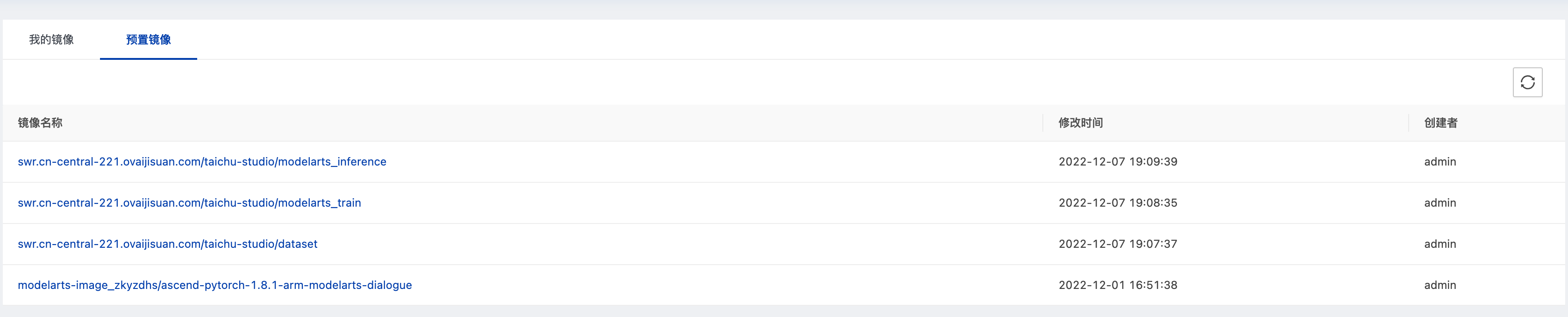
镜像管理页面开放了用户导入和管理镜像的能力。镜像管理列表分为个人镜像和预置镜像。个人镜像仅个人可见,预置镜像由平台提供,所有用户均可见且只读。
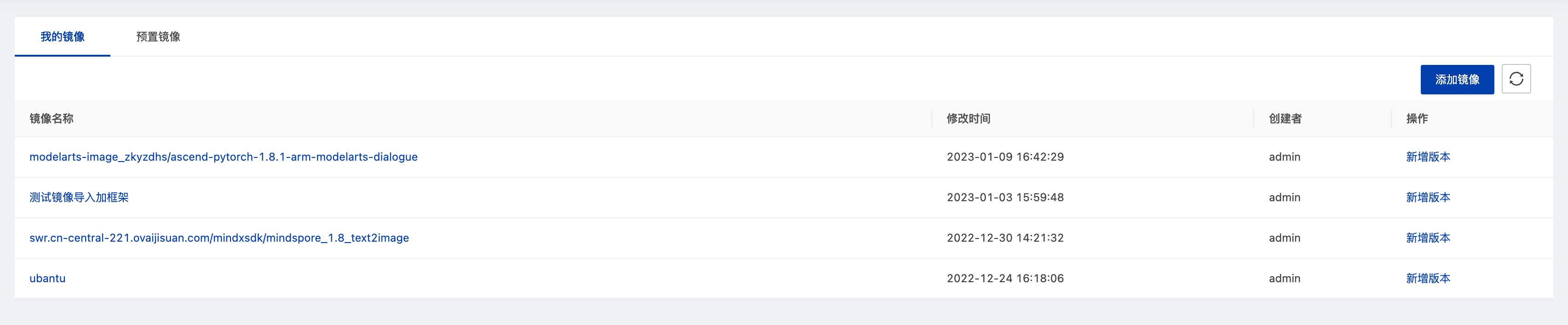
每个镜像由“镜像名:版本”命名。每个镜像都有多个版本,用户可以管理镜像版本号。

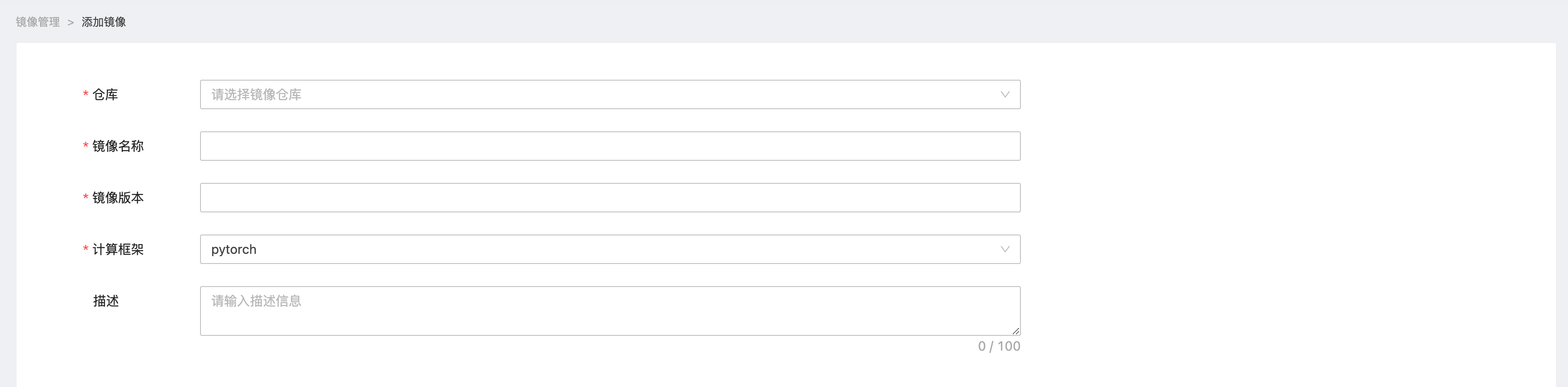
在[添加镜像]页面,用户可以在注册镜像仓库后,导入来自该镜像仓库的镜像,填写仓库、镜像名称、镜像版本、计算框架和描述信息。私有化部署场景还支持用户使用docker push 命令行工具直接推送本地镜像。
在[预置镜像]页,平台提供了内置的训练和推理镜像,在环境初始化时已添加到默认镜像仓库中,也可以由管理员在后台动态增加。以pytorch框架为例,根据pytorch框架版本、cuda或cann版本、python版本以及操作系统版本、cpu架构的不同组合,平台预置了多个pytorch基础镜像,用户在启动自定义训练任务时,根据训练代码需求可以选择对应的pytorch框架。平台持续收集来自内部和外部用户的诉求,持续补充基础镜像类别。在基础镜像环境不满足用户当前需求时,也开放了自定义镜像能力,用户可以基于平台提供的基础镜像,安装所需的第三方库,按照平台规范于本地构建新的镜像导入到平台中。
| 基础镜像名 | TAG |
|---|---|
| pytorch_1_11_0 | pytorch_1.11.0-cuda_11.3-py_3.7-ubuntu_18.04-x86_64-20221110 |
| pytorch_1_8_1 | pytorch_1.8.1-cuda_11.1-py_3.7-ubuntu_18.04-x86_64-20221111 |
| pytorch_1_8_1 | pytorch_1.8.1-cann_5.1.0-py_3.7-euler_2.8.3-aarch64-d910-20220715 |
| pytorch_1_10_1 | pytorch_1.10.1-cuda_11.1.1-py_3.8.1-centos_7-x86_64-20221115 |
镜像规范
平台提供了镜像制作规范标准和Dockerfile模版,按照规范构建的镜像可以在自定义训练和导入模型时使用。镜像规范约束了镜像命名规范、运行时环境、操作系统用户权限、输入输出目录映射、端口暴露等信息。平台在启动训练或推理任务时按照规范启动容器。
用户权限管理
用户权限管理主要包含用户管理、权限管理等内容,平台中含有数据、模型、代码等不同AI资产,面向的用户也区分数据工程师、算法工程师、运维工程是等不同身份,故而需要针对其权限做相应管理。
用户管理
注册登录
用户通过平台访问链接进入到平台登录页面,默认加载账号密码登录页。平台登录页仅需输入用户名/邮箱和密码即可登录进入系统。首次使用需注册账号,点击登录页面上“点此注册”跳转至注册页面,设置用户名、昵称、邮箱、密码后即可完成注册,点击注册后跳转至登录页面,新注册账号为体验账号,具有平台中少量功能,若需要更多功能可联系管理员获取更高权限。

新用户注册用户名、密码为必填项,昵称、邮箱等信息非必填,可后续在用户中心中做修改和绑定。若用户已有账号,在登录页面输入用户名和密码后点击“登录”按钮,即可登录平台,进入平台首页。
用户中心
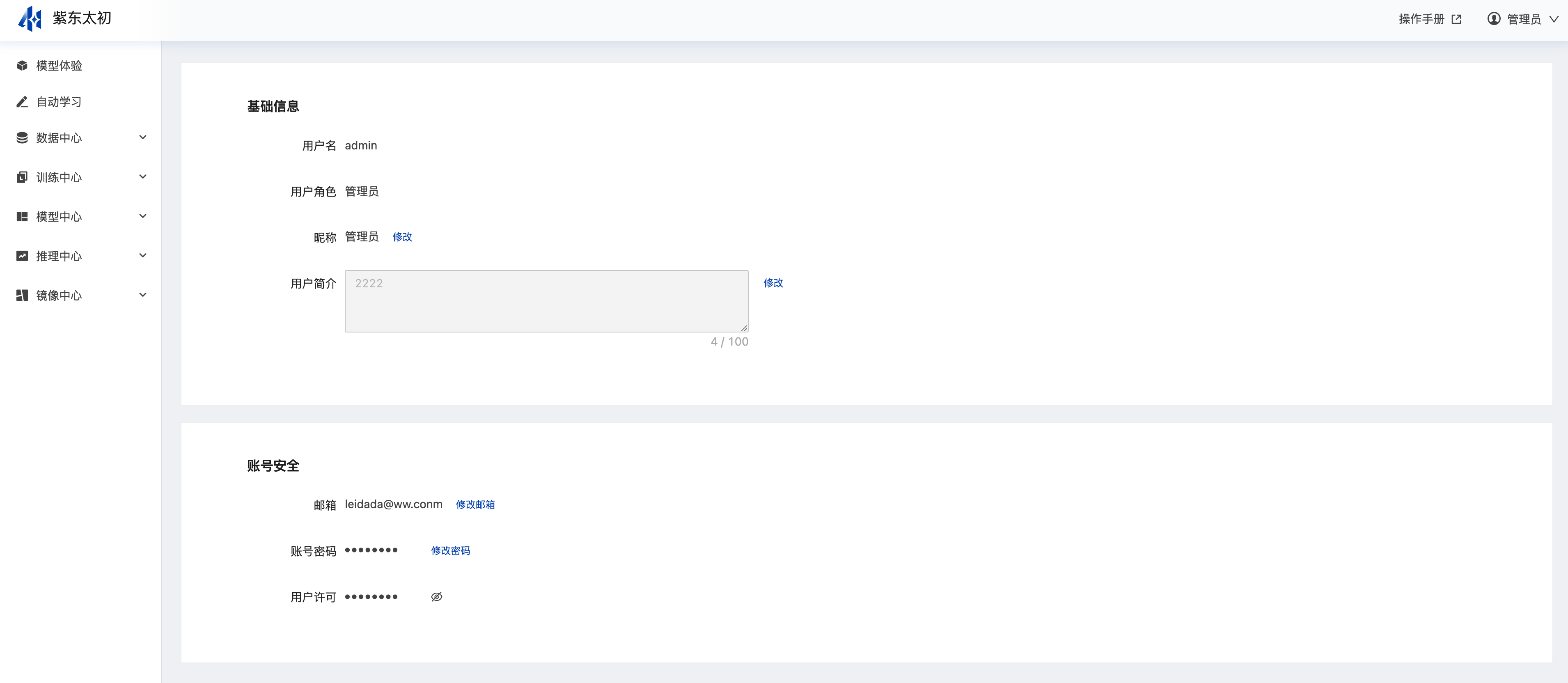
进入平台后,可点击其右上角用户名,在展开的入口中有“用户中心”和“退出登录”,点击“用户中心”进入用户中心的页面,可查看用户相关信息。

用户中心主要包含用户基础信息和账号安全信息。基础信息中展示用户名、用户角色、昵称、用户简介,昵称和用户简介支持用户在个人中心中编辑修改;账号安全中是关联邮箱、密码、用户许可,用户修改邮箱、修改密码、查看用户许可均需输入密码二次校验,无误后可做相应操作。